
Critique of “Projecting the transmission dynamics of SARS-CoV-2 through the postpandemic period” — Part 4: Modelling R, seasonality, immunity
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
In this post, fourth in a series (previous posts: Part 1, Part 2, Part 3), I’ll finally talk about some substantive conclusions of the following paper:
Kissler, Tedijanto, Goldstein, Grad, and Lipsitch, Projecting the transmission dynamics of SARS-CoV-2 through the postpandemic period, Science, vol. 368, pp. 860-868, 22 May 2020 (released online 14 April 2020). The paper is also available here, with supplemental materials here.
In my previous post, I talked about how the authors estimate the reproduction numbers (R) over time for the four common cold coronavirus, and how these estimates could be improved. In this post, I’ll talk about how Kissler et al. use these estimates for R to model immunity and cross-immunity for these viruses, and the seasonal effects on their transmission. These modelling results inform the later parts of the paper, in which they consider various scenarios for future transmission of SARS-CoV-2 (the coronavirus responsible for COVID-19), whose characteristics may perhaps resemble those of these other coronaviruses.
The conclusions that Kissler et al. draw from their model do not seem to me to be well supported. The problems start with the artifacts and noise in the proxy data and R estimates, which I discussed in Part 2 and Part 3. These issues with the R estimates induce Kissler et al. to model smoothed R estimates, which results in autocorrelated errors that invalidate their assessments of uncertainty. The noise in R estimates also leads them to limit their model to the 33 weeks of “flu season”; consequently, their model cannot possibly provide a full assessment of the degree of seasonal variation in R, which is one matter of vital importance. The conclusions Kissler et al. draw from their model regarding immunity and cross-immunity for the betacoronavirues are also flawed, because they ignore the effects of aggregation over the whole US, and because their model is unrealistic and inconsistent in its treatment of immunity during a season and at the start of a season. A side effect of this unrealistic immunity model is that the partial information on seasonality that their model produces is biased.
After justifying these criticisms of Kissler et al.’s results, I will explore what can be learned using better incidence proxies and R estimates, and better models of seasonality and immunity.
The code I use (written in R) is available here, with GPLv2 licence.
The model Kissler et al. fit, and its interpretation
I’ll start by presenting what Kissler et al. did in their paper — how they modelled R for the common cold coronaviruses, how they interpreted the results of fitting their model, and how they think it might relate to SARS-CoV-2 (the virus causing COVID-19). The paper focuses on the two betacoronaviruses that cause common colds — OC43 and HKU1 — since SARS-CoV-2 is also a betacoronavirus.
Kissler et al. model log(R) for each virus, for each of the 33 weeks of each year’s “flu season” — from week 40 of a year (early October) to week 20 of the next year (mid May). Here, R is the smoothed estimate of Ru, as I discussed in Part 3 of this series (I’ll refer to this as just R, for brevity, and because I’ll consider other R estimates later). They use a simple linear regression model for log(R), fit by least squares, with the following covariates:
- Indicators for each season and virus, whose coefficients will give the values of R for each virus at the start of each season.
- A set of 10 spline segments, used to model the change in R due to seasonal effects (assumed the same for all years, and for both viruses).
- The cumulative incidence of the virus for which log(R) is being modelled, within the current season (using the chosen incidence proxy). This cumulative incidence is seen as a measure of the “depletion of susceptibles” due to immunity.
- The cumulative incidence of the other virus, within the current season. This is seen as allowing the model to capture cross-immunity due to infection by the other common cold betacoronavirus.
Here Fig. 1 from their paper, showing the effects of these components of the model, using the regression coefficients fitted to the data (click for larger version):

These plots show the multiplicative effects on R, derived from the additive effects on log(R) in the linear regression model. The gold line shows the seasonal effect. The red and blue lines are the “immunity” effects, for HKU1 and OC43 respectively. (Hence, for HKU1, red is the effect of immunity to HKU1, and the blue line is the effect of cross-immunity from infection with OC43, whereas for OC43, this is reversed, with red showing the cross-immunity effect from HKU1.) The black dot at the left is the initial R value, relative the value for HKU1 in 2014-2015. The plots include uncertainty bands for these effects.
I have replicated these results (except for the uncertainty bands). Below are my plots analogous to those above (click for larger version):

The two columns on the left above have plots of the multiplicative effects of each model component, corresponding to Kissler et al.’s plots. The two right columns show plots of the additive effects on log(R). The plots above also include the absolute level of the initial value of R (green dot), the total effect from all components in the model (red line), and the R estimates that the model was fitted to (pink dots, some of which may be off the plot). I plot the effect of cumulative seasonal incidence of the same virus as a black line, and the “cross-immunity” effect from cumulative seasonal incidence of the other virus as a grey line.
Kissler et al. truncated their plots at week 30 of flu season (as I discussed in Part 1). My plots above go to the end of the season (week 33).
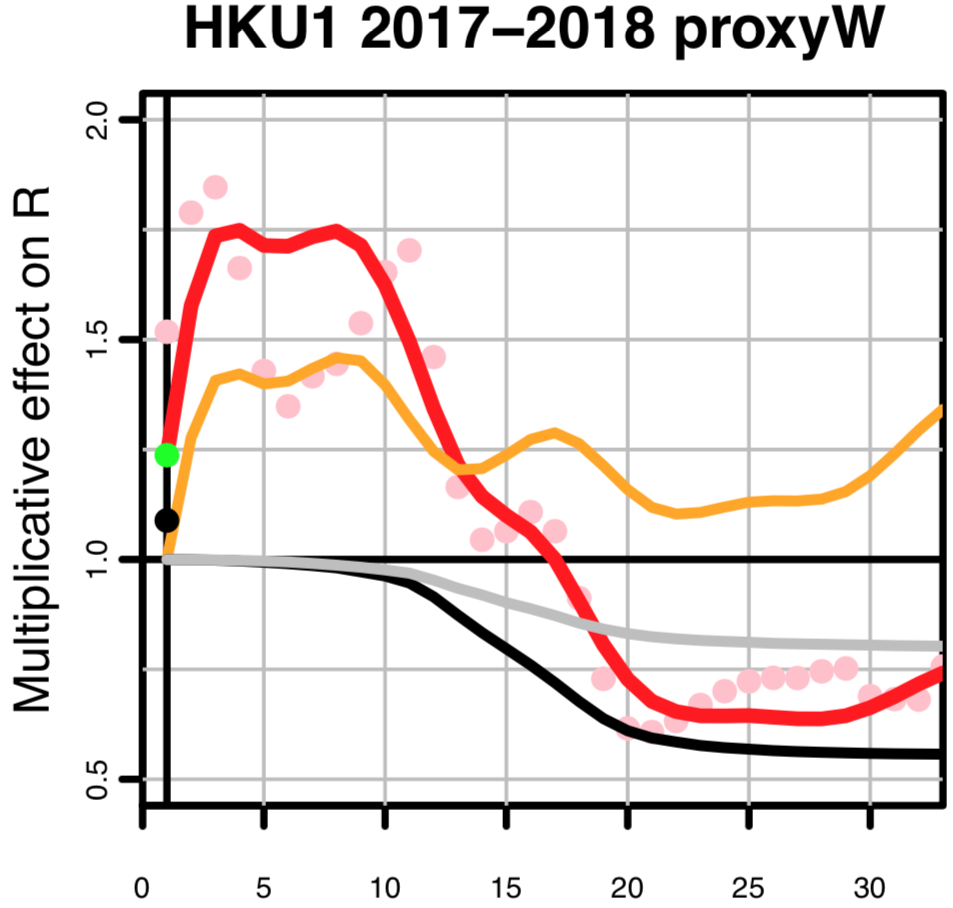
For closer examination, here is the portion of Kissler et al.’s Fig. 1 for HKU1 in the 2017-2018 season:

Model fitted by Kissler et al.
Here is the corresponding plot from my replication:
Replication of Kissler et al.’s model
One can see an exact correspondence, up to week 30. One can also see that truncating the plot at week 30 leaves out a significant rise in Kissler et al.’s estimate of the seasonal effect on R in the last three weeks.
Here are the regression coefficients from the model fit in my replication:
Estimate Std. Error HC3.se NW.se seasonal_spline1 0.45088 0.10610 0.22478 0.16287 seasonal_spline2 0.24535 0.08779 0.15137 0.23198 seasonal_spline3 0.48011 0.08539 0.16118 0.14166 seasonal_spline4 0.07054 0.08333 0.14408 0.16536 seasonal_spline5 0.35121 0.10858 0.16415 0.15480 seasonal_spline6 0.04285 0.14018 0.17968 0.20912 seasonal_spline7 0.14935 0.15413 0.19551 0.19489 seasonal_spline8 0.09484 0.16603 0.19778 0.25869 seasonal_spline9 0.25369 0.16668 0.20295 0.20424 seasonal_spline10 0.29357 0.15608 0.20286 0.21917 OC43_same -0.00187 0.00051 0.00044 0.00061 OC43_other -0.00076 0.00044 0.00039 0.00056 HKU1_same -0.00251 0.00044 0.00044 0.00060 HKU1_other -0.00133 0.00051 0.00048 0.00063 OC43_season_2014 0.06825 0.05986 0.12802 0.14079 OC43_season_2015 -0.01195 0.06320 0.13376 0.13974 OC43_season_2016 0.04066 0.06053 0.12648 0.14115 OC43_season_2017 0.06951 0.06569 0.12982 0.14785 OC43_season_2018 0.06298 0.06090 0.12586 0.13743 HKU1_season_2014 0.12779 0.05986 0.17615 0.16235 HKU1_season_2015 0.01084 0.06320 0.14456 0.15355 HKU1_season_2016 0.15110 0.06053 0.15803 0.15721 HKU1_season_2017 0.21279 0.06569 0.13662 0.14642 HKU1_season_2018 0.19568 0.06090 0.15752 0.15977 Residual standard deviation for OC43: 0.093 Residual ACF: 1 0.66 0.18 -0.05 0 0.06 -0.07 -0.26 -0.36 -0.3 -0.17 -0.08 Residual standard deviation for HKU1: 0.2061 Residual ACF: 1 0.55 -0.08 -0.29 -0.11 0 -0.07 -0.18 -0.13 0.02 0.14 0.08
Here, “same” and “other” refer to the immune effects of the same or the other virus. The coefficients above match those in Table S1 in the supplementary information for the Kissler et al. paper, except they use a different (but equivalent) parameterization in which values for OC43 and seasons other than 2014 are relative to HKU1/2014.
The standard deviation of the residuals of this model for HKU1 is over twice that for OC43. This is a problem, since the model fits data for the two viruses jointly, assuming a common value for the residual standard deviation. The error bands in Kissler et al.’s plot are found using a procedure that is supposed to adjust for differing residual variances — either the residuals having higher variance for HKU1 than OC43, or to their variance varying with time. These adjusted standard errors are shown in the HC3.se column. This adjustment has a substantial effect on the standard errors for the spline components, but not much effect on the standard errors for the immunity and cross-immunity coefficients. (I will talk about the NW.se column later.)
The 95% confidence bands for the immunity effects in Kissler et al.’s Fig. 1 correspond roughly to plus-or-minus twice the HC3 standard errors of the coefficients as shown above. For example, the coefficient of -0.00133 for cross-immunity of HKU1 to OC43 has a standard error of 0.00048, so the 95% confidence interval for the coefficient is approximately -0.00229 to -0.00037. The cumulative incidence of OC43 at the end of the 2017-2018 season was about 160. Exponentiating to get the multiplicative cross-immunity effect gives a range of exp(-0.00229*160) to exp(-0.00037*160), which is about 0.69 to 0.94, matching the end-of-season range in Kissler et al.’s plot.
Kissler et al. interpret the results of this model as follows:
As expected, depletion of susceptibles for each betacoronavirus strain was negatively correlated with transmissibility of that strain. Depletion of susceptibles for each strain was also negatively correlated with the Re of the other strain, providing evidence of cross-immunity. Per incidence proxy unit, the effect of the cross-immunizing strain was always less than the effect of the strain itself (table S1), but the overall impact of cross-immunity on the Re could still be substantial if the cross-immunizing strain had a large outbreak (e.g., HCoV-OC43 in 2014–2015 and 2016–2017). The ratio of cross-immunization to self-immunization effects was larger for HCoV- HKU1 than for HCoV-OC43, suggesting that HCoV-OC43 confers stronger cross-immunity. Seasonal forcing appears to drive the rise in transmissibility at the start of the season (late October through early December), whereas depletion of susceptibles plays a comparatively larger role in the decline in transmissibility toward the end of the season. The strain-season coefficients were fairly consistent across seasons for each strain and lacked a clear correlation with incidence in prior seasons, consistent with experimental results showing substantial waning of immunity within 1 year (15).
Later, discussing the results of using the same data to fit a SEIRS model (which I’ll discuss in a future post), they comment that
According to the best-fit model parameters, the R0 for HCoV-OC43 and HCoV-HKU1 varies between 1.7 in the summer and 2.2 in the winter and peaks in the second week of January, consistent with the seasonal spline estimated from the data. Also in agreement with the findings of the regression model, the duration of immunity for both strains in the best-fit SEIRS model is ~45 weeks, and each strain induces cross-immunity against the other, although the cross-immunity that HCoV-OC43 infection induces against HCoV-HKU1 is stronger than the reverse.
The summer/winter R0 ratio of 1.7/2.2=0.77 in this SEIRS model does indeed closely match the low/high ratio of seasonal effects in the regression model, which can be seen above to be approximately 1.1/1.45=0.76. And a duration of 45 weeks for immunity is consistent with the regression model’s assumption that immunity does not decline during the 33 week flu season, but is mostly gone by the start of the next season (19 weeks later), as evidenced by the range of coefficients for R at the start of a season (which would be affected by the degree of lingering immunity from the previous season) being only (-0.01195,0.06951) for OC43 and (0.01084,0.21279) for HKU1 (though the width of the latter range seems not completely negligible).
I summarize the conclusions Kissler et al. draw from this regression model as follows:
- Both betacoronaviruses induce immunity against themselves, but this immunity is mostly gone less than one year later.
- Both viruses also confer substantial cross-immunity against the other (larger for OC43 against HKU1 than the reverse), though this is not as strong as self-immunity.
- There is a seasonal effect on transmission, whose magnitude reduces R by a factor of about 0.76 in low season compared to the peak.
The model also produces an estimated curve for the seasonal effect (within flu season), but apart from pointing to its rise at the start of flu season as initiating seasonal outbreaks, Kissler et al. perhaps do not attach great significance to the detailed shape of this estimated curve, since the error bands they show around it are quite large. However, they do use this model as evidence regarding the overall magnitude of the seasonal effect, which, to the extent it might be indicative of seasonality for COVID-19, is of great practical importance.
Are these conclusions from the model valid?
Mostly no, I think. I don’t mean that the conclusions are necessarily all false (though some may be), just that, for several reasons, modelling the data that they use in the way that they do does not provide good evidence for their conclusions.
Some of the problems originate in the proxy they use for incidence of coronavirus infection. As I discussed in Part 2, their proxy, which I call proxyW, has artifacts due to holidays, some points affected by outliers, an issue with zero measurements, and noise that is best reduced by smoothing the incidence proxy rather than later. I proposed several proxies that seem better.
These problems with the incidence proxy influence estimation of weekly R values for each virus. I argued in Part 3 that modelling Rt is better than modelling Ru, because Ru depends on the future, obscuring the influences on transmissibility of the virus.
Furthermore, the handling of immunity in the regression model Kissler et al. fit would be appropriate for modelling Rt but not Ru — the cumulative seasonal incidence of each virus up to the current time is used as a covariate in the model, but Ru will be affected by the cumulative incidence (and consequent immunity) at later times. Because the generative interval distribution, g, that is used extends only 19 days (about two weeks) into the future, the effect of this modelling inaccuracy will not be huge, but it will tend to bias the estimation of immunity effects somewhat (probably towards overestimating the immunity effect).
Since Ru averages values of Rt at future times, due to the formula Ru = ∑t g(t-u)Rt (see Part 3), it is less noisy than Rt, which may have been a motivation to use it. To further reduce noise, Kissler et al. used a three-week moving average version of log(Ru).
If we try modelling Rt with Kissler et al.’s regression model, here is what we get for HKU1 in 2017-2018:

Model for Rt using proxyW
The artifacts and noise in the Rt estimates produce clearly ridiculous results, with strong negative cross-immunity, and a seasonal effect that has no resemblance to what we would expect.
The results of applying Kissler et al.’s model to the unsmoothed Ru are not so bad. Below is a comparison of Kissler et al.’s model for smoothed Ru values versus the same model for unsmoothed Ru values, using the 2017-2018 season as an example. Here and below, I’ll use plots for log(R) rather than R itself, since it is log(R) that the regression model works with.

Model for smoothed Ru using proxyW

Model for unsmoothed Ru using proxyW
The differences are noticeable, but not drastic. The rise in the seasonal effect at the start of the season is steeper with unsmoothed Ru values, so the whole seasonal curve is shifted up (partly compensated for by the green dot shifting down). The rise at the end of the season is even larger than before. The immunity and cross-immunity effects are slightly larger.
The results using the unsmoothed Ru values are a better guide to what this model is saying. These results are somewhat unexpected — rather than the sharp rise in the seasonal effect seen at the end of flu season, one might instead expect a drop, and the very steep rise at the beginning of the flu season is also odd, since nothing of apparent note happens then (schools open earlier). These oddities should prompt one to critically examine both the data and the assumptions behind the model. Somewhat obscuring the problems by using smoothed Ru values is not helpful.
Further insight comes from looking in detail at the estimates found using unsmoothed Ru values:
Estimate Std. Error HC3.se NW.se seasonal_spline1 0.57484 0.18245 0.31483 0.21023 seasonal_spline2 0.31601 0.15096 0.25117 0.29209 seasonal_spline3 0.58870 0.14684 0.20252 0.17467 seasonal_spline4 0.13309 0.14331 0.18339 0.20336 seasonal_spline5 0.48668 0.18671 0.18977 0.19179 seasonal_spline6 0.14439 0.24106 0.22037 0.23593 seasonal_spline7 0.27262 0.26504 0.23446 0.24860 seasonal_spline8 0.24716 0.28551 0.24667 0.27696 seasonal_spline9 0.31697 0.28663 0.25691 0.25880 seasonal_spline10 0.48711 0.26841 0.26182 0.27002 OC43_same -0.00204 0.00088 0.00063 0.00060 OC43_other -0.00090 0.00076 0.00056 0.00056 HKU1_same -0.00274 0.00076 0.00068 0.00066 HKU1_other -0.00145 0.00088 0.00074 0.00063 OC43_season_2014 -0.00951 0.10294 0.14988 0.16930 OC43_season_2015 -0.10040 0.10868 0.15427 0.16894 OC43_season_2016 -0.04292 0.10410 0.14776 0.16883 OC43_season_2017 -0.00409 0.11297 0.15312 0.17150 OC43_season_2018 -0.01522 0.10473 0.14967 0.16304 HKU1_season_2014 0.04350 0.10294 0.21745 0.21514 HKU1_season_2015 -0.07347 0.10868 0.16365 0.18131 HKU1_season_2016 0.05114 0.10410 0.20899 0.18428 HKU1_season_2017 0.14614 0.11297 0.16333 0.17836 HKU1_season_2018 0.11115 0.10473 0.20682 0.19546 Residual standard deviation for OC43: 0.1415 Residual ACF: 1 0.28 -0.23 -0.04 0.05 0.02 0.04 -0.15 -0.22 -0.12 -0.08 -0.03 Residual standard deviation for HKU1: 0.3622 Residual ACF: 1 0.17 -0.37 -0.17 0.03 0.08 -0.01 -0.13 -0.09 0.01 0.11 0.08
Notice that the estimate for cross immunity from OC43 to HKU1 (given by HKU1_other above) has increased slightly (compared to using smoothed Ru values), but its magnitude is now less than twice its standard error, and hence is not significant at the conventional 0.05 level — that is, by the conventional criterion, we cannot be confident that there actually is any cross-immunity. The estimate for cross immunity in the other direction, though again larger, is also less significant (it was marginal before), because its standard error is now larger.
When properly computed, the standard errors of estimates in the model for smoothed Ru values that Kissler et al. fit are also large enough that zero cross immunity (in either direction) is plausible. The residuals for that model have significant autocorrelation at lag one (0.66 for OC43, 0.55 for HKU1), which tends to increases the standard errors. The NW.se column has standard errors that account for autocorrelation (and differing variances), as found by the Newey-West method (implemented in the “sandwich” R package). With these larger standard errors, the estimate for cross-immunity from HKU1 to OC43 is not significant. The estimate for cross-immunity from OC43 to HKU1 is more than twice the Newey-West standard error, but not by much. (Methods for estimating standard errors when residuals are autocorrelated are somewhat unreliable, so one should not have high confidence in marginal results.)
The autocorrelations of the residuals are at least partly the result of fitting smoothed values for Ru — the smoothed values are averages over three weeks, with two of these weeks being common to two adjacent values, inducing autocorrelation. The estimated lag-one autocorrelations for residuals in the model of unsmoothed Ru values are much less (0.28 for OC43, 0.17 for HKU1).
Since the estimated cross-immunity effects are at most marginally significant, the conclusions Kissler et al. draw about cross-immunity do not seem justified.
The estimated curve for the seasonal effect on transmission seems rather strange. Perhaps the abrupt rises at the beginning and end of the flu season are artifacts of the handling of end-points by the spline procedure used (I have not investigated this enough to be sure). Or perhaps a strange result should not be seen as surprising, since the error bands for the seasonal effect curve in Kissler et al.’s Fig. 1 are quite large, and might be even larger if the effect of autocorrelation in the residuals were accounted for. But on that view, the uncertainty in the inferred seasonal effect is so large that no useful conclusions can be drawn.
Kissler et al.’s conclusion that each virus induces self-immunity might seem justified, since the estimates for OC43_same and HKU1_same are much bigger than twice their standard errors, when using either the smoothed or unsmoothed values for Ru, and with any of the methods used to compute standard errors. That these viruses induce some immunity is well supported from other evidence in any case. However, caution is warranted when using this model to judge the strength of immunity, or its duration. Using terms such as “depletion of susceptibles” and “self-immunity” in reference to covariates and regression coefficients in a model does not mean that these features of the model actually correspond to those concepts in reality.
The data being modelled is aggregated over the entire United States. On the NREVSS regional page, one can see the regional breakdown for positive common cold coronavirus tests in the last two years. For OC43, the peaks in the 2018-2019 season in the four regions occur on January 12 (Northeast), January 26 (Midwest), January 5 (South), and December 22 (West) — a spread of five weeks. The “depletion of susceptibles” in the West will have little influence on transmission in the Northeast. There must be geographical variation on a finer scale as well. It is therefore not safe to interpret the regression coefficient on “depletion of susceptibles” as an indication of strength of immunity.
The model used by Kissler et al. assumes that “immunity” persists undiminished during flu season, but that it is largely gone by the start of the next season. This seems implausible — why would immunity that had lasted for 20 or more weeks during the flu season be almost completely gone after another 19 weeks? More plausibly, the “immunity” (i.e., the regression coefficient on “depletion of susceptibles”) actually starts to decline during the flu season, not because the immune response of infected individuals declines, but because the locus of the outbreak moves from initially infected geographical regions to other regions, whose susceptibles have not yet been depleted. If a model does not include such a decline in “immunity”, the effect the decline would have had may be be produced instead by another component of the model. This may explain why the seasonal effect goes up after week 22 of the season (early March) — as a substitute for the “immune” effect becoming less. If this is happening, then the magnitude of the seasonal effect in Kissler et al.’s model underestimates the true seasonal effect.
Using better R estimates from better proxies
One way of trying to get more useful results than Kissler et al. do is to use better R estimates, based on better proxies for incidence of the betacoronaviruses, as I discussed in Part 2 and Part 3 of this series.
The proxyAXss-filter R estimates differ from the proxyW estimates by:
- Using the ratio of ILI visits to non-ILI visits as a proxy for Influenza-Like Illness rather than the (weighted) ratio of ILI visits to total visits.
- Removing artifacts due to holidays by interpolating from neighboring non-holiday weeks.
- Replacing some outliers in percent positive tests for coronaviruses by reasonable values.
- Replacing zero values for percent positive tests by reasonable non-zero values.
- Smoothing the percentage of positive tests for coronaviruses due to each virus.
- Applying a smoothing filter to the proxies after interpolating to daily values.
Modelling the unsmoothed Ru estimates from proxyAXss-filter gives the following results for 2017-2018:

Model for unsmoothed Ru using proxyAXss-filter
The sharp rises in the seasonal effect at the beginning of the season is less than for the model of unsmoothed Ru values with proxyW (shown above). There is some autocorrelation at lag one in the residuals (0.53 for both viruses), perhaps due to the smoothing done for the proxies (though Ru itself also involves smoothing). After accounting for this autocorrelation, the 95% confidence interval for the cross-immunity effect of OC43 on HKU1 overlaps with zero, and as can be seen (grey line) above, the estimate is closer to zero than for the previous models. The estimate for cross-immunity from HKU1 to OC43 is about the same as before, and is at best marginally significant.
Since proxyAXss-filter has less noise, somewhat reasonable results are obtained when modelling Rt:

Model for Rt using proxyAXss-filter
I described several other approaches to reducing noise in the proxies in Part 2. Here is a plot from a model using the proxyDn estimates for Rt:

Model for Rt using proxyDn
The estimates for this model are as follows:
Estimate Std. Error HC3.se NW.se seasonal_spline1 0.08769 0.06043 0.06199 0.03482 seasonal_spline2 0.14846 0.04995 0.04751 0.04079 seasonal_spline3 0.31573 0.04869 0.05294 0.05572 seasonal_spline4 0.08249 0.04499 0.05382 0.06426 seasonal_spline5 0.25449 0.05238 0.06374 0.08768 seasonal_spline6 -0.12442 0.06334 0.07115 0.11831 seasonal_spline7 -0.09949 0.06855 0.07913 0.13046 seasonal_spline8 -0.20727 0.07549 0.08118 0.13549 seasonal_spline9 -0.03293 0.07526 0.07716 0.12224 seasonal_spline10 -0.01487 0.06734 0.07468 0.13326 OC43_same -0.00123 0.00019 0.00018 0.00037 OC43_other -0.00047 0.00020 0.00026 0.00055 HKU1_same -0.00252 0.00020 0.00022 0.00040 HKU1_other 0.00002 0.00019 0.00018 0.00035 OC43_season_2014 0.14325 0.03397 0.04386 0.05663 OC43_season_2015 0.11544 0.03504 0.03894 0.04554 OC43_season_2016 0.11594 0.03423 0.03661 0.02958 OC43_season_2017 0.15530 0.03713 0.04109 0.05545 OC43_season_2018 0.18876 0.03579 0.03744 0.03144 HKU1_season_2014 0.03563 0.03397 0.04567 0.07521 HKU1_season_2015 0.11766 0.03504 0.04319 0.05390 HKU1_season_2016 0.02589 0.03423 0.03686 0.03899 HKU1_season_2017 0.29256 0.03713 0.03947 0.04218 HKU1_season_2018 0.10250 0.03579 0.03600 0.03676 Residual standard deviation for OC43: 0.09 Residual ACF: 1 0.63 0.31 0.22 0.12 0.03 -0.03 -0.12 -0.19 -0.22 -0.29 -0.34 Residual standard deviation for HKU1: 0.0922 Residual ACF: 1 0.63 0.31 0.21 0.09 -0.03 -0.09 -0.15 -0.17 -0.14 -0.14 -0.15
There is significant autocorrelation, due to the smoothing of proxies, so the Newey-West standard errors should be used.
The coefficient for cross-immunity from OC43 to HKU1 is virtually zero. The coefficient for cross-immunity from HKU1 to OC43 only about one standard error away from zero. This confirms that a model of the sort used by Kissler et al. provides no evidence of cross-immunity between the two betacoronaviruses, when it is properly fit to cleaned-up data. There is certainly no support for the claim by Kissler et al. that cross-immunity from OC43 against HKU1 is stronger than the reverse.
That this model fails to show cross-immunity is not really surprising. Because the data is aggregated over all regions of the United States, it is quite likely that many of those infected with one of the viruses are in regions where the other virus is not currently spreading. In the long term, both viruses might induce immunity in people in every region, and cross-immunity between might be evident in that context, but this model is sensitive only to cross-immunity on a time scale of a few months.
For HKU1, the estimated coefficients of the indicators of the five seasons differ quite a bit. Moreover, the largest coefficient, 0.29256 for the 2017-2018 season, follows the season with the smallest incidence for HKU1, as seen here:

The second highest coefficient, 0.11766 for the 2015-2016 season, follows the season with the second-smallest incidence. Contrary to the conclusions of Kissler et al., it seems quite plausible that these seasonal coefficients reflect the level of continuing immunity from the previous season.
Building a better model
To learn more from this data, we need to use a better model than Kissler et al.’s. I’ll confine myself here to models that mostly use the same techniques that Kissler et al. use — that is, linear regression models for log(R), fit by least squares.
Getting a better idea of the seasonal effect on transmission is important. To do this, the model must cover the whole year, including summer months when the seasonal reduction in transmission is perhaps at its strongest. The bias in estimation of the seasonal effect that can result from using an unrealistic “immunity” model also needs to be eliminated. Of course, a good model for immunity and cross-immunity is also of great interest in itself.
It’s easy to extend the “flu season” to the whole year — just set the season start to week 28 (early July) and the season end to week 27 of the next year. If that’s all that’s done, however, the results are ridiculous, since the model then assumes that immunity abruptly jumps to zero between week 27 and week 28.
I’ve tried several variations on more realistic models of immunity. Some of the more complex models that I tried did not work because their multiple factors cannot easily be identified from the data available, at least when working in the least-squares linear regression framework.
For example, I tried to correctly model that immunity should be represented by a term in the expression for log(R) of the form log(1-d/T), where d is a proxy for the number of immune people, and T is the total population, scaled by the unknown scaling factor for the proxy d. This corresponds the a multiplicative factor of (1-d/T) for R, which represents the decline in the susceptible population. If d/T is close to zero, log(1-d/T) will be approximately –d/T, and the model can be fit by including d as a covariate in the linear regression, with the regression coefficient found corresponding to -1/T. This is what is implicitly done in Kissler et al.’s model.
But when considering long-term immunity, assuming that d/T is close to zero seems unrealistic. I therefore tried including log(1-d/T) as a covariate, expecting its regression coefficient to be close to one, and then chose T by a search procedure to minimize the standard deviation of the model residuals. Unfortunately, there are too many ways that parameters in this model can trade-off against each other (e.g., T and the regression coefficient for log(1-d/T)), producing results in which these parameters do not take on their intended roles (even if the data is modelled well in terms of residual standard deviation). I therefore abandoned this approach, and am instead hoping that even if d/T is not small, its variation may be small enough that log(1-d/T) is approximatley linear in the region over which d/T varies.
The immunity model I tried that seems to work best assumes that there is both an “immunity” of short duration (actually caused by the data being aggregated over regions where infection spreads at different times) and long-term immunity (which is intended to represent widespread immunity in the population). Both forms of immunity are modelled using exponentially-weighted sums of the incidence proxies for each virus, but with different rates of decay in “immunity”. For short-term immunity, the incidence k weeks ago is given weight 0.85k, which corresponds to decay of immunity by a factor of two after 4 weeks. For long-term immunity, the weight for the incidence k weeks ago is 0.985k, which corresponds to decay of immunity by a factor of two after 46 weeks. These two exponentially weighted sums for a virus are included as covariates in the regression model for that virus, and the long-term sum is included as a covariate for the other virus, allowing cross-immunity to be modelled.
The way seasonality is modelled also needs to change, to avoid a discontinuity at the end of one full-year season and the beginning of the next. A periodic spline would be a possibility, but the bs function used in Kissler et al.’s R model does not have that option. I used a Fourier representation of a periodic seasonality function, including covariates of the form sin(2πfy) and cos(2πfy), where y is the time in years since the start of the data series, and f is 1, 2, 3, 4, 5, or 6. This seasonality model is common to both viruses.
Finally, I included a spline to model long term trends (e.g., change in population density), which is also common to both viruses, and a overall offset for each virus (same for all years). The long-term trend spline was limited to 5 degrees of freedom so that it will not be able take over the modelling of seasonality or immunity effects.
Here are the results of fitting this model using proxy data proxyEn-daily, which is the proxy with the most smoothing / least noise (see Part 3), for 2017-2018 (start of July to end of June):

Full-year model for Rt using proxyEn-daily
The dotted vertical lines show the start and end of “flu season”, to which the previous models were limited. The green line is the long-term trend; the dark green dot on the left is the overall offset for that virus. The solid black line is the short-term immunity effect; the dashed black line is the long-term immunity effect. The dashed grey line is the long-term cross-immunity effect. As before, the orange line is the seasonal effect, the red line is the sum of all effects, and the pink dots are the estimates for Rt that the red line is fitted to.
The estimated seasonal effect on log(R) has a low-to-high range of 0.44, which corresponds to R being 1.55 times higher in mid-November than in mid-June. The shape of the seasonal effect curve during the “flu season” is quite similar to the shape found using the model limited to flu season, with proxyDn estimates for Rt (shown above), though the range is slightly greater, and the rise at the end of flu season is smaller.
For both viruses, the plot shows both short and long term self-immunity effects. The plot shows some cross-immunity from HKU1 to OC43, but little indication of cross-immunity from OC43 to HKU1.
Here are the plots for all years, in both additive and multiplicative form (click for larger version):

Here are the estimates for the regression coefficients, and their standard errors:
Estimate Std. Error HC3.se NW.se trend_spline1 -0.07411 0.04928 0.05926 0.29550 trend_spline2 -0.06561 0.02890 0.03710 0.18423 trend_spline3 -0.09946 0.04761 0.06531 0.33427 trend_spline4 0.27051 0.03097 0.04304 0.23808 trend_spline5 0.02323 0.05161 0.08320 0.29286 sin(1 * 2 * pi * yrs) 0.11735 0.01395 0.01832 0.07656 cos(1 * 2 * pi * yrs) -0.16124 0.00625 0.00746 0.02524 sin(2 * 2 * pi * yrs) -0.02905 0.00580 0.00617 0.02275 cos(2 * 2 * pi * yrs) 0.02184 0.00476 0.00541 0.01813 sin(3 * 2 * pi * yrs) -0.00949 0.00422 0.00391 0.00681 cos(3 * 2 * pi * yrs) -0.01828 0.00430 0.00471 0.00860 sin(4 * 2 * pi * yrs) 0.01808 0.00414 0.00394 0.00785 cos(4 * 2 * pi * yrs) -0.02917 0.00419 0.00429 0.00722 sin(5 * 2 * pi * yrs) -0.01345 0.00412 0.00425 0.00560 cos(5 * 2 * pi * yrs) -0.00494 0.00417 0.00406 0.00527 sin(6 * 2 * pi * yrs) 0.01211 0.00412 0.00436 0.00509 cos(6 * 2 * pi * yrs) 0.00014 0.00416 0.00405 0.00290 OC43_same -0.00136 0.00020 0.00020 0.00071 OC43_samelt -0.00099 0.00019 0.00028 0.00097 OC43_otherlt -0.00098 0.00013 0.00020 0.00098 HKU1_same -0.00060 0.00024 0.00030 0.00104 HKU1_samelt -0.00208 0.00015 0.00019 0.00091 HKU1_otherlt -0.00021 0.00017 0.00022 0.00094 OC43_overall 0.52199 0.07282 0.10294 0.39844 HKU1_overall 0.37802 0.07037 0.09145 0.39340 Sum of OC43_same and OC43_samelt : -0.00235 NW std err 0.00095 Sum of HKU1_same and HKU1_samelt : -0.00268 NW std err 0.00082 Seasonality for week50 - week20 : -0.44075 NW std err 0.10621 Residual standard deviation for OC43: 0.0625 Residual ACF: 1 0.93 0.76 0.54 0.32 0.13 -0.01 -0.1 -0.15 -0.18 -0.21 -0.23 Residual standard deviation for HKU1: 0.0665 Residual ACF: 1 0.89 0.66 0.39 0.12 -0.08 -0.21 -0.26 -0.27 -0.24 -0.21 -0.17
There is substantial residual autocorrelation, so the Newey-West standard errors should be used.
Looking at the immunity coefficients individually, only HKU1_samelt has magnitude more than twice its standard error (OC43_same is close). This is somewhat misleading, however, since the short and long term immunity terms can trade-off against each other — a lower level of short-term immunity can be compensated to some extent by a higher level of long-term immunity, and vice versa. I computed the standard error for the sum of the short and long term coefficients, finding that for both viruses the magnitude of this sum is greater than twice its standard error, providing clear evidence that these viruses induce immunity against themselves.
The cross-immunity coefficients are much less than twice their standard error, so this model provides little or no evidence of cross immunity for these viruses.
As a robustness check, here is the same model fitted to the proxyAXss-filter data, which is less smoothed, with the minimal “fixups” needed to get reasonable results:

The curve for the seasonal effect is very similar to the fit using proxyEn-daily. The long-term immunity and cross-immunity effects look considerably different. Despite this, the red curve, giving the fitted values for log(R), is very similar. The changes in the immunity curves are mostly compensated for by changes in the offset for each virus (dark green dots) and in the long-term trend line (green) — the variation due to immunity and cross-immunity is similar.
As another robustness check, here are the results of applying the same model to the two alphacoronaviruses (click for larger version):

The seasonal effect for these viruses is similar to that for the betacoronaviruses. This is not a completely independent result, however, since some data is shared between the two virus groups in the construction of the proxies.
For further insight into the meaning of these estimates and standard errors, we can look at the incidence of these viruses, according to proxyEn:

For OC43, substantial peaks of incidence occur every year, but large peaks for HKU1 occur in only two of the five years. Because of this, the long-term exponentially-weighted incidence sum is more variable for HKU1 than for OC43, which means that more information is available about the immunity effects for HKU1 than for OC43.
It’s also important to keep in mind that there are only five years of data. Just from looking at the incidence plots above, one might think that the highest peak for HKU1, in 2017-2018, is a consequence of the almost non-existent peak in 2016-2017, which would result in fewer immune people the following year. However, the large 2017-2018 peak might also be caused in part by a generally increasing upward trend, which might also be discerned in the incidence for OC43. The possible trade-offs between these effects increase the uncertainty in inferring immunity and cross-immunity.
Beyond the formal indication of uncertainty captured by the standard errors, there is unquantified uncertainty stemming from the methods used to construct the proxies. These uncertainties could be captured formally only by a different approach in which the process by which the proxy data is produced is modelled in terms of latent processes, including the transmission dynamics of the viruses. There is also uncertainly stemming from my informal model selection procedure, which might be “overfitting” the data, or incorporating my preconceptions.
Taking these uncertainties into account, my conclusions from this modelling exercise are as follows:
- Both betacoronaviruses induce immunity against themselves. This immunity probably persists to a significant extent for at least one year. There is likely some apparent short-term immunity that is really a reflection of the fact that the data being modelled is aggregated over the entire United States.
- There may be some cross-immunity between the two betacoronaviruses, but this is not clearly established from this data.
- There is good evidence that the season affects transmissibility of these viruses. The 95% confidence interval for the ratio of the minimum to the maximum seasonal effect is (0.52,0.80). (This is found as exp(-0.44075±2*0.10621) using the estimate and standard error above.) One should note that this is an average seasonal effect over the entire United States; it is presumably greater in some regions and less in others.
Future posts
With this post, I’ve completed my discussion of the first part of the paper. Somewhat strangely, the results from this part, whose validity I question above, are not directly used in the rest of the paper — they instead just provide a sanity check for the results of fitting a different model to the same proxy data on incidence, and as one input to the possible scenarios for the future that are considered. The second model that Kissler et al. fit is of the SEIRS (Susceptible-Exposed-Infected-Recovered-Susceptible) type. After being used to model the common cold betacoronaviruses, this SEIRS model is extended to include SARS-CoV-2, with various hypothesized characteristics. Simulations with these extended models are the basis for Kissler et al.’s policy discussion.
I’ll critique this SEIRS model for the common cold betacoronaviruses in a future post. But my next post will describe how the full-year regression models for Rt that are described above can easily be converted to dynamical models, that can be used to simulate from a distribution of hypothetical alternative histories for the 2015 to 2019 period. The degree to which these simulations resemble reality is another indication of model quality.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.