
Structural Analisys of Bayesian VARs with an example using the Brazilian Development Bank
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
By Gabriel Vasconcelos
Introduction
Vector Autorregresive (VAR) models are very popular in economics because they can model a system of economic variables and relations. Bayesian VARs are receiving a lot of attention due to their ability to deal with larger systems and the smart use of priors. For example, in this old post I showed an example of large Bayesian VARs to forecast covariance matrices. In this post I will show how to use the same model to obtain impulse response coefficients and perform structural analysis. The type of estimation was based on Bańbura et al. (2010) and the empirical application is from Barboza and Vasconcelos (2019). The objective is to measure the effects of the Brazilian Development Bank on investment. Therefore, we will measure how the investment respond to an increase in loans over the time.
VAR
A structural VAR is described by the following equation:

where 





In VAR models we do not estimate the equation above in a single step. First we estimate the VAR in its reduced form (this is the equation we use to compute forecasts) and then we use some identification strategy to recover the structural form. The reduced form is presented below.

where 


Application
First we must install the lbvar package from my github:
library(devtools)
install_github("gabrielrvsc/lbvar")
library(lbvar)
library(tseries)
The dataset is included in the package and it is called BNDESdata. I removed column 17 in this example because it contains a variable (capital goods prices) used only for robustness in other examples in the paper. The data is already treated and ready for the model. We are going to evaluate the effects of the Brazilian Development Bank Loans (BL) on the Gross Fixed Capital formation (GFCF), the GFCF fraction of machinery and equipment (GFCFme) and the GFCF fraction of machinery and equipment manufactured in Brazil (GFCFmeBR).
data("BNDESdata")
BNDESdata = BNDESdata[,-17]
colnames(BNDESdata) = c("TT", "CRB", "CDS", "WPROD", "BL", "GFCF", "GFCFme",
"GFCFmeBR", "GDP", "IP", "ULC", "CUR", "IR", "ICI",
"UNCERT", "ER", "IBOV")
Before estimating the VAR, we must define some parameters for the priors. Our prior is of a random walk for nonstationary variables and of a white noise for stationary variables. We just used a Phillips-Perron test to determine which variables are stationary and which variables are not. We set a value of 1 for the first autorregresive term of each nonstationary equation and 0 for each stationary equation.
There is another parameter we must define called
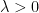
The codes for the Phillips-Perron test and the 
## = Phillips-Perron test
prior = apply(BNDESdata,2,function(x)pp.test(x)$p.value)
prior[prior > 0.05] = 1
prior[prior <= 0.05] = 0
## = lambda estimation
lambda = fitLambda(BNDESdata,c("GFCF","BL","IR"),
seq(0.6,0.65,0.0001), p=13,
p.reduced = 13, delta=prior)
The VAR we want to estimate has 17 variables and 13 lags. This accounts for 3774 parameters in the reduced form if we include the intercept. The name Large Bayesian VARs is very much appropriate. The code below estimates the model, computes the recursive identification (see the full article for more details) and the impulse responses. The last step requires some simulation and it may take a few minutes to run.
## == Estimate the Reduced Form == ## model = lbvar(BNDESdata, 13, delta = prior, lambda = lambda) ## == identification == ## ident = identification(model) ## == Impulse Responses == ## set.seed(123) ir = irf(model, ident, 48, unity.shock = FALSE, M=1000)
Now we can plot the impulse responses and see the results. The figures below show the effects of a shock in the bank loans on the three variations of GFCF.
par(mfrow=c(1,3)) plot(ir,"BL","GFCF",alpha=c(0.05,0.1),xlim=c(0,36),ylim=c(-0.01,0.015),ylab="GFCF",xlab="Time",main="(a)") plot(ir,"BL","GFCFme",alpha=c(0.05,0.1),xlim=c(0,36),ylim=c(-0.01,0.015),ylab="GFCF ME",xlab="Time",main="(b)") plot(ir,"BL","GFCFmeBR",alpha=c(0.05,0.1),xlim=c(0,36),ylim=c(-0.01,0.015),ylab="GFCF ME-BR",xlab="Time",main="(c)")

The effects of the bank are bigger if we move to the machinery and equipment measures because they represent a large portion of the bank’s portfolio. The responses are significant in some horizons. The shock was of one standard deviation, which accounts for a 20% increase in loans. This shock increases the GFCF by less than 2% if we look at the sum of the first 6 months. However, to understand the magnitude of this effect we must look at the fraction of the Brazilian Development Bank on total investment. Our results show that an increase of 1 BRL in loans accounts for an increase of approximately 0.46 BRL in the total GFCF. This may look like a small value first sight. We explain this results with two hypothesis. First, there is some degree of fund substitution where companies use the government bank just because interest rates are lower but they do not suffer from significant credit constraints. Second, There is a crowding-out effect because the government tends to increase the interest rate when the bank puts more money in the economy.
Finally, a good way to evaluate a VAR model in a macroeconomic framework such as this one is to look at how the variables behave in response to the monetary policy. The figures below show how the GFCF behaves when the government increases interest rates (IR).
par(mfrow=c(1,3)) plot(ir,"IR","GFCF",alpha=c(0.05,0.1),xlim=c(0,36),ylim=c(-0.02,0.01),ylab="GFCF",xlab="Time",main="(a)") plot(ir,"IR","GFCFme",alpha=c(0.05,0.1),xlim=c(0,36),ylim=c(-0.02,0.01),ylab="GFCF ME",xlab="Time",main="(b)") plot(ir,"IR","GFCFmeBR",alpha=c(0.05,0.1),xlim=c(0,36),ylim=c(-0.02,0.01),ylab="GFCF ME-BR",xlab="Time",main="(c)")

References
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.