
Updated Sentiment Analysis and a Word Cloud for Netflix – The R Way!
[This article was first published on All Things R, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
The Netflix investors must be happy and cheerful as the stock is up more than 78% since the beginning of the year (YES, 78%, Source: Yahoo Finance!). I am not going to talk about what turned the stock around after a much talked/hyped about Netflix debacle of the late 2011 that earned Reed Hastings quite a few UNWANTED title and every one demanded his resignation from the top post. Not so fast, Mr. Bear! Reed Hastings must be smiling! After a stellar performance this year including carefully released stats on viewership, streaming hours as well as a solid Q4’11 earnings, Netflix is back and most importantly viewers are back!
Well, is is not coincidental that the sentiment for Netflix is also improving, 68% of the tweets now have positive sentiment. See the table below:
| Total | Positive | Negative | Average | Total | Sentiment |
| Tweets Fetched | Tweets | Tweets | Score | Tweets | |
| 499 | 171 | 80 | 0.281 | 251 | 68% |
*Make sure you understand and interpret this analysis correctly. This analysis is not based on NLP.
I updated the sentiment analysis that I did last year, http://goo.gl/fkfPy , (I was then just beginning to play with Twitter and Text Mining packages in R) and used advanced packages like “TM” and “WordCloud”. The new analysis is based on more than 6,800 words which are most commonly prescribed in various sentiment analysis blogs/books. (Check out Hu and Liu http://www.cs.uic.edu/~liub/
I came across this excellent blog by Jeffrey Bean, @JeffreyBean, (http://goo.gl/RPkFX) and his tutorial. Thank you Mr. Bean! Please follow the instructions from Bean’s slides and the R code listed there as well as the R code here:
Here is the updated R code snippets –
#Populate the list of sentiment words from Hu and Liu (http://www.cs.uic.edu/~liub/
huliu.pwords <- scan('opinion-lexicon/
huliu.nwords <- scan('opinion-lexicon/
# Add some words
huliu.nwords <- c(huliu.nwords,'wtf','wait','
#Remove some words
huliu.nwords <- huliu.nwords[!huliu.nwords=='
huliu.nwords <- huliu.nwords[!huliu.nwords=='
#which(‘sap’ %in% huliu.nwords)
twitterTag <- "@Netflix"
# Get 1500 tweets – an individual is only allowed to get 1500 tweets
tweets <- searchTwitter(tag, n=1500)
tweets.text <- laply(tweets,function(t)t$
sentimentScoreDF <- getSentimentScore(tweets.text)
sentimentScoreDF$TwitterTag <- twitterTag
# Get rid of tweets that have zero score and seperate +ve from -ve tweets
sentimentScoreDF$posTweets <- as.numeric(sentimentScoreDF$
sentimentScoreDF$negTweets <- as.numeric(sentimentScoreDF$
#Summarize finidings
summaryDF <- ddply(sentimentScoreDF,"
TotalTweetsFetched=length(
PositiveTweets=sum(posTweets)
AverageScore=round(mean(
summaryDF$TotalTweets <- summaryDF$PositiveTweets + summaryDF$NegativeTweets
#Get Sentiment Score
summaryDF$Sentiment <- round(summaryDF$
Saving the best for the last, here is a word cloud (also called tag cloud) for Netflix built in R-
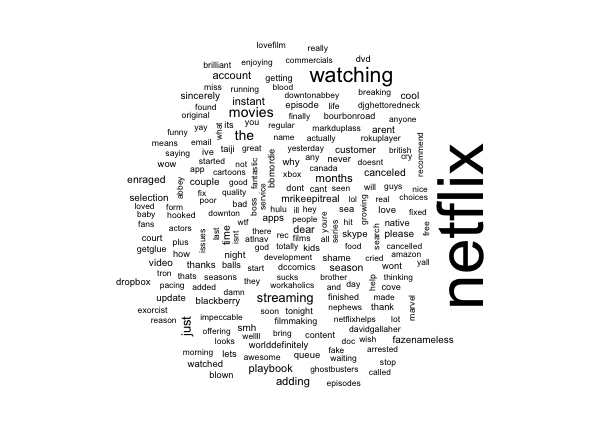
I will be putting the R code up here for building a word cloud after scrubbing it.
Happy Analyzing!
To leave a comment for the author, please follow the link and comment on their blog: All Things R.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.