
Fun with Fremont Bridge Bicyclists
[This article was first published on Statistics in Seattle, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Given the title of this post and its proximity to the Solstice, you will be disappointed to know that I am not writing about naked bicyclists. I apologize for any false hope I may have instilled in you.Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
On October 11th, 2012, the city of Seattle, WA began collecting hourly counts of cyclists crossing the Fremont bridge. They have a dedicated webpage here with interactive graphs that allow you to view the counts aggregated at daily, weekly and monthly levels, as well as explore the effects of various weather on the counts. A spreadsheet here collects the hourly counts for both Northbound and Southbound traffic. The Seattle Department of Transportation (SDOT) uses this traffic counter to help evaluate their return on investment for bicycle-related facilities, but I won’t be doing anything quite as sophisticated.
My first inquiry upon seeing the separate counts for North- and Southbound cyclists is, “Gosh. I wonder what the relationship between Northbound (NB) and Southbound (SB) bike traffic is?” To explore this matter, the first thing to do is fire up R and read in the CSV file downloaded from the spreadsheet link (found above). There may be a smooth way to use the API to read in the data from URL, but I am not savvy enough for that. Implementing archaic “click and save” methodology to procure the data set, the following action happens in R:
> bikes = read.table(
+ “Fremont_Bridge_Hourly_Bicycle_Counts_by_Month_October_2012_to_present.csv”,
+ header = TRUE,
+ sep = “,”
+ )
> head(bikes)
Date Fremont.Bridge.NB Fremont.Bridge.SB
1 10/02/2012 12:00:00 AM 0 0
2 10/02/2012 01:00:00 AM 0 0
3 10/02/2012 02:00:00 AM 0 0
4 10/02/2012 03:00:00 AM 0 0
5 10/02/2012 04:00:00 AM 0 0
6 10/02/2012 05:00:00 AM 0 0
At a glance, note that we’ve got three variables: Date, Fremont.Bridge.NB, and Fremont.Bridge.SB. All those zeros in the NB and SB columns may seem a bit worrisome, but I assure you that after the first several hours we register some cyclists. In fact, take a moment to admire the data’s tail. Hopefully you will agree that something isn’t quite right.
> tail(bikes)
Date Fremont.Bridge.NB Fremont.Bridge.SB
15211 05/31/2013 06:00:00 PM 259 159
15212 05/31/2013 07:00:00 PM 122 117
15213 05/31/2013 08:00:00 PM 92 65
15214 05/31/2013 09:00:00 PM 41 43
15215 05/31/2013 10:00:00 PM 20 39
15216 05/31/2013 11:00:00 PM 20 18
If each row represents an hour, then we have 15,216/24 = 634 days of data. Considering the counts date back a mere 8 months at present, it seems as though there may be some evil twins (triplets, even!) in the file. Fortunately, R has a built-in for sorting out duplicates.
> bikes = unique(bikes)
> length(bikes$Date)
[1] 5809
Our 5809 unique hourly records equate to just over 242 days, or roughly 8 months.
Now we’re ready to do our first plot. We’ll go with NB bike counts on the horizontal axis and SB bike counts on the vertical axis.
> plot(
+ x = bikes$Fremont.Bridge.NB,
+ y = bikes$Fremont.Bridge.SB,
+ xlab = “NB Bikes in 1 Hour”,
+ ylab = “SB Bikes in 1 Hour”,
+ main = “Fremont Bridge Hourly Bike Counts”
+ )
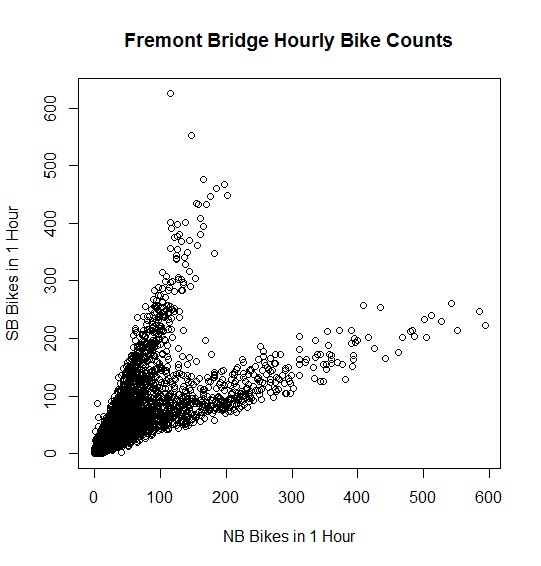
It appears that linear trends are on sale two-for-the-price-of-one. You could go as far as to say something cute here like, “The two trends are different as night and day.” If you did say that, Congratulations! Splitting the data by AM and PM times seems like a reasonable next step, since bicyclists who travel across the bridge in the morning will theoretically return later that day. This assumption won’t catch certain individuals who are just out on a short excursion, work odd hours, return across a different bridge, or take the bus for one of their crossings, etc. Despite these shortcomings, I march blindly forward in the name of science.
Identifying said AM and PM times is as easy as one, two, substring, replace.
> n = nchar(as.character(bikes$Date[1])) #all Date entries have the same length
> am.pm = substring(bikes$Date, first = n-1)
> am = which(am.pm == “AM”)
> pm = which(am.pm == “PM”)
> am.pm[am] = 0
> am.pm[pm] = 1
Now for plots that reflect this split:
> plot(
+ x = bikes$Fremont.Bridge.NB[am.pm == 0],
+ y = bikes$Fremont.Bridge.SB[am.pm == 0],
+ xlab = “NB Bikes in 1 Hour”,
+ ylab = “SB Bikes in 1 Hour”,
+ main = “Fremont Bridge AM Hourly Bike Counts”
+ )
> plot(
+ x = bikes$Fremont.Bridge.NB[am.pm == 1],
+ y = bikes$Fremont.Bridge.SB[am.pm == 1],
+ xlab = “NB Bikes in 1 Hour”,
+ ylab = “SB Bikes in 1 Hour”,
+ main = “Fremont Bridge PM Hourly Bike Counts”
+ )
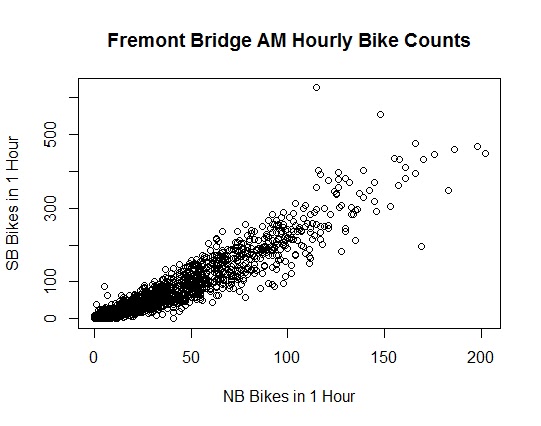
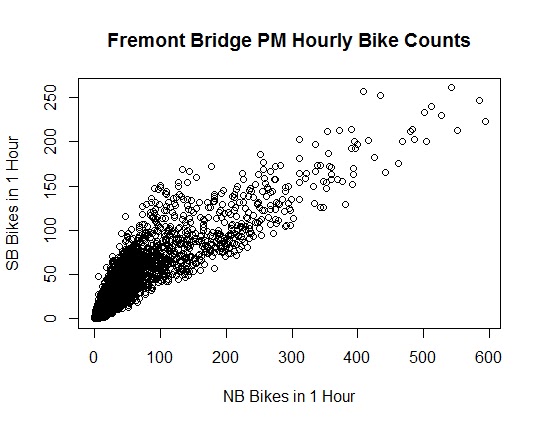
Plotting these two groups together (with the same scale) will help further untangle the two trends.
> plot(
+ x = bikes$Fremont.Bridge.NB[am.pm == 1],
+ y = bikes$Fremont.Bridge.SB[am.pm == 1],
+ xlab = “NB Bikes in 1 Hour”,
+ ylab = “SB Bikes in 1 Hour”,
+ main = “Fremont Bridge AM/PM Hourly Bike Counts”,
+ xlim = c(0,700),
+ ylim = c(0,700)
+ )
> points(
+ x = bikes$Fremont.Bridge.NB[am.pm == 0],
+ y = bikes$Fremont.Bridge.SB[am.pm == 0],
+ col = “RED”
+ )
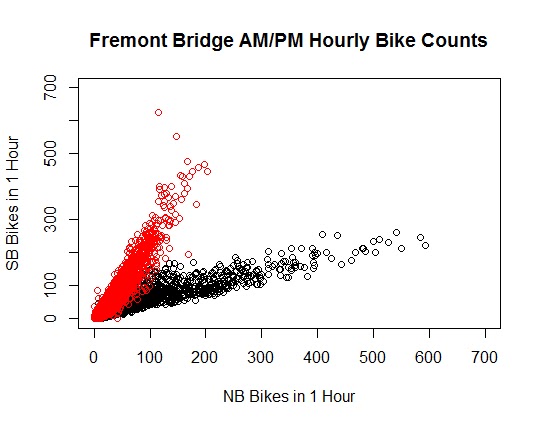
Note that the AM data points are colored red in the combined plot. The density of the points obscures the fact that there is a lot of overlap in the rectangle x: [0,100], y: [0,200].
At this point, it may be instructive to pull out the another classic line. Namely, y = x.
> points(
+ x = 0:700,
+ y = 0:700,
+ type = “l”,
+ col = “BLUE”
+ )
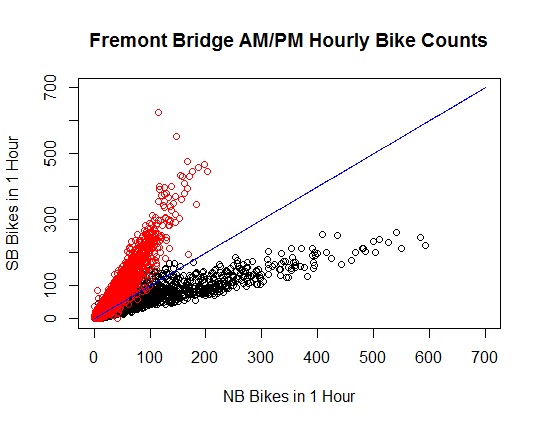
This line divides the quadrant into regions where y>x and yx are predominantly in the AM camp and those where y
As mentioned above, the split into morning and afternoon groups still leaves a region of overlapping points. Next time I’ll look at this classification more carefully and then take a look at the two trends. Based on the scatterplot, I expect the regression lines to be (nearly) inverse functions.
(Now that we’ve gotten this far, you may wonder what it is I hope to accomplish by investigating the relationship between Northbound and Southbound bike traffic in Seattle. At this point I’m not expecting anything revolutionary to come of this analysis. It has proven to be a nice way to spend a summer evening, though.)
To leave a comment for the author, please follow the link and comment on their blog: Statistics in Seattle.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.