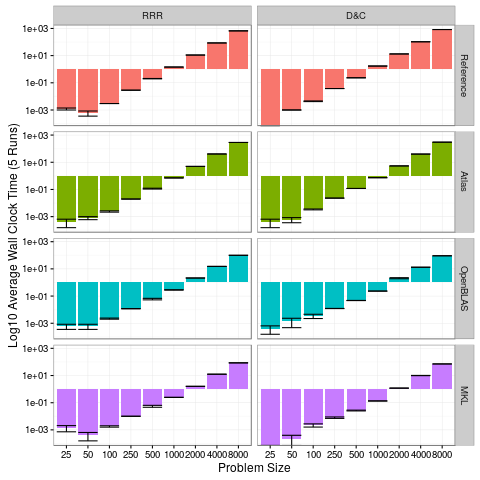
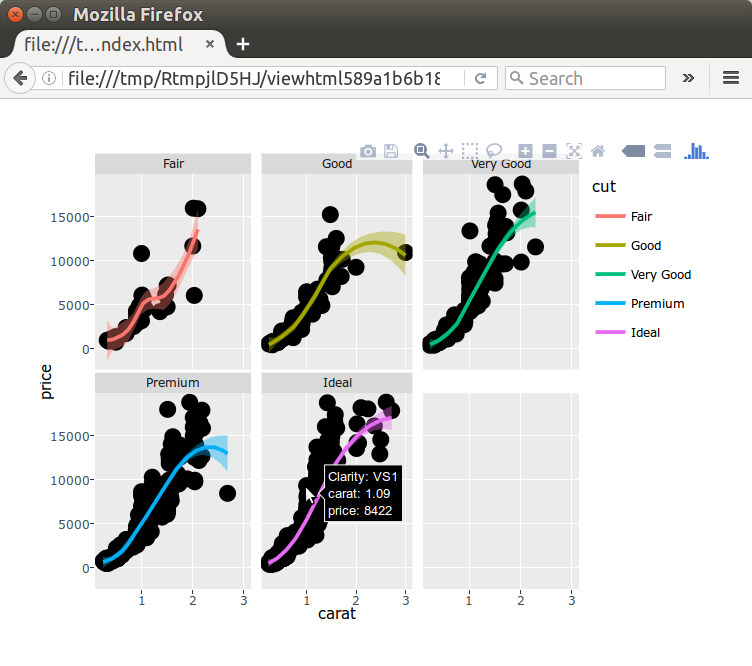
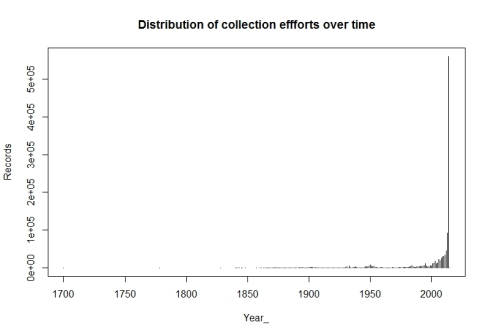
What is wrong with lift curves
The first part of our Marketing Analytics Using R course covers campaign analysis with test- and control groups and campaign optimisation using lift curves and predicted responses. Among the many topics covered, we discuss what is wrong with lift curves. They are a standard tool in marketing to select a ... [Read more...]