
Comparing pipes: Base-R |> vs {magrittr} %>%
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Beginners are sometimes confused by the fact that
- some R users use the native Base R pipe
|>and - others use the
{magrittr}pipe%>%.
So in today’s video, I want to compare the two and show you the strengths and weaknesses of each one. Let’s dive in.
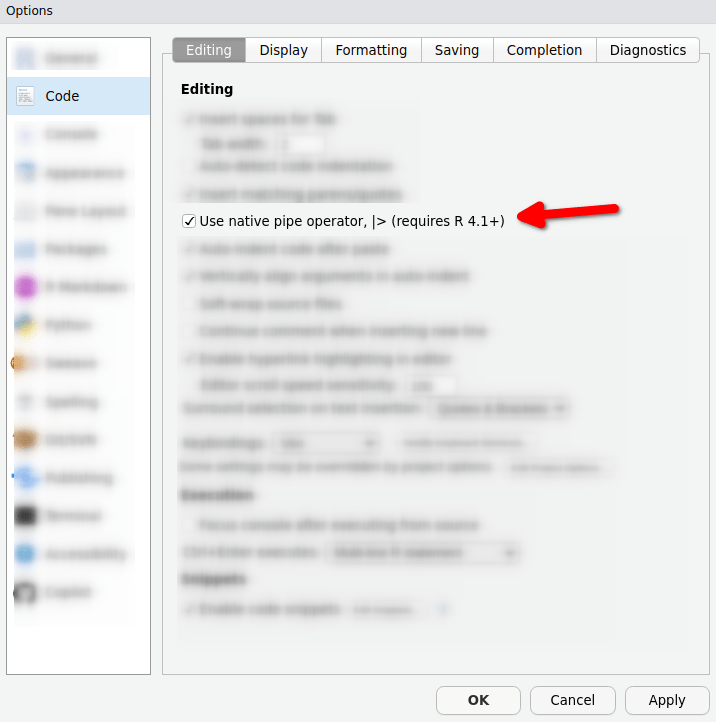
Keyboard shortcut
Whatever pipe you use, you should definitely use the RStudio shortcut ctrl + shift + M. This is much quicker than writing it out. By default, this will throw the {magrittr} pipe. But you can change that in the settings.
Simple function chaining
The big advantage of the base-R pipe is that it can easily chain together a couple of functions whether any packages are loaded or not.
runif(100) |> round() |> mean() ## [1] 0.48
The same doesn’t work with the {magrittr} pipe because I have to load the package first.
runif(100) %>% round() %>% mean() ## Error in runif(100) %>% round() %>% mean(): could not find function "%>%"
But if I do load something like the Tidyverse that contains {magrittr} it works fine.
library(tidyverse) ## ── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ── ## ✔ dplyr 1.1.4 ✔ readr 2.1.5 ## ✔ forcats 1.0.0 ✔ stringr 1.5.1 ## ✔ ggplot2 3.5.1 ✔ tibble 3.2.1 ## ✔ lubridate 1.9.3 ✔ tidyr 1.3.1 ## ✔ purrr 1.0.2 ## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ── ## ✖ dplyr::filter() masks stats::filter() ## ✖ dplyr::lag() masks stats::lag() ## ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors runif(100) %>% round() %>% mean() ## [1] 0.53
Form strictness
The nice thing about the {magrittr} pipe is that it isn’t as strict as the base-R pipe. For example, {magrittr} allows you to forget function calls and just use the function name.
runif(100) %>% round # works runif(100) |> round # Error function call with () is enforced ## Error: The pipe operator requires a function call as RHS (<text>:2:15)
Standard scenario
I don’t think the strictness is much of a disadvantage, though. In most cases (at least in my 90% of pipe use cases), you’ll likely use the pipe with something like mutate() where you specify additional arguments anyway. In that scenario, both pipes work pretty much the same.
dat_with_super_long_name <- tibble(x = 1:3, y = 10:12) dat_with_super_long_name |> mutate(z = x + y) ## # A tibble: 3 × 3 ## x y z ## <int> <int> <int> ## 1 1 10 11 ## 2 2 11 13 ## 3 3 12 15 dat_with_super_long_name %>% mutate(z = x + y) ## # A tibble: 3 × 3 ## x y z ## <int> <int> <int> ## 1 1 10 11 ## 2 2 11 13 ## 3 3 12 15
Using a placeholder
Fans of the original {magrittr} pipe will tell you that it’s really cool to use the . operator as a placeholder. Rightfully so, this is a neat feature.
dat_with_super_long_name %>% lm(y ~ x, data = .) ## ## Call: ## lm(formula = y ~ x, data = .) ## ## Coefficients: ## (Intercept) x ## 9 1
Initially, the base-R pipe could not pull of such a stunt. However, since R 4.3.0. it has a placeholder too.
dat_with_super_long_name |> lm(y ~ x, data = _) ## ## Call: ## lm(formula = y ~ x, data = dat_with_super_long_name) ## ## Coefficients: ## (Intercept) x ## 9 1
Using multiple placeholders
At this point, fans of the . operator will shout “The dot operator is even cooler. It can be used multiple times!” And they are absolutely right about that. That’s pretty dope.
And for the unenlightened: By wrapping a subsequent function call into {}, you can use the . operator as many times as you’d like over there. In each instance, . will then represent the data that went into {}.
dat_with_super_long_name %>% {plot(.$x, .$y, cex = 3, lwd = 5)}

Sadly, the base pipe cannot do such a thing. Its strictness forbids {}.
## Error: { not allowed
dat_with_super_long_name |> {plot(_$x, _$y, cex = 3, lwd = 5)}
## Error: function '{' not supported in RHS call of a pipe (<text>:2:29)
A workaround for that would be to
- define an anonymous function with
\(.), - wrap that into parentheses, and then
- call that function.
dat_with_super_long_name |> (\(.) plot(.$x, .$y, cex = 3, lwd = 5))()
Shoutout to Isabella Velásquez’s blog post that taught me about this little trick.
Conditional flows
Now, sometimes people like to use if-statements in their pipe-chains. By combining the {magrittr} pipe with curly brackets and the . operator, this could look like this.
duplicate_flag <- TRUE
duplicates <- tibble(x = 1:3, z = 21:23)
dat_with_super_long_name %>%
{
if (duplicate_flag) {
. |> left_join(duplicates, by = 'x')
} else {
.
}
} %>%
summarize(across(everything(), mean))
## # A tibble: 1 × 3
## x y z
## <dbl> <dbl> <dbl>
## 1 2 11 22
duplicate_flag <- FALSE
duplicates <- tibble(x = 1:3, z = 21:23)
dat_with_super_long_name %>%
{
if (duplicate_flag) {
. |> left_join(duplicates, by = 'x')
} else {
.
}
} %>%
summarize(across(everything(), mean))
## # A tibble: 1 × 2
## x y
## <dbl> <dbl>
## 1 2 11
In the past, I have written code like this too. Nowadays, though, I try to break out such things into their own functions. Preferably, one with a descriptive function name.
That way,
- the base-R pipe can handle this much better,
- my original chain hopefully stays short, and
- when I outsource the helper functions to a separate script, the function name hopefully still tells me what it does.
left_join_if_duplicate <- function(dat, duplicate_flag) {
if (duplicate_flag) {
dat |> left_join(duplicates, by = 'x')
} else {
dat
}
}
duplicate_flag <- TRUE
dat_with_super_long_name |>
left_join_if_duplicate(duplicate_flag) |>
summarize(across(everything(), mean))
## # A tibble: 1 × 3
## x y z
## <dbl> <dbl> <dbl>
## 1 2 11 22
left_join_if_duplicate <- function(dat, duplicate_flag) {
if (duplicate_flag) {
dat |> left_join(duplicates, by = 'x')
} else {
dat
}
}
duplicate_flag <- FALSE
dat_with_super_long_name |>
left_join_if_duplicate(duplicate_flag) |>
summarize(across(everything(), mean))
## # A tibble: 1 × 2
## x y
## <dbl> <dbl>
## 1 2 11
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.