
24 Days of R: Day 22
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
I like to use Goodreads to keep track of which books I'm reading (and not reading). They very helpfully sent me an e-mail to inform me how many books I've read so far in 2013. The number is 19. Hardly an impressive number, but between job, family and trying to develop my R skills, I'm not embarassed by that either. However, it's not as though I'm reading James Joyce. This year reveals a great interest in the works of Robert B. Parker.. There are a few omissions as well- all my fault. I never bothered to enter Naked Statistics and Medium Raw was never listed as having been finished. That understood, let's see if I can learn anything about my reading habits.
I've not yet come to grips with the Goodreads API. It was the work of only a few minutes to copy and paste my collection of books into Excel and strip out the nonsense to produce a quick CSV file. I'll load that in and have a look.
dfBooks = read.csv("./Data/Goodreads.csv", stringsAsFactors = FALSE)
colnames(dfBooks)[6] = "DateRead"
colnames(dfBooks)[7] = "DateAdded"
dfBooks$DateAdded = gsub("[edit]", "", dfBooks$DateAdded)
dfBooks$DateAdded = gsub(" ", "", dfBooks$DateAdded)
dfBooks$DateAdded = as.Date(dfBooks$DateAdded, "%m/%d/%Y")
When did I add books to my list? Most of the time this will be one book on a particular day, but there are exceptions. I'll look at this timeline in a few different ways.
dfAgg = aggregate(x = dfBooks$DateAdded, by = list(dfBooks$DateAdded), FUN = length)
colnames(dfAgg) = c("DateAdded", "NumBooks")
plot(x = dfAgg$DateAdded, y = dfAgg$NumBooks, pch = 19, xlab = "Date", ylab = "Number of books")
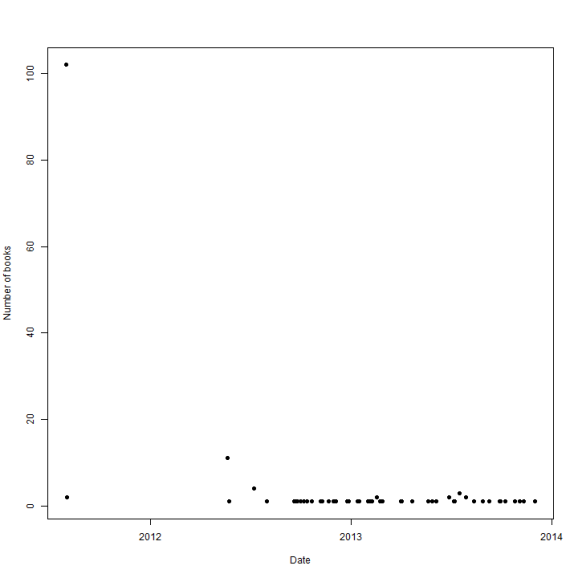
That giant bump is when GoodReads switched over from their Facebook app. I'll zero in on something relevant.
dfAgg = subset(dfAgg, DateAdded >= as.Date("2012-01-01"))
plot(x = dfAgg$DateAdded, y = dfAgg$NumBooks, pch = 19, xlab = "Date", ylab = "Number of books")
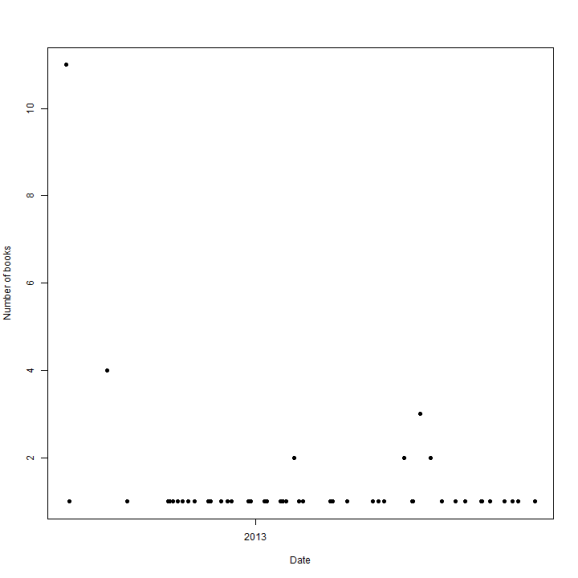
There's another crazy blip near the start of 2012. I've no idea why everything defaults to sometime in the middle of last year. I've been reading books for quite a long time and there's not a lot of variation.
No matter. This isn't terribly informative. I'm going to try looking at this differently. The date I finished the book isn't often available and is formatted in such a way that it resists easy munging. I'm going alter it manually for the 44 books that I started in the last three months of 2012.
dfBooks2 = read.csv("./Data/Goodreads2.csv", stringsAsFactors = FALSE)
dfBooks2$DateRead = as.Date(dfBooks2$DateRead, "%m/%d/%Y")
dfBooks2$DateAdded = as.Date(dfBooks2$DateAdded, "%m/%d/%Y")
library(timeline)
# I need to sample a random integer so that we have a unique identifier for
# the book timeline's default is to use the book title as the label.
set.seed(1234)
dfBooks2$GroupCol = sample(nrow(dfBooks2))
timeline(dfBooks2[!is.na(dfBooks2$DateRead), ], group.col = "GroupCol", start.col = "DateAdded",
end.col = "DateRead", label.col = "title")
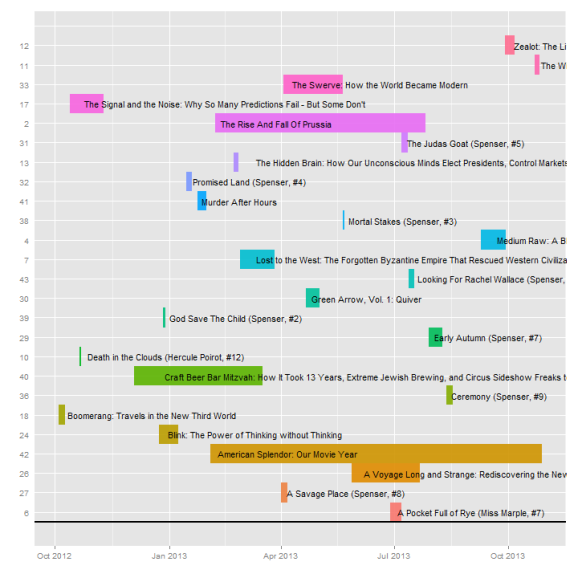
Cool. For the record, it didn't take me that long to read American Splendor. I think that's one where I had put the book aside for quite some time (it's a lot of short vignettes) and then finally marked it as read. The Rise and Fall of Prussia seems about right. I recall having read that in a couple concentrated bursts that were spaced far apart. I'm also struck by the fact that it took only a couple days more to read a scholarly account of the life of Jesus than it does for me to read a Spenser novel.
Tomorrow: Probably heteroskedasticity.
sessionInfo
## function (package = NULL)
## {
## z <- list()
## z$R.version <- R.Version()
## z$platform <- z$R.version$platform
## if (nzchar(.Platform$r_arch))
## z$platform <- paste(z$platform, .Platform$r_arch, sep = "/")
## z$platform <- paste0(z$platform, " (", 8 * .Machine$sizeof.pointer,
## "-bit)")
## z$locale <- Sys.getlocale()
## if (is.null(package)) {
## package <- grep("^package:", search(), value = TRUE)
## keep <- sapply(package, function(x) x == "package:base" ||
## !is.null(attr(as.environment(x), "path")))
## package <- sub("^package:", "", package[keep])
## }
## pkgDesc <- lapply(package, packageDescription, encoding = NA)
## if (length(package) == 0)
## stop("no valid packages were specified")
## basePkgs <- sapply(pkgDesc, function(x) !is.null(x$Priority) &&
## x$Priority == "base")
## z$basePkgs <- package[basePkgs]
## if (any(!basePkgs)) {
## z$otherPkgs <- pkgDesc[!basePkgs]
## names(z$otherPkgs) <- package[!basePkgs]
## }
## loadedOnly <- loadedNamespaces()
## loadedOnly <- loadedOnly[!(loadedOnly %in% package)]
## if (length(loadedOnly)) {
## names(loadedOnly) <- loadedOnly
## pkgDesc <- c(pkgDesc, lapply(loadedOnly, packageDescription))
## z$loadedOnly <- pkgDesc[loadedOnly]
## }
## class(z) <- "sessionInfo"
## z
## }
## <bytecode: 0x000000001076e4a8>
## <environment: namespace:utils>

R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.