
Iterating some sample data
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
I’m teaching my Modern Plain Text Computing course this semester and so I’m on the lookout for small examples that I can use to show some of the small techniques we regularly use when working with tables of data. One of those is just coming up with some sample data to illustrate something else, like how to draw a plot or fit a model or what have you. This is partly what the stock datasets that come bundled with packages are for, like the venerable mtcars or the more recent palmerpenguins. Sometimes, though, you end up quickly making up an example yourself. This can be a good way to practice stuff that computers are good at, like doing things repeatedly.
This happened the other day in response to a question about visualizing some evaluation data. The task goes like this. You are testing a bunch of different LLMs. Say, fifteen of them. You have trained them to return Yes/No answers when they look at repeated samples of some test data. Let’s say each LLM is asked a hundred questions. You have also had an expert person look at the same hundred questions and give you their Yes/No answers. The person’s answers are the ground truth. You want to know how the LLM performs against them. So for each LLM you have a two-by-two table showing counts or rates of true positives, true negatives, false positives, and false negatives. This is called a “confusion matrix”. You want to visualize LLM performance for all the LLMs. An additional wrinkle is that, from the point of view of your business, responses are variably costly. Correct answers (true positives or true negatives) cost one unit. Then, say, a False Negative costs two units and a False Positive is worst, costing four units.
The questioner just wanted some thoughts on what sort of graph to draw. You can of course just picture what the data would look like and figure out which of your many stock datasets has an analogous structure. Or you’d just sketch out an answer. In this case, even though they have problems in general, a kind of stacked bar chart (but flipped on its side) might work OK. But half the fun (for some values of “fun”) is generating data that looks like this. And as I said, I’m on the lookout for iteration examples, somewhere I can repeatedly do something and gather the results into a nice table.
When we want to repeatedly do something, we first solve the base case and then we generalize it by putting in some sort of placeholder and use an engine that can iterate over an index of values, feeding each one to the placeholder. In imperative languages you might use a counter and a for loop. In a functional approach you repeatedly map or apply some function.
We’ve got a hundred questions and fifteen llms. We imagine that the LLMs can range in accuracy from 40 percent to 99 percent in one percent steps.
1 2 3 4 5 |
set.seed(100125) # so we get the same 'random' results each time n_runs <- 100 n_llms <- 15 accuracy_range <- seq(0.4, 0.99, 0.01) |
Our baseline is n_runs human answers with some given distribution of Yes/No answers. Let’s say 80% No, 20% Yes. It doesn’t matter what they are; the person is the ground truth. We sample with replacement a hundred times from “N” or “Y” at that probability.
1 2 3 4 5 6 7 |
human_evals <- sample(c("N", "Y"), n_runs, replace = TRUE, prob = c(0.8, 0.20))
human_evals
#> [1] "N" "N" "N" "Y" "N" "Y" "N" "N" "N" "Y" "N" "Y" "N" "N" "N" "Y" "N" "N" "N" "N" "N" "N" "N" "N" "Y" "N" "Y" "N" "N" "N" "Y" "N" "N"
#> [34] "N" "N" "N" "N" "N" "N" "Y" "N" "N" "N" "Y" "N" "N" "Y" "N" "Y" "N" "N" "N" "N" "N" "N" "N" "N" "N" "N" "N" "N" "Y" "N" "N" "N" "N"
#> [67] "N" "N" "N" "N" "N" "N" "N" "N" "N" "Y" "N" "Y" "N" "N" "Y" "Y" "N" "Y" "Y" "N" "Y" "N" "N" "N" "N" "N" "N" "N" "N" "N" "N" "N" "N"
#> [100] "N" |
For each of our fifteen LLM what we want to do is generate a string of its one hundred Y/N answers in the same way, but with its particular idiosyncratic distribution of Ys and Ns, and then evaluate it against the human baseline. And we’d like to gather all the answers into a single data frame so we can keep everything tidy.
Our evaluation function looks like this:
1 2 3 4 5 6 7 8 |
eval_llm <- function(llm_evals, human_eval) {
case_when(
llm_evals == "Y" & human_eval == "Y" ~ "True Positive",
llm_evals == "Y" & human_eval == "N" ~ "False Positive",
llm_evals == "N" & human_eval == "Y" ~ "False Negative",
llm_evals == "N" & human_eval == "N" ~ "True Negative",
)
} |
We generate a string of responses for an imaginary LLM just like we did for the imaginary person. The single case would look like this:
1 |
llm_01 <- sample(c("N", "Y"), n_runs, replace = TRUE, prob = c(0.7, 0.3)) |
But we want to do this fifteen times, with varying values for prob and also we want to put each LLM in its own column in a data frame. So we replace the values with variables. First we generate a vector of LLM names. We use str_pad to get sortable numbers with a leading zero.
1 2 3 4 |
llm_id <- paste("LLM", str_pad(1:n_llms, width = 2, pad = "0"), sep = "_")
llm_id
#> [1] "LLM_01" "LLM_02" "LLM_03" "LLM_04" "LLM_05" "LLM_06" "LLM_07" "LLM_08" "LLM_09" "LLM_10" "LLM_11" "LLM_12" "LLM_13" "LLM_14" "LLM_15" |
Now we’re going to create a little table of LLM parameters. We already created a vector of probabilities for the LLMs, accuracy_range. We’ll sample from that to get fifteen values. The number of runs is fixed at a hundred. R’s naturally vectorized way of working will take care of the table getting filled in properly.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
llm_df <- tibble( llm_id = llm_id, p_yes = sample(accuracy_range, n_llms), p_no = 1 - p_yes, n = n_runs ) llm_df #> # A tibble: 15 × 4 #> llm_id p_yes p_no n #> <chr> <dbl> <dbl> <dbl> #> 1 LLM_01 0.49 0.51 100 #> 2 LLM_02 0.91 0.09 100 #> 3 LLM_03 0.46 0.54 100 #> 4 LLM_04 0.88 0.12 100 #> 5 LLM_05 0.45 0.55 100 #> 6 LLM_06 0.52 0.48 100 #> 7 LLM_07 0.55 0.45 100 #> 8 LLM_08 0.6 0.4 100 #> 9 LLM_09 0.65 0.35 100 #> 10 LLM_10 0.61 0.39 100 #> 11 LLM_11 0.93 0.0700 100 #> 12 LLM_12 0.53 0.47 100 #> 13 LLM_13 0.94 0.0600 100 #> 14 LLM_14 0.69 0.31 100 #> 15 LLM_15 0.92 0.0800 100 |
Next we need a function that can accept each row as a series of arguments and use it to generate a vector of LLM answers:
1 2 3 4 5 |
run_llm <- function(llm_id, p_yes, p_no, n_runs) {
tibble(
{{ llm_id }} := sample(c("N", "Y"), n_runs, replace = TRUE, prob = c(p_yes, p_no))
)
} |
This function returns a data frame that has one column and a hundred rows of Y/N answers sampled at a given probability of yes and no answers. There are two tricks. The first is, we want the name of the column to be the same as the llm_id. To do this we have to quasi-quote the llm_id argument. This is what the {{ }} around llm_id does inside the function. It lets us use the value of llm_id as a symbol that’ll name the column. Normally when using tibble() to make a data frame we create a column with col_name = vector_of_values. We did that when we made llm_df a minute ago. But because we’re doing this on the left side of a naming operation, we can’t use =, either. We have to assign the name’s contents using the excellently-named walrus operator, :=.
Now we’re ready to go. We feed the llm_df table a row at a time to the run_llm function by using one of purrr’s map functions. Specifically, we use pmap, which takes a list of function arguments and hands them to a function.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
llm_results <- map(llm_outputs, \(x) eval_llm(x, human_evals)) |>
bind_cols() |>
mutate(
across(everything(), as.factor))
llm_results
#> # A tibble: 100 × 15
#> LLM_01 LLM_02 LLM_03 LLM_04 LLM_05 LLM_06 LLM_07 LLM_08 LLM_09 LLM_10 LLM_11 LLM_12 LLM_13 LLM_14 LLM_15
#> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <fct>
#> 1 False Positive False Positive False Positive True Negative True N… True … False… True … True … True … True … True … False… True … True …
#> 2 True Positive False Negative False Negative False Negative False … False… False… True … False… False… False… False… False… True … False…
#> 3 False Negative True Positive False Negative False Negative False … False… True … False… False… False… False… False… False… True … False…
#> 4 False Positive False Positive True Negative True Negative True N… True … True … True … True … True … True … True … True … False… True …
#> 5 True Negative True Negative True Negative True Negative False … False… False… True … False… True … True … True … True … False… False…
#> 6 False Positive True Negative True Negative False Positive False … False… True … False… False… True … True … True … False… True … True …
#> 7 False Positive False Positive True Negative False Positive True N… True … False… False… False… True … True … True … True … True … True …
#> 8 False Negative True Positive False Negative False Negative True P… False… False… False… False… False… False… False… False… True … True …
#> 9 False Negative True Positive False Negative True Positive True P… False… True … False… True … False… False… False… False… False… False…
#> 10 True Negative True Negative False Positive True Negative True N… True … False… False… False… True … True … True … False… False… False…
#> # ℹ 90 more rows |
We write as.list(llm_df) because pmap() wants its series of arguments as a list. (A data frame is just a list where each list element—each column—is the same length, by the way.) It returns a list of fifteen LLM runs, which we then bind by column back into a data frame. Nice. At the end there I deliberately convert all these character vectors to factors for a reason I’ll get to momentarily.
Now we can evaluate all these LLMs against our human_evals vector in the same way, by mapping or applying the eval_llm() function we wrote earlier. This time we can just use regular map() because there’s only one varying argument, the LLM id. We take the llm_outputs data frame and use an anonymous or lambda function, \(x\) to say “pass each column to eval_llm() along with the non-varying human_evals vector”. (You could write this without a lambda, too, but I find this syntax more consistent.)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
llm_results <- map(llm_outputs, \(x) eval_llm(x, human_evals)) |>
bind_cols() |>
mutate(
across(everything(), as.factor))
llm_results
#> # A tibble: 100 × 15
#> LLM_01 LLM_02 LLM_03 LLM_04 LLM_05 LLM_06 LLM_07 LLM_08 LLM_09 LLM_10 LLM_11 LLM_12 LLM_13 LLM_14 LLM_15
#> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <fct>
#> 1 False Positive False Positive False Positive True Negative True N… True … False… True … True … True … True … True … False… True … True …
#> 2 True Positive False Negative False Negative False Negative False … False… False… True … False… False… False… False… False… True … False…
#> 3 False Negative True Positive False Negative False Negative False … False… True … False… False… False… False… False… False… True … False…
#> 4 False Positive False Positive True Negative True Negative True N… True … True … True … True … True … True … True … True … False… True …
#> 5 True Negative True Negative True Negative True Negative False … False… False… True … False… True … True … True … True … False… False…
#> 6 False Positive True Negative True Negative False Positive False … False… True … False… False… True … True … True … False… True … True …
#> 7 False Positive False Positive True Negative False Positive True N… True … False… False… False… True … True … True … True … True … True …
#> 8 False Negative True Positive False Negative False Negative True P… False… False… False… False… False… False… False… False… True … True …
#> 9 False Negative True Positive False Negative True Positive True P… False… True … False… True … False… False… False… False… False… False…
#> 10 True Negative True Negative False Positive True Negative True N… True … False… False… False… True … True … True … False… False… False…
#> # ℹ 90 more rows |
Now we’re done; each LLM has been compared to the ground truth and we can construct a confusion matrix of counts for each column if we want. Let’s summarize the table, adding a cost code for the bad answers:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
llm_summary <- llm_results |>
pivot_longer(everything()) |>
group_by(name, value, .drop = FALSE) |>
tally() |>
mutate(prop = n/sum(n),
cost = case_when(
value %in% c("True Positive", "True Negative") ~ 1L,
value == "False Negative" ~ 2L,
value == "False Positive" ~ 4L)
)
llm_summary
#> # A tibble: 60 × 5
#> # Groups: name [15]
#> name value n prop cost
#> <chr> <fct> <int> <dbl> <int>
#> 1 LLM_01 False Negative 18 0.18 2
#> 2 LLM_01 False Positive 19 0.19 4
#> 3 LLM_01 True Negative 59 0.59 1
#> 4 LLM_01 True Positive 4 0.04 1
#> 5 LLM_02 False Negative 16 0.16 2
#> 6 LLM_02 False Positive 22 0.22 4
#> 7 LLM_02 True Negative 56 0.56 1
#> 8 LLM_02 True Positive 6 0.06 1
#> 9 LLM_03 False Negative 19 0.19 2
#> 10 LLM_03 False Positive 17 0.17 4
#> # ℹ 50 more rows |
Now, why did I convert the LLM results table from characters to factors? It’s because of how dplyr handles table summaries. It’s possible that an LLM could get e.g. all True Positive answers, leaving the other three cells in its confusion matrix empty, i.e. zero counts. But, by default, when tallying counts of character vectors, dplyr drops empty groups. For some kinds of tallying that’s fine, but for others you definitely want to keep a tally of zero-count cells. With factors we can tell dplyr explicitly not to drop them. (You can also set this option permanently for a given analysis.) The alternative is to ungroup and complete the table once its been created, explicitly adding back in the implicitly missing zero-count rows.
Now that we have our table, we can graph it. As I said at the beginning, stacked bar charts are not great in many cases but it’s fine here, and better than trying to repeatedly draw fifteen confusion matrices. We don’t really care about the difference between true positives and true negatives anyway. We take the results table, merge it with the summary table, and draw our graph ordering the LLMs by perforance weighted by average cost. We use a manual four-value color palette to distinguish the broadly bad from the broadly good answers.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
llm_results |>
pivot_longer(everything()) |>
left_join(llm_summary) |>
mutate(name = str_replace(name, "_", " ")) |>
ggplot(aes(y = reorder(name, cost), fill = value)) +
geom_bar(color = "white", linewidth = 0.25) +
scale_fill_manual(values = fourval_pal) +
guides(fill = guide_legend(reverse = TRUE,
title.position = "top",
label.position = "bottom",
keywidth = 3,
nrow = 1)) +
labs(x = "N Questions", y = NULL,
fill = "Compared with a Person the LLM Yielded ...",
title = "LLM Performance Relative to Human Baseline",
subtitle = "False Positives are twice as costly as False Negatives") +
theme_minimal() +
theme(legend.position = "top") |
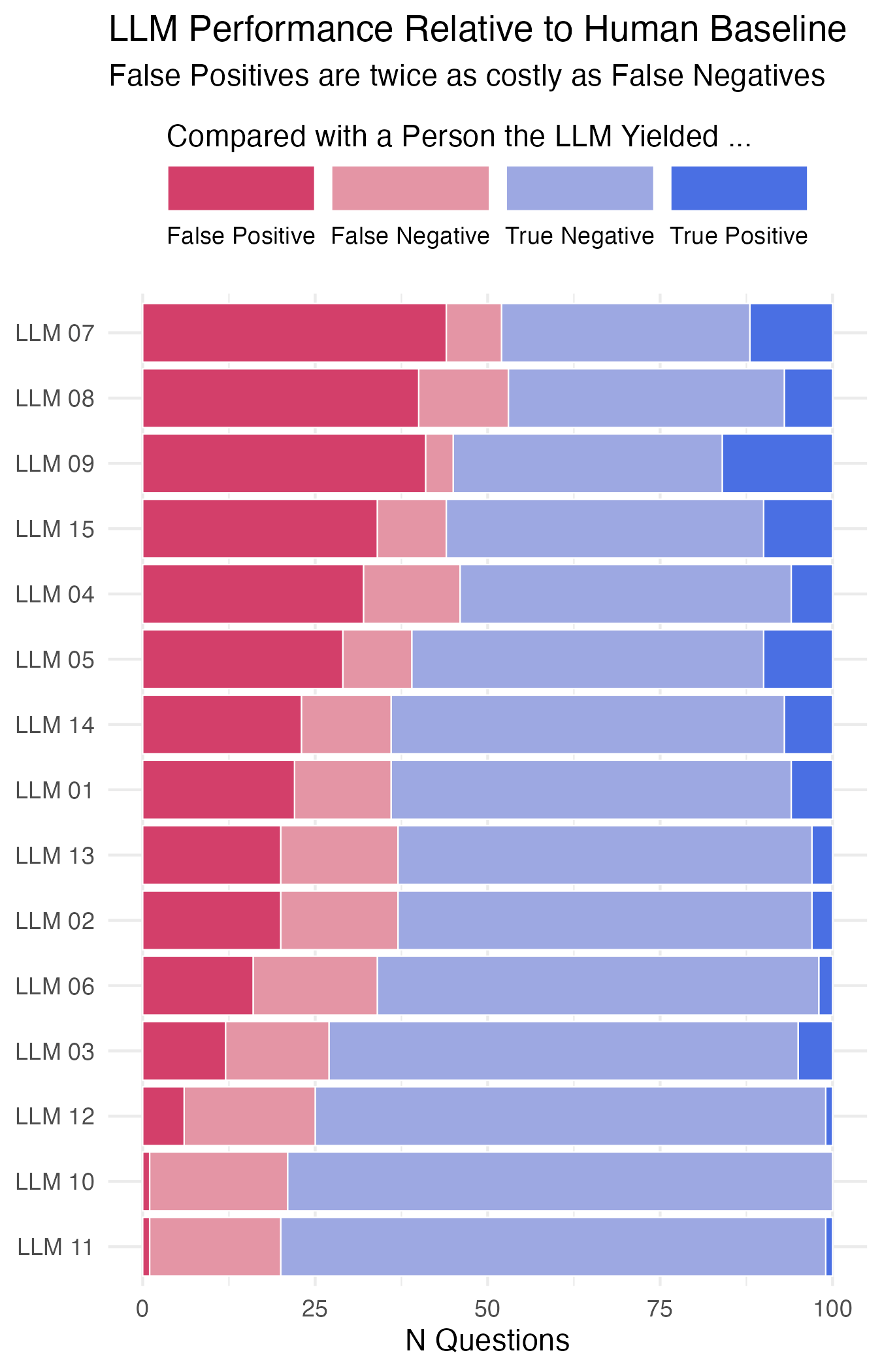
Ordered and stacked bar chart of imaginary LLM performance.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.