
A Toy Instrumental Variable Application
[This article was first published on Econometric Sense, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
I have previously discussed instrumental variables (hereand here) from a somewhat technical standpoint, but now I’d like to present a very basic example with a toy data set that demonstrates how IV estimation works in practice. The data set below is fabricated for demonstration purposes. The idea is to develop intuition about the mechanics of IV estimators, so we won’t concern ourselves with getting the appropriate standard errors in this example.
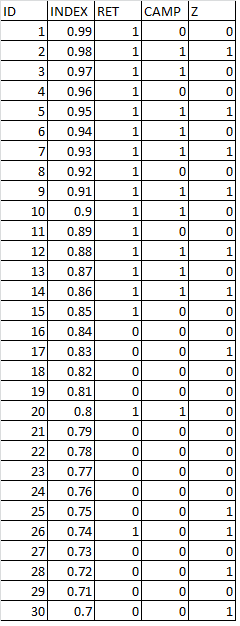
Suppose an institution has a summer camp designed to prepare high school students for their first year of college and we want to assess the impacts of the camp on 1st year retention. The most basic fixed effect regression model to assess the impact of ‘CAMP’ might be specified as follows:
Y =β0 + β1 CAMP + β2X + e (1)
Where y = first year retention (see here and herefor a thorough and apologetic discussion of linear probability models)
CAMP = an indicator for camp attendance
X = a vector of controls
Let’s simplify the discussion and exclude controls from the analysis for now. That leaves us with:
Y =β0 + β1 CAMP + e (2)
The causal effect of interest or the treatment effect of CAMP is our regression estimate β1 in the regression above. If we use the data above we get an estimate of the treatment effect β1 = .68 (i.e. CAMP attendance is associated with a 68% higher level of retention compared to students that don’t attend.) But, what if CAMP attendance is voluntary? If attendance is voluntary, then it could be that students that choose to attend also have a high propensity to succeed due to unmeasured factors (social capital, innate ability, ambition, etc.) If this is the case, our observed estimate for β1 could overstate the actual impact of CAMP on retention. If we knew about a variable that captures the omitted factors that may be related to both the choice of attending the CAMP and having a greater likelihood of retaining (like social capital, innate ability, ambition, etc.) let’s just call it INDEX, we would include it and estimate the following:
Y =β0 + β1 CAMP + β2 INDEX + e (3)
We would get the following estimate β1 =0.3636 which would be closer to the true effect of CAMP. So, omitted variable bias in equation (2) is causing us to overestimate the effect of CAMP. One way to characterize the selection bias problem is through the potential outcomes framework that I have discussed before, but this time lets characterize this problem in terms of the regression specification above. By omitting INDEX, information about INDEX is getting sucked up into the error term. When this happens, to the extent that INDEX is correlated with CAMP, CAMP becomes correlated with the error term ‘e.’ This correlation with the error term is a violation of the classical regression assumptions and leads to biased estimates of β1, which we notice with the higher value (.68) that we get above when we omit INDEX. (For more technical terminology than ‘getting sucked up into the error term’ see my discussion about unobserved heterogeneity and endogeneity).
So the question becomes, how do we tease out the true effects of CAMP, when we have this omitted variable INDEX that we can’t possibly measure that is biasing our estimate? Techniques using what are referred to as instrumental variables will help us do this.
Let’s suppose we find some variable we hadn’t thought of called Z. Suppose that Z tends to be correlated with our variable of interest CAMP. For the most part, where Z = 1, CAMP = 1. But we also notice (or argue) that Z tends to be unrelated to all of those omitted factors like innate ability and ambition that comprise the variable INDEX that we wish we had. The technique of instrumental variables looks at changes in a variable like Z, and relates them to changes in our variable of interest CAMP, and then relates those changes to the outcome of interest, retention. Since Z is unrelated to INDEX, then those changes in CAMP that are related to Z are likely to be less correlated with INDEX (and hence less correlated with the error term ‘e’). A very non-technical way to think about this is that we are taking Z and going through CAMP to get to Y, and bringing with us only those aspects of CAMP that are unrelated to INDEX. Z is like a filter that picks up only the variation in CAMP (what we may refer to as ‘quasi-experimental variation) that we are interested in and filters out the noise from INDEX. Z is technically related to Y only through CAMP.
Z →CAMP→Y (4)
If we can do this, then our estimate of the effects of CAMP on Y will be unbiased by the omitted effects of INDEX. So how do we do this in practice?
We can do this through a series of regressions. To relate changes in Z to changes in CAMP we estimate:
CAMP = β0 + β1 Z + e (5)
Notice in (5), β1 only picks up the variation in Z that is related to CAMP and leaves all of the variation in CAMP related to INDEX in the residual term. You can think of this as the filtering process. Then, to relate changes in Z to changes in our target Y we estimate:
Y = β0 +β2 Z + e (6)
Our instrumental variable estimator then becomes:
βIV = β2 / β1 or (Z’Z)-1Z’Y / (Z’Z)-1Z’CAMP or COV(Y,Z)/COV(CAMP,Z) (7)
The last term in (7) indicates that βIVrepresents the proportion of total variation in CAMP that is related to our ‘instrument’ Z that is also related to Y. Or, the total proportion of variation in CAMP unrelated to INDEX that is related to Y. Or, the total proportion of ‘quasi-experimental variation’ in CAMP related to Y. Regardless of how you want to interpret βIV, we can see that it teases out only that variation in CAMP that is unrelated to INDEX and relates it to Y giving us an estimate for the treatment effect of CAMP that is less biased than the standard regression like (2). In fact if we compute βIV as in (7), we get βIV= .3898. Notice this is much closer to what we think is the true estimate of β1that we would get from regression (3) if we had information about INDEX and could include it in the model specification.
Application in Higher Education
In their paper ‘Using Instrumental Variables to Account for Selection Effects in Research on First Year Programs’ Pike, Hansen and Lin account for self- selection using instrumental variables to get an unbiased measure the impact of first year programs. As I discussed this paper previously, in a normal multivariable regression specification, after including various controls, they find a positive significant relationship between first year programs and student success (measured by GPA). However, by including the instruments in the regression (correcting for selection bias) this relationship goes away. In the paper they state:
“If, as the results of this study suggest, traditional evaluation methods can overstate (either positively or negatively) the magnitude of program effects in the face of self-selection, then evaluation research may be providing decision makers with inaccurate information. In addition to providing an incomplete accounting for external audiences, inaccurate information about program effectiveness can lead to the misallocation of scarce institutional resources.”
Addendum: Estimating IV via 2SLS
The example above derives βIV as discussed in a previous post. But, you can also get βIV by substitution via two stage least squares (as discussedhere):
CAMP = β0 + β1 Z + e (5)
RET = β0 + βIV CAMPest+ e (8)
As discussed above, the first regression gets only the variation in CAMP related to Z, and leaves all of the variation in CAMP related to INDEX in the residual term. As Angrist and Pischke state, the second regression estimates βIV and retains only the quasi-experimental variation in CAMP generated by the instrument Z. As discussed in their book Mostly Harmless Econometrics, most IV estimates are derived using packages like SAS, STATA, or R vs. explicit implementation of the methods illustrated above. Caution should be used to derive the correct standard errors, which are not the ones you will get in the intermediate results from any of the regressions depicted above.
References:
Angrist and Pischke, Mostly Harmless Econometrics, 2009
Angrist and Pischke, Mostly Harmless Econometrics, 2009
Identification of Causal Effects Using Instrumental Variables
Joshua D. Angrist, Guido W. Imbens and Donald B. Rubin
Journal of the American Statistical Association , Vol. 91, No. 434 (Jun., 1996), pp. 444-455
Using Instrumental Variables to Account for Selection Effects in Research on First-Year Programs
Gary R. Pike, Michele J. Hansen and Ching-Hui Lin
Research in Higher Education
Volume 52, Number 2, 194-214
Using Instrumental Variables to Account for Selection Effects in Research on First-Year Programs
Gary R. Pike, Michele J. Hansen and Ching-Hui Lin
Research in Higher Education
Volume 52, Number 2, 194-214
R Code for the Examples Above:
# ------------------------------------------------------------------
# | PROGRAM NAME: R_INSTRUMENTAL_VAR
# | DATE:6/17/13
# | CREATED BY: MATT BOGARD
# | PROJECT FILE: P:\BLOG\STATISTICS
# |----------------------------------------------------------------
# | PURPOSE: BASIC EXAMPLE OF IV
# |
# |
# |------------------------------------------------------------------
setwd('P:\\BLOG\\STATISTICS')
CAMP <- read.table("mplan.txt", header =TRUE)
summary(lm(CAMP$RET~CAMP$CAMP + CAMP$INDEX)) # true B1
summary(lm(CAMP$RET~CAMP$CAMP)) # biased OLS estimate for B1
cor(CAMP$CAMP,CAMP$Z) # is the treatment correlated with the instrument?
cor(CAMP$INDEX,CAMP$Z) # is the instrument correlated with the omitted variable
cov(CAMP$RET,CAMP$Z)/var(CAMP$Z) # y = bZ
cov(CAMP$CAMP,CAMP$Z)/var(CAMP$Z) # x = bZ
# empirical estiamte of B1(IV)
(cov(CAMP$RET,CAMP$Z)/var(CAMP$Z))/(cov(CAMP$CAMP,CAMP$Z)/var(CAMP$Z)) # B1(IV)
# or
(cov(CAMP$RET,CAMP$Z))/(cov(CAMP$CAMP,CAMP$Z))
# two stage regression with IV substitution
# x^ = b1Z
CAMP_IV <- predict(lm(CAMP$CAMP~CAMP$Z)) # produce a vector of estimates for x
# y = b1 x^
lm(CAMP$RET~CAMP_IV)
To leave a comment for the author, please follow the link and comment on their blog: Econometric Sense.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.