
R Users Will Now Inevitably Become Bayesians
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
There are several reasons why everyone isn’t using Bayesian methods for regression modeling. One reason is that Bayesian modeling requires more thought: you need pesky things like priors, and you can’t assume that if a procedure runs without throwing an error that the answers are valid. A second reason is that MCMC sampling — the bedrock of practical Bayesian modeling — can be slow compared to closed-form or MLE procedures. A third reason is that existing Bayesian solutions have either been highly-specialized (and thus inflexible), or have required knowing how to use a generalized tool like BUGS, JAGS, or Stan. This third reason has recently been shattered in the R world by not one but two packages: brms and rstanarm. Interestingly, both of these packages are elegant front ends to Stan, via rstan and shinystan.
This article describes brms and rstanarm, how they help you, and how they differ.

You can install both packages from CRAN, making sure to install dependencies so you get rstan, Rcpp, and shinystan as well. [EDIT: Note that you will also need a C++ compiler to make this work, as Charles and Paul Bürkner (@paulbuerkner) have found. On Windows that means you’ll need to install Rtools, and on the Mac you may have to install Xcode (which is also free). brms‘s help refers to the RStan Getting Started, which is very helpful.] If you like having the latest development versions — which may have a few bug fixes that the CRAN versions don’t yet have — you can use devtools to install them following instructions at the brms github site or the rstanarm github site.
The brms package
Let’s start with a quick multinomial logistic regression with the famous Iris dataset, using brms. You may want to skip the actual brm call, below, because it’s so slow (we’ll fix that in the next step):
library (brms)
rstan_options (auto_write=TRUE)
options (mc.cores=parallel::detectCores ()) # Run on multiple cores
set.seed (3875)
ir <- data.frame (scale (iris[, -5]), Species=iris[, 5])
### With improper prior it takes about 12 minutes, with about 40% CPU utilization and fans running,
### so you probably don't want to casually run the next line...
system.time (b1 <- brm (Species ~ Petal.Length + Petal.Width + Sepal.Length + Sepal.Width, data=ir,
family="categorical", n.chains=3, n.iter=3000, n.warmup=600))
First, note that the brm call looks like glm or other standard regression functions. Second, I advised you not to run the brm because on my couple-of-year-old Macbook Pro, it takes about 12 minutes to run. Why so long? Let’s look at some of the results of running it:
b1 # ===> Result, below
Family: categorical (logit)
Formula: Species ~ Petal.Length + Petal.Width + Sepal.Length + Sepal.Width
Data: ir (Number of observations: 150)
Samples: 3 chains, each with n.iter = 3000; n.warmup = 600; n.thin = 1;
total post-warmup samples = 7200
WAIC: NaN
Fixed Effects:
Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
Intercept[1] 1811.49 1282.51 -669.27 4171.99 16 1.26
Intercept[2] 1773.48 1282.87 -707.92 4129.22 16 1.26
Petal.Length[1] 3814.69 6080.50 -8398.92 15011.29 2 2.32
Petal.Length[2] 3848.02 6080.70 -8353.52 15032.85 2 2.32
Petal.Width[1] 14769.65 18021.35 -2921.08 54798.11 2 3.36
Petal.Width[2] 14794.32 18021.10 -2902.81 54829.05 2 3.36
Sepal.Length[1] 1519.97 1897.12 -2270.30 5334.05 7 1.43
Sepal.Length[2] 1515.83 1897.17 -2274.31 5332.95 7 1.43
Sepal.Width[1] -7371.98 5370.24 -18512.35 -935.85 2 2.51
Sepal.Width[2] -7377.22 5370.22 -18515.78 -941.65 2 2.51
A multinomial logistic regression involves multiple pair-wise logistic regressions, and the default is a baseline level versus the other levels. In this case, the last level (virginica) is the baseline, so we see results for 1) setosa v virginica, and 2) versicolor v virginica. (brms provides three other options for ordinal regressions, too.)
The first “diagnostic” we might notice is that it took way longer to run than we might’ve expected (12 minutes) for such a small dataset. Turning to the formal results above, we see huge estimated coefficients, huge error margins, a tiny effective sample size (2-16 effective samples out of 7200 actual samples), and an Rhat significantly different from 1. So we can officially say something (everything, actually) is very wrong.
If we were coding in Stan ourselves, we’d have to think about bugs we might’ve introduced, but with brms, we can assume for now that the code is correct. So the first thing that comes to mind is that the default flat (improper) priors are so broad that the sampler is wandering aimlessly, which gives poor results and takes a long time because of many rejections. The first graph in this posting was generated by plot (b1), and it clearly shows non-convergence of Petal.Length[1] (setosa v virginica). This is a good reason to run multiple chains, since you can see how poor the mixing is and how different the densities are. (If we want nice interactive interface to all of the results, we could launch_shiny (b1).)
Let’s try again, with more reasonable priors. In the case of a logistic regression, the exponentiated coefficients reflect the increase in probability for a unit increase of the variable, so let’s try using a normal (0, 8) prior, (95% CI is ")
system.time (b2 <- brm (Species ~ Petal.Length + Petal.Width + Sepal.Length + Sepal.Width), data=ir,
family="categorical", n.chains=3, n.iter=3000, n.warmup=600,
prior=c(set_prior ("normal (0, 8)"))))
This only takes about a minute to run — about half of which involves compiling the model in C++ — which is a more reasonable time, and the results are much better:
Family: categorical (logit)
Formula: Species ~ Petal.Length + Petal.Width + Sepal.Length + Sepal.Width
Data: ir (Number of observations: 150)
Samples: 3 chains, each with iter = 3000; warmup = 600; thin = 1;
total post-warmup samples = 7200
WAIC: 21.87
Fixed Effects:
Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
Intercept[1] 6.90 3.21 1.52 14.06 2869 1
Intercept[2] -5.85 4.18 -13.97 2.50 2865 1
Petal.Length[1] 4.15 4.45 -4.26 12.76 2835 1
Petal.Length[2] 15.48 5.06 5.88 25.62 3399 1
Petal.Width[1] 4.32 4.50 -4.50 13.11 2760 1
Petal.Width[2] 13.29 4.91 3.76 22.90 2800 1
Sepal.Length[1] 4.92 4.11 -2.85 13.29 2360 1
Sepal.Length[2] 3.19 4.16 -4.52 11.69 2546 1
Sepal.Width[1] -4.00 2.37 -9.13 0.19 2187 1
Sepal.Width[2] -5.69 2.57 -11.16 -1.06 2262 1
Much more reasonable estimates, errors, effective samples, and Rhat. And let’s compare a plot for Petal.Length[1]:

Ahhh, that looks a lot better. The chains mix well and seem to randomly explore the space, and the densities closely agree. Go back to the top graph and compare, to see how much of an influence poor priors can have.
We have a wide choice of priors, including Normal, Student’s t, Cauchy, Laplace (double exponential), and many others. The formula argument is a lot like lmer‘s (from package lme4, an excellent place to start a hierarchical/mixed model to check things before moving to Bayesian solutions) with an addition:
response | addition ~ fixed + (random | group)
where addition can be replaced with function calls se, weights, trials, cat, cens, or trunc, to specify SE of the observations (for meta-analysis), weighted regression, to specify the number of trials underlying each observation, the number of categories, and censoring or truncation, respectively. (See details of brm for which families these apply to, and how they are used.) You can do zero-inflated and hurdle models, specify multiplicative effects, and of course do the usual hierarchical/mixed effects (random and group) as well.
Families include: gaussian, student, cauchy, binomial, bernoulli, beta, categorical, poisson, negbinomial, geometric, gamma, inverse.gaussian, exponential, weibull, cumulative, cratio, sratio, acat, hurdle_poisson, hurdle_negbinomial, hurdle_gamma, zero_inflated_poisson, and zero_inflated_negbinomial. (The cratio, sratio, and acat options provide different options than the default baseline model for (ordinal) categorical models.)
All in one function! Oh, did I mention that you can specify AR, MA, and ARMA correlation structures?
The only downside to brms could be that it generates Stan code on the fly and passes it to Stan via rstan, which will result in it being compiled. For larger models, the 40-60 seconds for compilation won’t matter much, but for small models like this Iris model it dominates the run time. This technique provides great flexibility, as listed above, so I think it’s worth it.
Another example of brms‘ emphasis on flexibility is that the Stan code it generates is simple, and could be straightforwardly used to learn Stan coding or as a basis for a more-complex Stan model that you’d modify and then run directly via rstan. In keeping with this, brms provides the make_stancode and make_standata functions to allow direct access to this functionality.
The rstanarm package
The rstanarm package takes a similar, but different approach. Three differences stand out: First, instead of a single main function call, rstanarm has several calls that are meant to be similar to pre-existing functions you are probably already using. Just prepend with “stan_”: stan_lm, stan_aov, stan_glm, stan_glmer, stan_gamm4 (GAMMs), and stan_polr (Ordinal Logistic). Oh, and you’ll probably want to provide some priors, too.
Second, rstanarm pre-compiles the models it supports when it’s installed, so it skips the compilation step when you use it. You’ll notice that it immediately jumps to running the sampler rather than having a “Compiling C++” step. The code it generates is considerably more extensive and involved than the code brms generates, which seems to allow it to sample faster but which would also make it more difficult to take and adapt it by hand to go beyond what the rstanarm/brms approach offers explicitly. In keeping with this philosophy, there is no explicit function for seeing the generated code, though you can always look into the fitted model to see it. For example, if the model were br2, you could look at br2$stanfit@stanmodel@model_code.
Third, as its excellent vignettes emphasize, Bayesian modeling is a series of steps that include posterior checks, and rstanarm provides a couple of functions to help you, including pp_check. (This difference is not as hard-wired as the first two, and brms could/should someday include similar functions, but it’s a statement that’s consistent with the Stan team’s emphasis.)
As a quick example of rstanarm use, let’s build a (poor, toy) model on the mtcars data set:
mm Results
stan_glm(formula = mpg ~ ., data = mtcars, prior = normal(0,
8))
Estimates:
Median MAD_SD
(Intercept) 11.7 19.1
cyl -0.1 1.1
disp 0.0 0.0
hp 0.0 0.0
drat 0.8 1.7
wt -3.7 2.0
qsec 0.8 0.8
vs 0.3 2.1
am 2.5 2.2
gear 0.7 1.5
carb -0.2 0.9
sigma 2.7 0.4
Sample avg. posterior predictive
distribution of y (X = xbar):
Median MAD_SD
mean_PPD 20.1 0.7
Note the more sparse output, which Gelman promotes. You can get more detail with summary (br), and you can also use shinystan to look at most everything that a Bayesian regression can give you. We can look at the values and CIs of the coefficients with plot (mm), and we can compare posterior sample distributions with the actual distribution with: pp_check (mm, "dist", nreps=30):
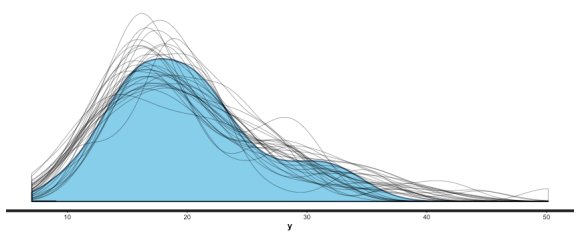
I could go into more detail, but this is getting a bit long, and rstanarm is a very nice package, too, so let’s wrap things up with a comparison of the two packages and some tips.
Commonalities and other differences
Both packages support a wide variety of regression models — pretty much everything you’ll ever need. Both packages use Stan, via rstan and shinystan, which means you can also use rstan capabilities as well, and you get parallel execution support — mainly useful for multiple chains, which you should always do. Both packages support sparse solutions, brms via Laplace or Horseshoe priors, and rstanarm via Hierarchical Shrinkage Family priors. Both packages support Stan 2.9’s new Variational Bayes methods, which are much faster then MCMC sampling (an order of magnitude or more), but approximate and only valid for initial explorations, not final results.
Because of its pre-compiled-model approach, rstanarm is faster in starting to sample for small models, and is slightly faster overall, though a bit less flexible with things like priors. brms supports (non-ordinal) multinomial logistic regression, several ordinal logistic regression types, and time-series correlation structures. rstanarm supports GAMMs (via stan_gamm4). rstanarm is done by the Stan/rstan folks. brms‘s make_stancode makes Stan less of a black box and allows you to go beyond pre-packaged capabilities, while rstanarm‘s pp_check provides a useful tool for the important step of posterior checking.
Summary
Bayesian modeling is a general machine that can model any kind of regression you can think of. Until recently, if you wanted to take advantage of this general machinery, you’d have to learn a general tool and its language. If you simply wanted to use Bayesian methods, you were often forced to use very-specialized functions that weren’t flexible. With the advent of brms and rstanarm, R users can now use extremely flexible functions from within the familiar and powerful R framework. Perhaps we won’t all become Bayesians now, but we now have significantly fewer excuses for not doing so. This is very exciting!
Stan tips
First, Stan’s HMC/NUTS sampler is slower per sample, but better explores the probability space, so you should be able to use fewer samples than you might’ve come to expect with other samplers. (Probably an order of magnitude fewer.) Second, Stan transforms code to C++ and then compiles the C++, which introduces an initial delay at the start of sampling. (This is bypassed in rstanarm.) Third, don’t forget the rstan_options and options statements I started with: you really need to run multiple chains and the fastest way to do that is by having Stan run multiple processes/threads.
Remember that the results of the stan_ plots, such as stan_dens or the results of rstanarm‘s plot (mod, "dens") are ggplot2 objects and can be modified with additional geoms. For example, if you want to zoom in on a density plot:
stan_plot (b2$fit, show_density=TRUE) + coord_cartesian (xlim=c(-15, 15))
(Note: you want to use coord_cartesian rather than xlim which eliminates points and screws up your plot.) If you want to jitter and adjust the opacity of pp_check points:
pp_check (mm, check="scatter", nreps=12) + geom_jitter (width=0.1, height=0.1, color=rgb (0, 0, 0, 0.2))
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.