
Searching for Structure underlying Customer Satisfaction Ratings: Item Response Theory through the Back Door
[This article was first published on Engaging Market Research, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Variations on a Theme of Negative Skew and Positive Manifold
No one familiar with research on customer satisfaction expects to find uncorrelated ratings or symmetric distributions centered toward the middle of the rating scale. There are forces at work that structure the means and correlations among the items from a customer satisfaction questionnaire. On the one hand, unsatisfied customers churn, so that the remaining customer base tends to be more likely to use the upper categories of the rating scale (negative skew). On the other hand, product-service experiences and perceptions mutually reinforce each other so that all the items become highly correlated (positive manifold).
Regrettably, summaries, such as the one above, although accurate, seem somewhat abstract and not particularly informative. They become meaningfully, however, as soon as we analyze some actual rating data. Still, toy data sets can pose a problem because they seldom capture the complexity of real data. Customer satisfaction provides a fortunate exception where we can learn a great deal from a rating scale with as few as three items.
I have presented below the grouped frequency table from over 4000 respondents who completed three ratings from a longer customer satisfaction questionnaire. Each item asked for a satisfaction rating on a different aspect of the personal service they received from employees. The measure used an ordered set of categories ranging from 1 = very unsatisfied to 5 = very satisfied. Although there are a lot of rows, this is the easiest way to display all the data (i.e., there are no other response patterns for the three service ratings). More importantly, it is the only way to show the concentration of respondents in only a few response patterns. I contend that all customer satisfaction rating follow this pattern to a greater or lesser extent. Thus, it is worth our time to study the 80 unique response patterns to these three items.
Service_1 | Service_2 | Service_3 | Proportion of Respondents | Total Score | Latent Trait Score |
1 | 1 | 1 | 0.0007 | 3 | -2.98 |
1 | 1 | 2 | 0.0002 | 4 | -2.64 |
3 | 1 | 1 | 0.0002 | 5 | -2.59 |
2 | 1 | 2 | 0.0002 | 5 | -2.55 |
1 | 2 | 1 | 0.0002 | 4 | -2.49 |
1 | 1 | 3 | 0.0004 | 5 | -2.48 |
4 | 1 | 1 | 0.0002 | 6 | -2.43 |
2 | 2 | 1 | 0.0004 | 5 | -2.43 |
5 | 1 | 1 | 0.0011 | 7 | -2.41 |
2 | 1 | 3 | 0.0002 | 6 | -2.40 |
1 | 2 | 2 | 0.0004 | 5 | -2.33 |
2 | 2 | 2 | 0.0016 | 6 | -2.29 |
3 | 2 | 1 | 0.0011 | 6 | -2.28 |
4 | 1 | 2 | 0.0002 | 7 | -2.20 |
3 | 2 | 2 | 0.0011 | 7 | -2.15 |
2 | 2 | 3 | 0.0011 | 7 | -2.13 |
4 | 2 | 1 | 0.0002 | 7 | -2.13 |
5 | 2 | 1 | 0.0007 | 8 | -2.09 |
4 | 2 | 2 | 0.0004 | 8 | -2.00 |
2 | 2 | 4 | 0.0009 | 8 | -2.00 |
3 | 2 | 3 | 0.0025 | 8 | -1.98 |
2 | 2 | 5 | 0.0002 | 9 | -1.97 |
5 | 2 | 2 | 0.0002 | 9 | -1.96 |
3 | 3 | 1 | 0.0007 | 7 | -1.93 |
3 | 1 | 4 | 0.0002 | 8 | -1.92 |
4 | 1 | 3 | 0.0002 | 8 | -1.87 |
3 | 3 | 2 | 0.0018 | 8 | -1.82 |
3 | 2 | 4 | 0.0007 | 9 | -1.76 |
4 | 2 | 3 | 0.0004 | 9 | -1.75 |
2 | 3 | 3 | 0.0018 | 8 | -1.74 |
3 | 2 | 5 | 0.0004 | 10 | -1.70 |
4 | 3 | 1 | 0.0002 | 8 | -1.65 |
5 | 2 | 3 | 0.0002 | 10 | -1.64 |
4 | 3 | 2 | 0.0029 | 9 | -1.58 |
3 | 3 | 3 | 0.0366 | 9 | -1.57 |
5 | 3 | 1 | 0.0009 | 9 | -1.51 |
5 | 3 | 2 | 0.0004 | 10 | -1.45 |
2 | 3 | 4 | 0.0007 | 9 | -1.45 |
3 | 4 | 1 | 0.0004 | 8 | -1.38 |
4 | 2 | 4 | 0.0002 | 10 | -1.36 |
4 | 3 | 3 | 0.0217 | 10 | -1.36 |
3 | 4 | 2 | 0.0011 | 9 | -1.34 |
3 | 3 | 4 | 0.0078 | 10 | -1.33 |
2 | 4 | 3 | 0.0002 | 9 | -1.25 |
5 | 3 | 3 | 0.0038 | 11 | -1.23 |
3 | 3 | 5 | 0.0016 | 11 | -1.22 |
3 | 4 | 3 | 0.0127 | 10 | -1.16 |
4 | 3 | 4 | 0.0076 | 11 | -1.11 |
4 | 4 | 1 | 0.0011 | 9 | -1.09 |
4 | 4 | 2 | 0.0036 | 10 | -1.07 |
4 | 4 | 3 | 0.0427 | 11 | -0.91 |
2 | 4 | 4 | 0.0004 | 10 | -0.90 |
4 | 3 | 5 | 0.0004 | 12 | -0.88 |
5 | 3 | 4 | 0.0011 | 12 | -0.88 |
3 | 4 | 4 | 0.0246 | 11 | -0.82 |
5 | 4 | 1 | 0.0004 | 10 | -0.71 |
5 | 4 | 2 | 0.0034 | 11 | -0.70 |
5 | 4 | 3 | 0.0089 | 12 | -0.56 |
3 | 5 | 3 | 0.0002 | 11 | -0.51 |
4 | 4 | 4 | 0.2093 | 12 | -0.47 |
3 | 4 | 5 | 0.0025 | 12 | -0.35 |
5 | 1 | 5 | 0.0002 | 11 | -0.29 |
5 | 3 | 5 | 0.0011 | 13 | -0.28 |
4 | 5 | 2 | 0.0004 | 11 | -0.22 |
4 | 5 | 3 | 0.0040 | 12 | -0.19 |
5 | 4 | 4 | 0.0494 | 13 | -0.17 |
4 | 4 | 5 | 0.0194 | 13 | -0.12 |
2 | 5 | 4 | 0.0002 | 11 | -0.11 |
3 | 5 | 4 | 0.0011 | 12 | -0.10 |
4 | 5 | 4 | 0.0404 | 13 | 0.05 |
5 | 5 | 1 | 0.0002 | 11 | 0.09 |
5 | 5 | 2 | 0.0002 | 12 | 0.09 |
5 | 5 | 3 | 0.0087 | 13 | 0.10 |
5 | 4 | 5 | 0.0085 | 14 | 0.12 |
1 | 5 | 5 | 0.0002 | 11 | 0.25 |
2 | 5 | 5 | 0.0002 | 12 | 0.25 |
3 | 5 | 5 | 0.0038 | 13 | 0.25 |
5 | 5 | 4 | 0.0769 | 14 | 0.31 |
4 | 5 | 5 | 0.0572 | 14 | 0.37 |
5 | 5 | 5 | 0.3088 | 15 | 0.86 |
As I have noted, even three items can produce a lot of possible combinations when each rating can take one of five possible values. We see only 80 of the 125 (= 5 x 5 x 5) possible combinations. We would have generated far fewer combinations except for the large number of respondents.
Had the three ratings been independent, we would have seen all 125 rows with approximately equal proportions. Then, we would be forced to keep track of all three ratings in order to describe any one respondent. Knowing how any one item was rated would tell us nothing about how any of the other items were rated. There would be no redundancy. Our data would lie uniformly over a three-dimensional space. But this is not so with these ratings.
The table is quite sparse, showing only a few combinations with any sizeable proportion of respondents. The last row is particularly informative. Almost 31% of more than 4000 respondents gave all top-box ratings, that is, all fives. The second highest proportion can be found some 20 rows up from the bottom of the table. Almost 21% assigned fours to all three ratings. Thirty-one percent gave all fives, and 21% gave all fours. In fact, more than three-quarters of the respondents use only the upper two categories for all three ratings. That’s redundancy!
We do not find respondents uniformly spread out over a three-dimensional space. Instead, the three ratings are highly correlated with Pearson correlations of 0.66, 0.51, and 0.70. They lie along a first principal component accounting for 75% of the total variation. This is what we mean by the term “positive manifold.” We begin believing that we will need all three ratings to describe a respondent adequately. Instead, we find our respondents falling along a single dimension, which can be represented using the sum of the three ratings or the first principal component score or the latent trait derived from an item response model (to be discussed later in this post).
Using the sum of the three ratings as the total score, we can see the distribution of our 80 rows in the following density plot. The two peaks represent the large proportion giving all fours or all fives.
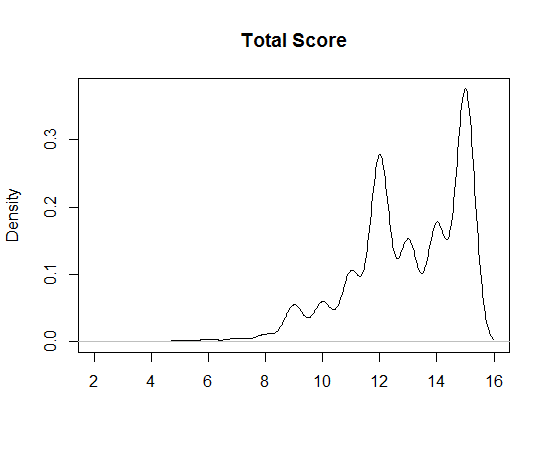
We can also see the negative skew for each rating by looking at the marginal distributions in the following table.Proportions for each level of response: | |||||
1 | 2 | 3 | 4 | 5 | |
Service_1 | 0.002 | 0.008 | 0.101 | 0.413 | 0.475 |
Service_2 | 0.004 | 0.013 | 0.091 | 0.389 | 0.503 |
Service_3 | 0.009 | 0.018 | 0.147 | 0.422 | 0.405 |
As with all satisfaction scores, the ratings tend to concentrate in the upper categories. Partially, it is a process of elimination. Unhappy customers switch providers leaving a relatively more satisfied customer base. Some products do take hostages. When switching costs are high or little else is available, a small group of dissatisfied cannot exit. But generally, customers who remain customers tend to be satisfied.
We tend to see the same pattern of negative skew and positive manifold in all customer satisfaction data. Product and service experience is certainly one source of this response pattern. Some customers will have problems. It could be an unresolved billing issue, or a service delivery failure, or special needs beyond the average customer. As long as they remain customers, they will form a customer segment at the lower end of the satisfaction continuum and tend to give uniformly lower ratings across all the items. However, it is unlikely that this low-end response pattern is due solely to experience. The rating process itself intensifies this effect. One low rating makes subsequent low ratings more likely. The recall of one negative experience biases the memory retrieval process for all the remaining items. Thinking is an associative process.
And what about the other end of the scale, those giving all top-box ratings? As the number of items increase, this proportion of respondents will decrease, but there will always be a “hump” for the highest possible score. It is, as if, a segment of respondents had a different agenda. During debriefing, we learn that these loyal customers are very satisfied and want you to know it. They use the rating scale as a communication device. However, there are limits. Increasing the number of categories from five to ten will reduce the number of top-box raters; nevertheless, the “hump” will remain. As a result of such dynamics in the product-service experience and the rating process itself, the customer base appears to be a mixture of three segments: the loyal, the more-or-less satisfied, and the hostage.
What does this have to do with item response theory?
Now that we have cracked open the back door, let’s see if we can sneak some item response theory into the discussion. We can start with the last column in our 80-row response pattern table. It is labeled as “latent trait score” because it is the latent variable derived from one of the many models covered by item response theory. Ignoring for the moment how this score was derived, we can examine its relationship to the total score.
In general, higher total scores are associated with larger latent trait scores. In fact, the linear correlation is 0.989, but the relationship is not linear (as shown below in the scatterplot for the 80 rows from our response pattern table). You should note that this is a common finding: the total score and the latent trait have a Pearson r in the upper 0.90s and the graph is more S-shaped (ogive) than a straight line.

The total score, calculated as the sum of the separate items, treats the rating scale as interval and gives equal weight to each item. As a result, one could obtain the same total score with different ratings on different items. For example, as you can see from the scatterplot, there are three different response patterns associated with the total score of 14 (5,4,5; 5,5,4; and 4,5,5). You can see these response patterns toward the end of our grouped frequency table. Should we be concerned how a respondent obtained a score of 14? It does not matter when we calculate the total score, but it makes a difference when we compute the latent trait. Perhaps we need to take a step back and ask what we are trying to achieve.
We are trying to measure individual differences in customer satisfaction. Specifically, we are attempting to differentiate among customers by asking them to rate their satisfaction with different aspects of their product-service experiences. We have good reason to believe that there are sufficient constraints on the item ratings to justify treating customer satisfaction as a single latent dimension. Because all the items are measuring the same construct, we can calculate an overall satisfaction score as a function of the separate items.
What should that function be? First, a sum or a mean gives equal weight to all the items as if all the items were equally good indicators of customer satisfaction. That does not seem quite right. Perhaps we want a function that takes into consideration the contribution that each item makes to the definition of the overall customer satisfaction score. That is, some type of differential weighting of the items, not unlike factor loadings or factor score coefficients. Second, a sum or a mean utilizes whatever scale was employed to collect the data. A rating scale is assumed to be equal interval, as in this case where the scale was one to five. However, what if we wanted to form an overall satisfaction score using items with different scales, for example, combining binary checklists with 5-point satisfaction and 10-point performance ratings? Or, what if the items have very different distributions so that some items are “easy” with high proportions of respondents giving top-box ratings and other items are more “difficult” with low proportions of respondents giving top-box ratings? Does it make sense that a rating of five should indicate the same level of customer satisfaction for “easy” and “hard” items?
Now we are thinking like item response theorists. We have rejected the common practice of simply including items that seem to be measuring customer satisfaction, adding up or calculating the mean of the resulting scores, and then hoping for the best. Item response theory (IRT) demands evidence that the items cohere and measure a single latent dimension. IRT proposes an item response model that specifies the relationship between the latent dimension and each rating item. The data are used to estimate the parameters of the item response model, and in the process we learn a good deal about how well our items “work” plus where individual respondents fall along the latent trait.
In this particular example, I used the r package ltm and the graded response model to generate the latent trait scores in the last column of the response pattern table. We will have to wait for a later post to learn about the details of that process. This post is IRT through the back door. The focus was on looking at the response patterns for real customer satisfaction ratings. Hopefully, you have seen how the ratings are not spread over the three-dimensional item space but concentrated in a few response patterns lying in one-dimensional manifold. Moreover, even with only three items, we have been able to demonstrate with a density plot that our customer base may be a mixture of three segments with different types of product-service experiences and that this mixture creates a negative skew in the distribution of customer satisfaction.
In the next post I will add some more items, show the R-code from the ltm package, and present a more complete IRT analysis using the graded response model (grm). To learn more, you might want to read a previous post introducing a binary IRT model (Item Response Theory: Developing Your Intuition). Meanwhile, I find that questions, observations or suggestions are extremely helpful. Feel free to email or comment below.
To leave a comment for the author, please follow the link and comment on their blog: Engaging Market Research.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.