
5 Ways to Subset a Data Frame in R
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Often, when you’re working with a large data set, you will only be interested in a small portion of it for your particular analysis. So, how do you sort through all the extraneous variables and observations and extract only those you need? Well, R has several ways of doing this in a process it calls “subsetting.”
The most basic way of subsetting a data frame in R is by using square brackets such that in:
example[x,y]
example is the data frame we want to subset, ‘x’ consists of the rows we want returned, and ‘y’ consists of the columns we want returned. Let’s pull some data from the web and see how this is done on a real data set.
### import education expenditure data set and assign column names
education <- read.csv("https://vincentarelbundock.github.io/Rdatasets/csv/robustbase/education.csv", stringsAsFactors = FALSE)
colnames(education) <- c("X","State","Region","Urban.Population","Per.Capita.Income","Minor.Population","Education.Expenditures")
View(education)
Here’s what the first part of our data set looks like after I’ve imported the data and appropriately named its columns.

Now, let’s suppose we oversee the Midwestern division of schools and that we are charged with calculating how much money was spent per child for each state in our region. We would need three variables: State, Minor.Population, and Education.Expenditures. However, we would only need the observations from the rows that correspond to Region 2. Here’s the basic way to retrieve that data in R:
ed_exp1 <- education[c(10:21),c(2,6:7)]
To create the new data frame ‘ed_exp1,’ we subsetted the ‘education’ data frame by extracting rows 10-21, and columns 2, 6, and 7. Pretty simple, right?
Another way to subset the data frame with brackets is by omitting row and column references. Take a look at this code:
ed_exp2 <- education[-c(1:9,22:50),-c(1,3:5)]
Here, instead of subsetting the rows and columns we wanted returned, we subsetted the rows and columns we did not want returned and then omitted them with the “-” sign. If we now call ed_exp1 and ed_exp2, we can see that both data frames return the same subset of the original education data frame.
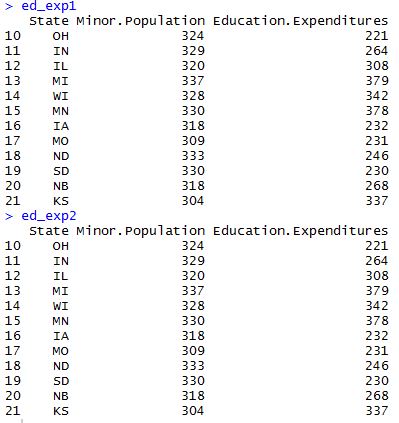
Now, these basic ways of subsetting a data frame in R can become tedious with large data sets. You have to know the exact column and row references you want to extract. It’s pretty easy with 7 columns and 50 rows, but what if you have 70 columns and 5,000 rows? How do you find which columns and rows you need in that case? Here’s another way to subset a data frame in R…
ed_exp3 <- education[which(education$Region == 2),names(education) %in% c("State","Minor.Population","Education.Expenditures")]
Now, we have a few things going on here. First, we are using the same basic bracketing technique to subset the education data frame as we did with the first two examples. This time, however, we are extracting the rows we need by using the which() function. This function returns the indices where the Region column of the education data from is 2. That gives us the rows we need. We retrieve the columns of the subset by using the %in% operator on the names of the education data frame.
Now, you may look at this line of code and think that it’s too complicated. There’s got to be an easier way to do that. Well, you would be right. There is another basic function in R that allows us to subset a data frame without knowing the row and column references. The name? You guessed it: subset().
ed_exp4 <- subset(education, Region == 2, select = c("State","Minor.Population","Education.Expenditures"))
The subset() function takes 3 arguments: the data frame you want subsetted, the rows corresponding to the condition by which you want it subsetted, and the columns you want returned. In our case, we take a subset of education where “Region” is equal to 2 and then we select the “State,” “Minor.Population,” and “Education.Expenditure” columns.
When we subset the education data frame with either of the two aforementioned methods, we get the same result as we did with the first two methods:

Now, there’s just one more method to share with you. This last method, once you’ve learned it well, will probably be the most useful for you in manipulating data. Let’s take a look at the code and then we’ll go over it…
install.packages("dplyr")
library(dplyr)
ed_exp5 <- select(filter(education, Region == 2),c(State,Minor.Population:Education.Expenditures))
This last method is not part of the basic R environment. To use it, you’ve got to install and download the dplyr package. If you’re going to be working with data in R, though, this is a package you will definitely want. It is among the most downloaded packages in the R environment and, as you start using it, you’ll quickly see why.
So, once we’ve downloaded dplyr, we create a new data frame by using two different functions from this package:
- filter: the first argument is the data frame; the second argument is the condition by which we want it subsetted. The result is the entire data frame with only the rows we wanted.
- select: the first argument is the data frame; the second argument is the names of the columns we want selected from it. We don’t have to use the names() function, and we don’t even have to use quotation marks. We simply list the column names as objects.
In this example, we’ve wrapped the filter function in the selection function to return our data frame. In other words, we’ve first taken the rows where the Region is 2 as a subset. Then, we took the columns we wanted from only those rows. The result gives us a data frame consisting of the data we need for our 12 states of interest:
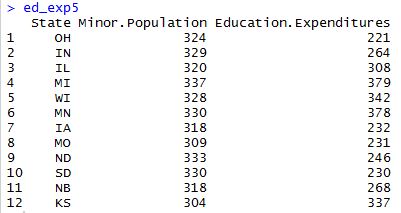
So, to recap, here are 5 ways we can subset a data frame in R:
- Subset using brackets by extracting the rows and columns we want
- Subset using brackets by omitting the rows and columns we don’t want
- Subset using brackets in combination with the which() function and the %in% operator
- Subset using the subset() function
- Subset using the filter() and select() functions from the dplyr package
That’s it! Happy subsetting!

R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.