
relgam: Fitting reluctant generalized additive models
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
I’m proud to announce that my latest research project, reluctant generalized additive modeling (RGAM), is complete (for now)! In this post, I give a brief overview of the method: what it is trying to do and how you can fit such a model in R. (This project is joint work with my advisor, Rob Tibshirani.)
- For an in-depth description of the method, please see our arXiv preprint.
- You can download the CRAN version of the package,
relgam, here. The latest version of the package is on Github. - For more details on how to use the package, please see the package’s vignette.
Introduction and motivation
tl;dr: Reluctant generalized additive modeling (RGAM) produces highly interpretable sparse models which allow non-linear relationships between the response and each individual feature. However, non-linear relationships are only included if deemed important in improving prediction performance. RGAMs working with quantitative, binary, count and survival responses and is computationally efficient.
Consider the supervised learning setting, where we have 




")


 = \sum_{j=1}^p \beta_j X_j +\epsilon, \end{aligned}")
where 

 = \sum_{j=1}^p f_j(X_j) +\epsilon, \end{aligned}")
where the 
These two classes of models include all
While providing sparsity, these methods dictated that the features included had to have a non-linear relationship with the response even if a linear relationship would have been sufficient to capture the relationship. More sophisticated methods were developed to give both sparsity and the possibility of linear or non-linear relationships between the features and response. Examples of such methods are GAMSEL (Chouldechova & Hastie 2015), SPLAM (Lou et al. 2016) and SPLAT (Petersen & Witten 2019). GAMSEL is available on R in the gamsel package (see my unofficial vignette here) and I was not able to find R packages for the other two methods.
Reluctant generalized additive models (RGAM) fall in the same class as these last group of methods. It is available on R in the relgam package. RGAMs are computationally fast and work with quantitative, binary, count and survival response variables. (To my knowledge, existing software only works for quantitative and binary variables.)
RGAM: What is it?
Reluctant generalizing additive modeling was inspired by reluctant interaction modeling (Yu et al. 2019). The idea is that
One should prefer a linear term over a non-linear term if all else is equal.
That is, we prefer a model to contain only effects that are linear in the original set of features: non-linearities are only included thereafter if they add to predictive performance.
We operationalize this principle with a three-step process that closely mimics that of reluctant interaction modeling. At a high level:
- Fit the response as well as we can using only the main effects (i.e. original features).
- For each original feature
, construct a non-linear feature associated with it.
- Refit the response on all the main effects and the additional features from Step 2.
Now for a little bit more detail:
- Fit the lasso of
on
to get coefficients
. Compute the residuals
, using the
hyperparameter chosen by cross-validation.
- For each
, fit a smoothing spline with
degrees of freedom of
on
. Rescale
. Let
denote the matrix whose columns are the
- Fit the lasso of
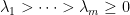
A simple example
The CRAN vignette is the best place to start learning how to fit RGAMs in practice. Below I give an example of the types of models that can come out of RGAM. (Code for this example can be found here.)
We simulate data with 

 + \left( -2X_5^2 + 2 \right) + \frac{1}{2}X_6^3 + \epsilon. \end{aligned}")
We fit a RGAM to this data for a sequence of
For each
 \right). \end{aligned}")
Let  = \hat{\beta}_j X_j + \hat{f}_j (X_j)")



For small
Give it a try!
I think RGAM is a neat extension to GAM and other sparse additive models. It may not always perform best but I think it is a nice tool to add to your arsenal of interpretable models to try for supervised learning problems!
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.