
Advent of 2021, Day 9 – RDD Operations
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
- Dec 01: What is Apache Spark
- Dec 02: Installing Apache Spark
- Dec 03: Getting around CLI and WEB UI in Apache Spark
- Dec 04: Spark Architecture – Local and cluster mode
- Dec 05: Setting up Spark Cluster
- Dec 06: Setting up IDE
- Dec 07: Starting Spark with R and Python
- Dec 08: Creating RDD files
Two types of operations are available with RDD; transformations and actions. Transformations are lazy operations, meaning that they prepare the new RDD with every new operation but now show or return anything. We can say, that transformations are lazy because of updating existing RDD, these operations create another RDD. Actions on the other hand trigger the computations on RDD and show (return) the result of transformations.
Transformations
Transformations can be narrow or wide. As the name suggest, the difference is, where the data resides and type of transformation.
In narrow transformation all the elements that are required to compute the records in single partition live in the single partition of parent RDD. A limited subset of partition is used to calculate the result. These transformation are map(), filter(), sample(), union(), MapPartition(), FlatMap().
With wide transformation elements that are required to compute the records in the single partition may live in many partitions of parent RDD. The partition may live in many partitions of parent RDD. When using functions groupbyKey(), reducebyKey(), join(), cartesian(), repartition(), coalesce(), intersection(), distinct() we say that the RDD has undergone the wide transformation.
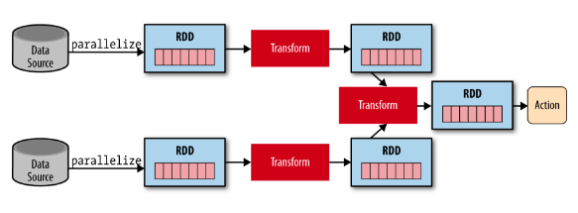
Nice presentation of these operations:

A simple example using R would be:
library(sparklyr) sdf_len(sc, 10) %>% spark_apply(~nrow(.x)) %>% sdf_repartition(1) %>% spark_apply(~sum(.x))
Or applying function to more nodes:
sdf_len(sc, 4) %>%
spark_apply(
function(data, context) context * data,
context = 100
)

Actions
Actions are what triggers the transformation. Values of action are stored to drivers or to external storage. And we can say that Actions nudges spark’s laziness into motion. It sents data from executer to the driver. Executors are agens that are responsible for executing a task.
These tasks are (listing just the most frequent ones) count(), collect(), take(), top(), reduce(), aggregate(), foreach().
library(sparklyr)
iris %>%
spark_apply(
function(e) summary(lm(Petal_Length ~ Petal_Width, e))$r.squared,
names = "r.squared",
group_by = "Species")
Actions occur in last step, just before the result (value) is returned.
Tomorrow we will look start working with data frames.
Compete set of code, documents, notebooks, and all of the materials will be available at the Github repository: https://github.com/tomaztk/Spark-for-data-engineers
Happy Spark Advent of 2021!
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.