
Beyond Univariate, Single-Sample Data with MCHT
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Introduction
I’ve spent the past few weeks writing about MCHT, my new package for Monte Carlo and bootstrap hypothesis testing. After discussing how to use MCHT safely, I discussed how to use it for maximized Monte Carlo (MMC) testing, then bootstrap testing. One may think I’ve said all I want to say about the package, but in truth, I’ve only barely passed the halfway point!
Today I’m demonstrating how general MCHT is, allowing one to use it for multiple samples and on non-univariate data. I’ll be doing so with two examples: a permutation test and the 
Permutation Test
The idea of the permutation test dates back to Fisher (see [1]) and it forms the basis of computational testing for difference in mean. Let’s suppose that we have two samples with respective means 


against
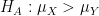
If the null hypothesis is true and we also make the stronger assumption that the two samples were drawn from distributions that could differ only in their means, then the labelling of the two samples is artificial, and if it were removed the two samples would be indistinguishable. Relabelling the data and artificially calling one sample the 

- Generate
new datasets by randomly assigning labels to the combined sample of
and
.
- Compute copies of the test statistic on each of the new samples; suppose that the test statistic used is the difference in means,
.
- Compute the test statistic on the actual sample and compare to the simulated statistics. If the actual statistic is relatively large compared to the simulated statistics, then reject the null hypothesis in favor of the alternative; otherwise, don’t reject.
In practice step 3 is done by computing a 
Permutation Tests Using MCHT
The permutation test is effectively a bootstrap test, so it is supported by MCHT, though one may wonder how that’s the case when the parameters test_stat, stat_gen, and rand_gen only accept one parameter, x, representing the dataset (as opposed to, say, t.test(), which has an x and an optional y parameter). But MCHTest() makes very few assumptions about what object x actually is; if your object is either a vector or tabular, then the MCHTest object should not have a problem with it (it’s even possible a loosely structured list would be fine, but I have not tested this; tabular formats should cover most use cases).
In this case, putting our data in long-form format makes doing a permutation test fairly simple. One column will contain the group an observation belongs to while the other contains observation values. The test_stat function will split the data according to group, compute group-wise means, and finally compute the test statistic. rand_gen generates new dataset by permuting the labels in the data frame. stat_gen merely serves as the glue between the two.
The result is the following test.
library(MCHT)
library(doParallel)
registerDoParallel(detectCores())
ts <- function(x) {
grp_means <- aggregate(value ~ group, data = x, FUN = mean)
grp_means$value[1] - grp_means$value[2]
}
rg <- function(x) {
x$group <- sample(x$group)
x
}
sg <- function(x) {
test_stat(x)
}
permute.test <- MCHTest(ts, sg, rg, seed = 123, N = 1000,
localize_functions = TRUE)
df <- data.frame("value" = c(rnorm(5, 2, 1), rnorm(10, 0, 1)),
"group" = rep(c("x", "y"), times = c(5, 10)))
permute.test(df)
##
## Monte Carlo Test
##
## data: df
## S = 1.3985, p-value = 0.036
Linear Regression F Test
Suppose for each observation in our dataset there is an outcome of interest, 

![E[\epsilon_i] = 0](https://s0.wp.com/latex.php?latex=E%5B%5Cepsilon_i%5D+%3D+0&bg=ffffff&%23038;fg=444444&%23038;s=0 "E[\epsilon_i] = 0")

The first question someone should asked when considering a regression model is whether it’s worth anything at all. An alternative approach to predicting

is much simpler and should be preferred to the more complicated model listed above if it’s just as good at explaining the behavior of 

The

The alternative says that at least one of the regressors is helpful in predicting

We can use the



2, respectively.
This test is called the
If the null hypothesis is true then the best model for the data is this:




- Shuffle
- Compute
- Compare the
F Test Using MCHT
Let’s perform the iris dataset. We will see if there is a relationship between the sepal length and sepal width among iris setosa flowers. Below is an initial split and visualization:
library(dplyr)
setosa <- iris %>% filter(Species == "setosa") %>%
select(Sepal.Length, Sepal.Width)
plot(Sepal.Width ~ Sepal.Length, data = setosa)

There is an obvious relationship between the variables. Thus we should expect the test to reject the null hypothesis. That is what we would conclude if we were to run the conventional
res <- lm(Sepal.Width ~ Sepal.Length, data = setosa) summary(res) ## ## Call: ## lm(formula = Sepal.Width ~ Sepal.Length, data = setosa) ## ## Residuals: ## Min 1Q Median 3Q Max ## -0.72394 -0.18273 -0.00306 0.15738 0.51709 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) -0.5694 0.5217 -1.091 0.281 ## Sepal.Length 0.7985 0.1040 7.681 6.71e-10 *** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 0.2565 on 48 degrees of freedom ## Multiple R-squared: 0.5514, Adjusted R-squared: 0.542 ## F-statistic: 58.99 on 1 and 48 DF, p-value: 6.71e-10
Let’s now implement the procedure I described with MCHTest().
ts <- function(x) {
res <- lm(Sepal.Width ~ Sepal.Length, data = x)
summary(res)$fstatistic[[1]] # Only way I know to automatically compute the
# statistic
}
# rand_gen's function can use both x and n, and n will be the number of rows of
# the dataset
rg <- function(x, n) {
x$Sepal.Width <- sample(x$Sepal.Width, replace = TRUE, size = n)
x
}
b.f.test.1 <- MCHTest(ts, ts, rg, seed = 123, N = 1000)
b.f.test.1(setosa)
##
## Monte Carlo Test
##
## data: setosa
## S = 58.994, p-value < 2.2e-16
Excellent! It reached the correct conclusion.
Conclusion
One may naturally ask whether we can write functions a bit more general than what I’ve shown here at least in the regression context. For example, one may want parameters specifying a formula so that the regression model isn’t hard-coded into the test. In short, the answer is yes; MCHTest objects try to pass as many parameters to the input functions as they can.
Here is the revised example that works for basically any formula:
ts <- function(x, formula) {
res <- lm(formula = formula, data = x)
summary(res)$fstatistic[[1]]
}
rg <- function(x, n, formula) {
dep_var <- all.vars(formula)[1] # Get the name of the dependent variable
x[[dep_var]] <- sample(x[[dep_var]], replace = TRUE, size = n)
x
}
b.f.test.2 <- MCHTest(ts, ts, rg, seed = 123, N = 1000)
b.f.test.2(setosa, formula = Sepal.Width ~ Sepal.Length)
##
## Monte Carlo Test
##
## data: setosa
## S = 58.994, p-value < 2.2e-16
This shows that you can have a lot of control over how MCHTest objects handle their inputs, giving you considerable flexibility.
Next post: time series and MCHT
References
- R. A. Fisher, The design of experiments (1935)
Packt Publishing published a book for me entitled Hands-On Data Analysis with NumPy and Pandas, a book based on my video course Unpacking NumPy and Pandas. This book covers the basics of setting up a Python environment for data analysis with Anaconda, using Jupyter notebooks, and using NumPy and pandas. If you are starting out using Python for data analysis or know someone who is, please consider buying my book or at least spreading the word about it. You can buy the book directly or purchase a subscription to Mapt and read it there.
If you like my blog and would like to support it, spread the word (if not get a copy yourself)!
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.