
NIR "Cross Validaton Statistics" with "R"
[This article was first published on NIR-Quimiometría, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
We have to check different options before to decide for one model:
Configure different cross validations.
Configure different math treatments.
Configure number of terms.
With the Yarn NIR data, I have develop 4 models, for a simple exercise.
Of course we can check many combinations.
As math treatment I choose the raw spectra and the spectra treated with MSC. Other treatment as SNV, derivatives… can be applied.
>gas1.loo<-plsr(octane~(NIR),ncomp=10,
+ data=gasTrain,validation=”LOO”)
>gas1msc.loo<-plsr(octane~msc(NIR),
+ ncomp=10,data=gasTrain,validation=”LOO”)
>gas1.cv5<-plsr(octane~(NIR),ncomp=10,
+ data=gasTrain,validation=”CV”,
+ segment.type=”consecutive”,length.seg=5)
>gas1msc.cv5<-plsr(octane~msc(NIR),ncomp=10,
+ data=gasTrain,validation=”CV”,
+ segment.type=”consecutive”,length.seg=5)
Now let´s have a look to the statistics:
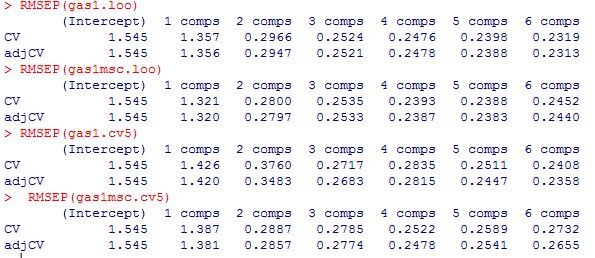
We have the cross validation error (CV) for each model for the different number of components (terms), and the CV error bias corrected (adjCV).
Which is the best option?
We have to take in account some tips.
We don´t know the error of the reference method, but in theory the Model Error cannot be better than the “laboratory error” for this constituent.
A Model works normally better with fewer terms (more robust). It does not make any good to improve a few, in the cross validation statistic, by adding one or more terms.
It´s good to have an independent test set apart from the CV to decide the best option.
Cross Validation is an important tool to decide the number of terms and not commit “over-fitting” or “under-fitting”.
As we can see there are not a great improvement applying MSC in this case, that is an indication that there are little scatter in this data.
To leave a comment for the author, please follow the link and comment on their blog: NIR-Quimiometría.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.