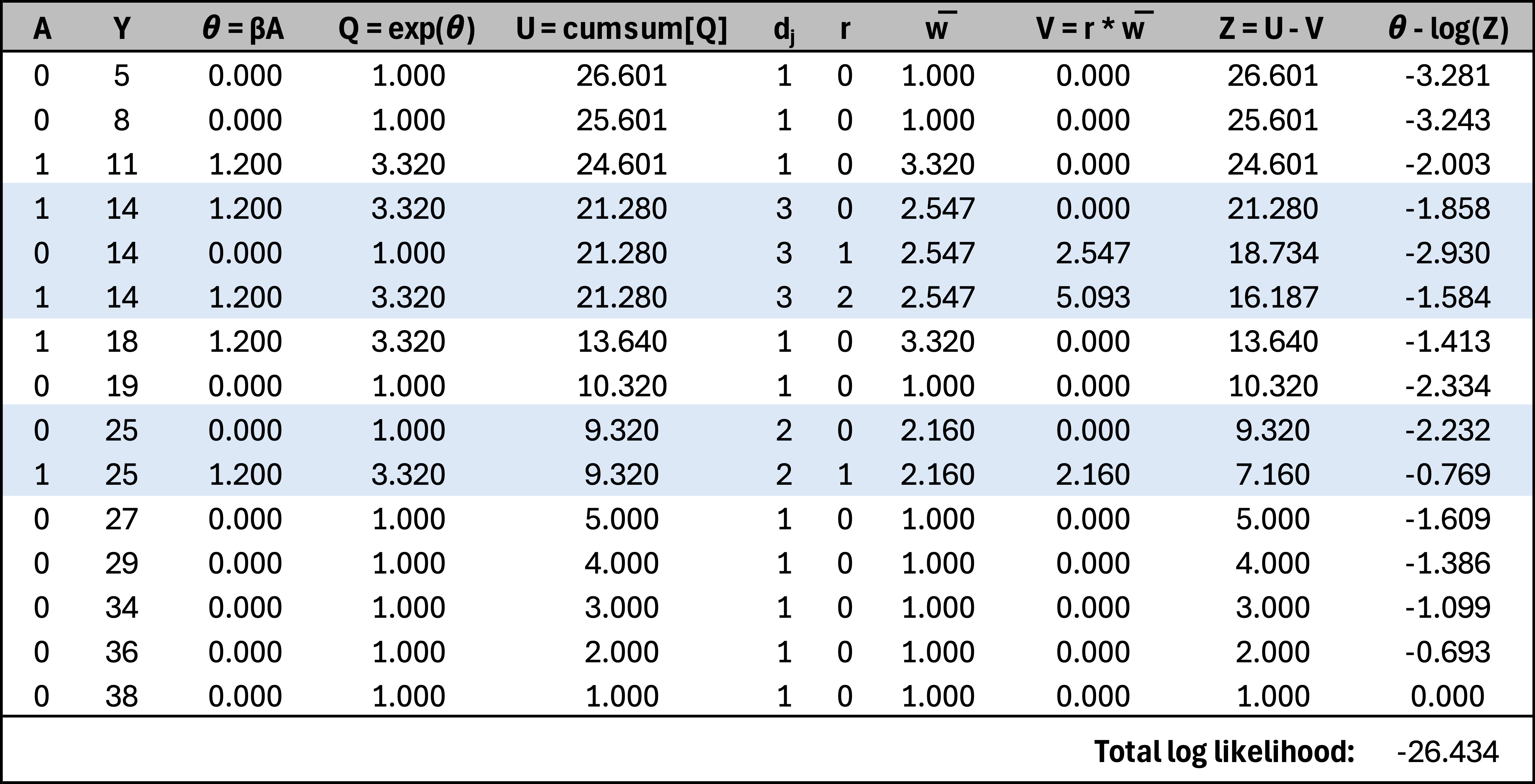
Accounting for ties in a Bayesian proportional hazards model
Over my past few posts, I’ve been progressively building towards a Bayesian model for a stepped-wedge cluster randomized trial with a time-to-event outcome, where time will be modeled using a spline function. I started with a simple Cox proportional...