
I’ll take my NLS with weights, please…
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Today I want to advocate weighted nonlinear regression. Why so?
Minimum-variance estimation of the adjustable parameters in linear and non-linear least squares requires that the data be weighted inversely as their variances 

The variance of a fit 

The relationship between
whereas 



 = \int_{\chi^2}^\infty P_\chi(x^2, \nu)dx^2")

1 - pchisq(chi^2, nu) in R.
)^2}{\sigma_i^2}")

To see that this actually works, we can Monte Carlo simulate some heteroscedastic data with defined variance as a function of 
First we take the example from the documentation to nls and fit an enzyme kinetic model:
DNase1 <- subset(DNase, Run == 1)
fm3DNase1 <- nls(density ~ Asym/(1 + exp((xmid - log(conc))/scal)),
data = DNase1,
start = list(Asym = 3, xmid = 0, scal = 1))
Then we take the fitted values 


")
FITTED <- unique(fitted(fm3DNase1))
DAT <- sapply(FITTED, function(x) rnorm(20, mean = x, sd = 0.02 * x))
matplot(t(DAT), type = "p", pch = 16, lty = 1, col = 1)
lines(FITTED, col = 2)
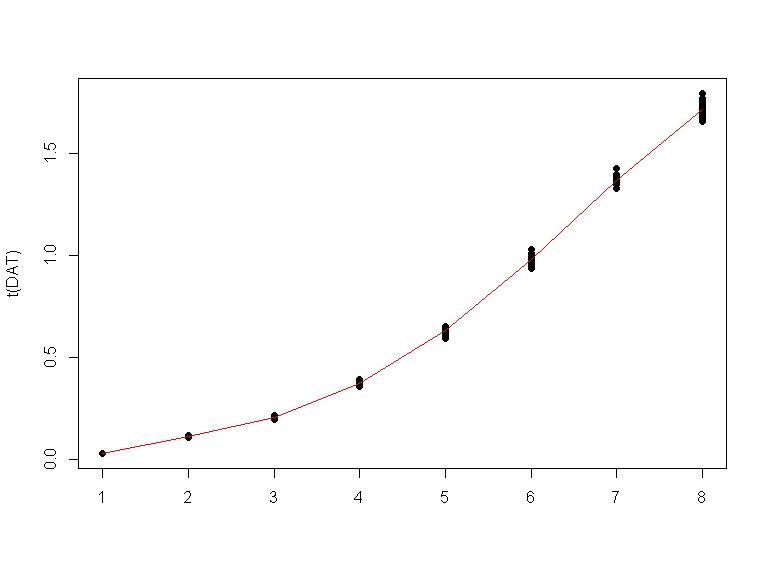
Now we create the new dataframe to be fitted. For this we have to stack the unique
CONC <- unique(DNase1$conc)
fitDAT <- data.frame(conc = rep(CONC, each = 20), density = matrix(DAT))
First we create the unweighted fit:
FIT1 <- nls(density ~ Asym/(1 + exp((xmid - log(conc))/scal)),
data = fitDAT,
start = list(Asym = 3, xmid = 0, scal = 1))
Then we fit the data with weights ")
VAR <- tapply(fitDAT$density, fitDAT$conc, var)
VAR <- rep(VAR, each = 20)
FIT2 <- nls(density ~ Asym/(1 + exp((xmid - log(conc))/scal)),
data = fitDAT, weights = 1/VAR,
start = list(Asym = 3, xmid = 0, scal = 1))
For calculation of 
library(qpcR)
> fitchisq(FIT1)
$chi2
[1] 191.7566
$chi2.red
[1] 1.22138
$p.value
[1] 0.03074883
> fitchisq(FIT2)
$chi2
[1] 156.7153
$chi2.red
[1] 0.9981866
$p.value
[1] 0.4913983
Now we see the benefit of weighted fitting: Only the weighted model shows us with it’s reduced chi-square value of almost exactly 1 and its high p-value that our fitted model approximates the parent model. And of course it does, because we simulated our data from it…
Cheers,
Andrej
Filed under: nonlinear regression Tagged: chi-square, nonlinear, regression, weights

R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.