
Spurious Regression of Time Series
[This article was first published on Fear and Loathing in Data Science, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
spu.ri.ousWant to share your content on R-bloggers? click here if you have a blog, or here if you don't.
adjective
: not genuine, sincere, or authentic
: based on false ideas or bad reasoning
http://www.merriam-webster.com/dictionary/spurious
When it comes to analysis of time series, just because you can, doesn’t mean you should, particularly with regards to regression. In short, if you have highly autoregressive time series and you build an OLS model, you will find estimates and t-statistics indicating a relationship when non exists. Without getting into the theory of the problem, let’s just simply go over an example using R. If you want to look at the proper way of looking at the relationship between x or several x’s versus y, I recommend the VARS package in R. If you want to dabble in causality, then explore Granger Causality, which I touch on in my very first post (the ultimate econometrics cynic, Nassim Taleb even recommends the technique in his book, Antifragile: Things That Gain From Disorder).
# produce two randomwalks
> rwalk1 = c(cumsum(rnorm(200))) > rwalk1.ts = ts(rwalk1) > rwalk2 = c(cumsum(rnorm(200))) > rwalk2.ts = ts(rwalk2) #use the seqplot from tseries package > seqplot.ts(rwalk1.ts, rwalk2.ts,)

These two series are completely random walks (highly autoregressive) and we should have no relationship whatsoever between them.
#build a linear model and examine it
> spurious = lm(rwalk1.ts ~ rwalk2.ts)
> summary(spurious)
Call:
lm(formula = rwalk1.ts ~ rwalk2.ts)
Residuals:
Min 1Q Median 3Q Max
-10.341 -4.495 -1.508 2.602 13.488
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.79154 1.15145 3.293 0.00117 **
rwalk2.ts -0.31904 0.06928 -4.605 7.36e-06 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 5.87 on 198 degrees of freedom
Multiple R-squared: 0.09675, Adjusted R-squared: 0.09219
F-statistic: 21.21 on 1 and 198 DF, p-value: 7.363e-06 We have a highly significant p-value. This will happen whenever you regress a random walk on another. The implication is that you must have stationary data e.g. first differencing or do dynamic regression.
> acf(resid(spurious)) #autocorrelation plot of residuals showing we violate the OLS assumption of no serial correlation

To do a dynamic regression, we need to regress Y on X and lagged Y.
> lag.walk1 = lag(rwalk1.ts, -1) #creates lagged Ys
> y = cbind(rwalk1.ts, rwalk2.ts, lag.walk1) #ties the three series together,this is important in R!> head(y) #verify that it worked
rwalk1.ts rwalk2.ts lag.walk1
[1,] 0.23560254 -1.7652148 NA
[2,] -1.55501435 -0.9889759 0.23560254
[3,] 0.05655502 0.4675756 -1.55501435
[4,] 0.55352522 2.0692308 0.05655502
[5,] 1.61779922 1.9401852 0.55352522
[6,] 1.11942660 1.4950455 1.61779922
> model = lm(y[,1] ~ y[,2] + y[,3]) #the dynamic regression model
> summary(model)
Call:
lm(formula = y[, 1] ~ y[, 2] + y[, 3])
Residuals:
Min 1Q Median 3Q Max
-2.63010 -0.66273 0.04715 0.63053 2.45922
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.036506 0.208782 0.175 0.861
y[, 2] -0.007199 0.012823 -0.561 0.575
y[, 3] 0.994871 0.012368 80.436 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.01 on 196 degrees of freedom
(2 observations deleted due to missingness)
Multiple R-squared: 0.9735, Adjusted R-squared: 0.9732
F-statistic: 3601 on 2 and 196 DF, p-value: < 2.2e-16
# As you would expect, the second time series is no longer significant, but the lagged values are.
# examine the residuals from the two models and notice the pattern in the spurious model
> plot(resid(model))
> plot(resid(spurious))
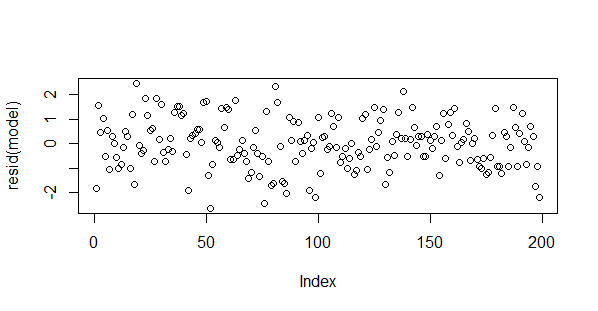
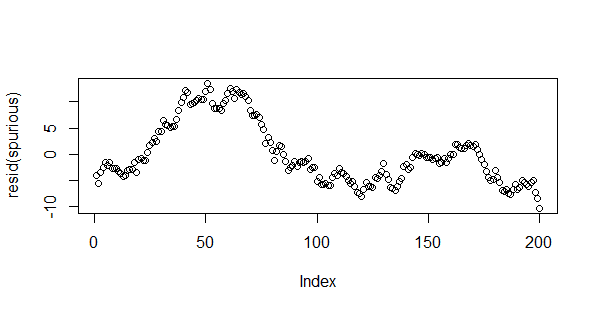
You can also use the plot(model) command to examine the residuals in detail. There you have it. Time series correlation and regression are famous last words. The Redneck equivalent of, "here hold my beer and watch this".
To leave a comment for the author, please follow the link and comment on their blog: Fear and Loathing in Data Science.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.