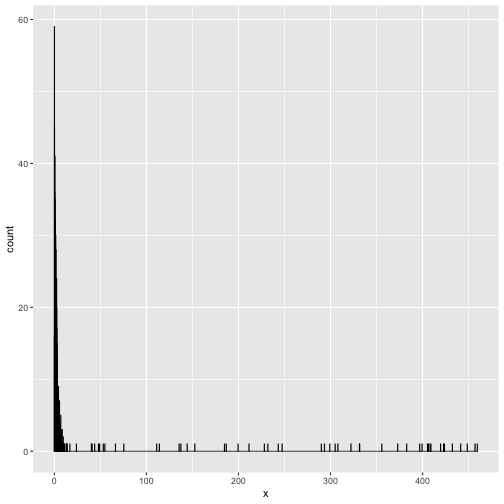
Binning Outliers in a Histogram
I guess we all use it, the good old histogram. One of the first things we are taught in Introduction to Statistics and routinely applied whenever coming across a new continuous variable. However, it easily gets messed up by outliers. Putting most of the data into a single bin or ...