
likelihood-free inference in high-dimensional models
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
“…for a general linear model (GLM), a single linear function is a sufficient statistic for each associated parameter…”
 The recently arXived paper “Likelihood-free inference in high-dimensional models“, by Kousathanas et al. (July 2015), proposes an ABC resolution of the dimensionality curse [when the dimension of the parameter and of the corresponding summary statistics] by turning Gibbs-like and by using a component-by-component ABC-MCMC update that allows for low dimensional statistics. In the (rare) event there exists a conditional sufficient statistic for each component of the parameter vector, the approach is just as justified as when using a generic ABC-Gibbs method based on the whole data. Otherwise, that is, when using a non-sufficient estimator of the corresponding component (as, e.g., in a generalised [not general!] linear model), the approach is less coherent as there is no joint target associated with the Gibbs moves. One may therefore wonder at the convergence properties of the resulting algorithm. The only safe case [in dimension 2] is when one of the restricted conditionals does not depend on the other parameter. Note also that each Gibbs step a priori requires the simulation of a new pseudo-dataset, which may be a major imposition on computing time. And that setting the tolerance for each parameter is a delicate calibration issue because in principle the tolerance should depend on the other component values.
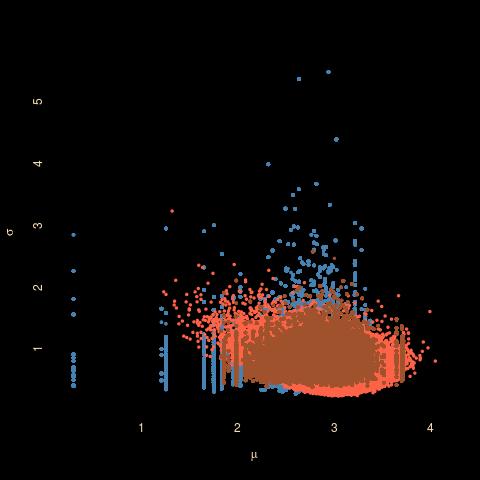
The recently arXived paper “Likelihood-free inference in high-dimensional models“, by Kousathanas et al. (July 2015), proposes an ABC resolution of the dimensionality curse [when the dimension of the parameter and of the corresponding summary statistics] by turning Gibbs-like and by using a component-by-component ABC-MCMC update that allows for low dimensional statistics. In the (rare) event there exists a conditional sufficient statistic for each component of the parameter vector, the approach is just as justified as when using a generic ABC-Gibbs method based on the whole data. Otherwise, that is, when using a non-sufficient estimator of the corresponding component (as, e.g., in a generalised [not general!] linear model), the approach is less coherent as there is no joint target associated with the Gibbs moves. One may therefore wonder at the convergence properties of the resulting algorithm. The only safe case [in dimension 2] is when one of the restricted conditionals does not depend on the other parameter. Note also that each Gibbs step a priori requires the simulation of a new pseudo-dataset, which may be a major imposition on computing time. And that setting the tolerance for each parameter is a delicate calibration issue because in principle the tolerance should depend on the other component values.  and mean x sd (brown), for a normal sample of size 10 and a normal x exponential prior") I ran a comparative experiment on a toy normal target, using either empirical mean and variance (blue), or empirical median and mad (brown), with little difference in the (above) output. Especially when considering that I set the tolerance somewhat arbitrarily. This could be due to the fact that the pairs are quite similar in terms of their estimation properties. However, I then realised that the empirical variance is not sufficient for the variance conditional on the mean parameter. I looked at the limiting case (with zero tolerance), which amounts to simulating σ first and then μ given σ, and ran a (Gibbs and iid) simulation. The difference, as displayed below (red standing for the exact ABC case), is not enormous, even though it produces a fatter tail in μ. Note the interesting feature that I cannot produce the posterior distribution of the parameters given the median and mad statistics. Which is a great introduction to ABC!
I ran a comparative experiment on a toy normal target, using either empirical mean and variance (blue), or empirical median and mad (brown), with little difference in the (above) output. Especially when considering that I set the tolerance somewhat arbitrarily. This could be due to the fact that the pairs are quite similar in terms of their estimation properties. However, I then realised that the empirical variance is not sufficient for the variance conditional on the mean parameter. I looked at the limiting case (with zero tolerance), which amounts to simulating σ first and then μ given σ, and ran a (Gibbs and iid) simulation. The difference, as displayed below (red standing for the exact ABC case), is not enormous, even though it produces a fatter tail in μ. Note the interesting feature that I cannot produce the posterior distribution of the parameters given the median and mad statistics. Which is a great introduction to ABC!
 R code follows:
R code follows:
N=10
data=rnorm(N,mean=3,sd=.5)
#ABC with insufficient statistics
medata=median(data)
madata=mad(data)
varamad=rep(0,100)
for (i in 1:100)
varamad[i]=mad(sample(data,N,rep=TRUE))
tol=c(.01*mad(data),.05*mad(varamad))
T=1e6
mu=rep(median(data),T)
sig=rep(mad(data),T)
for (t in 2:T){
mu[t]=rnorm(1)
psudo=rnorm(N,mean=mu[t],sd=sig[t-1])
if (abs(medata-median(psudo))>tol[1])
mu[t]=mu[t-1]
sig[t]=1/rexp(1)
psudo=rnorm(N,mean=mu[t],sd=sig[t])
if (abs(madata-mad(psudo))>tol[2])
sig[t]=sig[t-1]
}
#ABC with more sufficient statistics
meaata=mean(data)
sddata=sd(data)
varamad=rep(0,100)
for (i in 1:100)
varamad[i]=sd(sample(data,N,rep=TRUE))
tol=c(.1*sd(data),.1*sd(varamad))
for (t in 2:T){
mu[t]=rnorm(1)
psudo=rnorm(N,mean=mu[t],sd=sig[t-1])
if (abs(meaata-mean(psudo))>tol[1])
mu[t]=mu[t-1]
sig[t]=1/rexp(1)
psudo=rnorm(N,mean=mu[t],sd=sig[t])
if (abs(sddata-sd(psudo))>tol[2])
sig[t]=sig[t-1]
}
#MCMC with false sufficient
sig=1/sqrt(rgamma(T,shape=.5*N,rate=1+.5*var(data)))
mu=rnorm(T,mean(data)/(1+sig^2/N),sd=1/sqrt(1+N/sig^2)))
Filed under: Books, R, Statistics, University life Tagged: ABC, ABC-Gibbs, compatible conditional distributions, convergence of Gibbs samplers, curse of dimensionality, exact ABC, Gibbs sampling, median, median absolute deviation, R

R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.