
Dynamic arrays in R, Python and Julia
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Although I have a heavy background in statistics (and therefore am primarily an R user), I find that my overall knowledge in computer science is generally lacking. Therefore, I have recently delved deeper into learning about data structures, their associated ADT’s and how they can be implemented. At the same time, I am using this as an opportunity to play around with more unfamiliar languages like Julia, and to a lesser extent, Python.
In Part 1 of 2 of this series, I investigated some of the properties of dynamic arrays in R, Python and Julia. In particular, I was interested in exploring the relationship between the length of an array and its size in bytes, and how this was handled by different languages. For this purpose, I wrote extremely simple functions that recursively added an integer (for this purpose the number 1) to a vector (or one-dimensional array) and extracted its size in bytes at each step.
In Python:
from sys import getsizeof
def size(n):
data = []
for i in range(n):
data.append(1)
print '%s,%s' % (len(data), getsizeof(data))
In Julia:
function size(n)
data = Int64[];
for i = 1:n
push!(data, 1)
@printf "%d,%d\n" i sizeof(data)
end
end
In R:
'size' <- function(n)
{
data <- c()
for(i in 1:100)
{
data <- c(data, 1)
print(sprintf('%s,%s', i, object.size(data)))
}
}
A call to each of these functions using n=100 yields the following plot
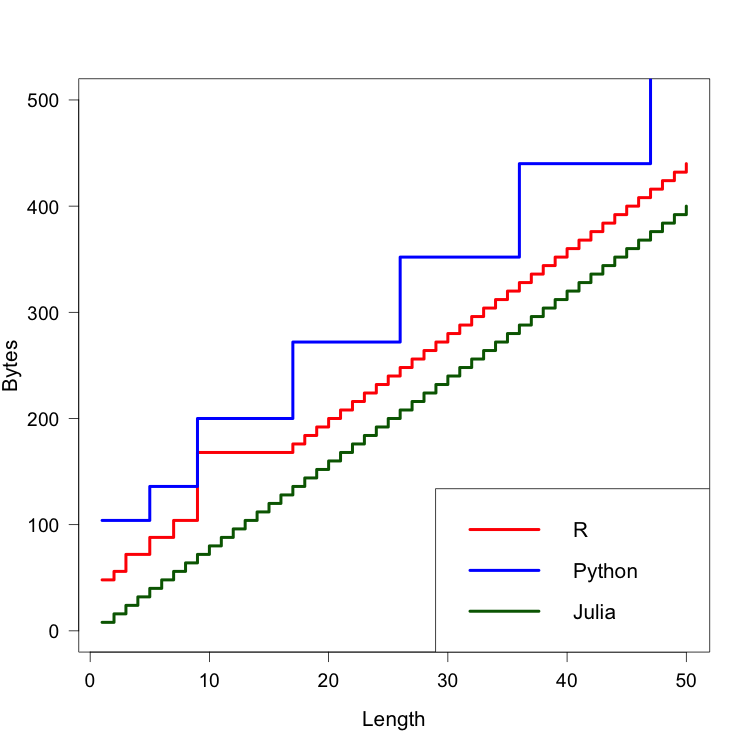
The results of this experiment are quite striking. Python starts with an empty array of size 72 bytes, which increases to 104 as soon as an element is appended to the array. Therefore, Python automatically adds (104-72) = 32 = 4 x 8 bytes. This means that Python extends the array so that it is capable of storing four more object references than are actually needed. By the 5th insert, we have added (136-72) = 64 = 8 x 8 bytes. This goes such that the growth pattern occurs at points 4, 8, 16, 25, 35, 46, 58, 72, 88. interestingly, you can observe that the position i at which the array is extended can be related to the points at which the array itself grows through the relation i = (number_of_bytes_added_at_i – 72) / 8.
For R, I found this link, which does a great job of explaining the mechanisms behind the memory management of R vectors.
Finally, it appears that the push!() function in Julia does not proceed to any kind of preemptive dynamic reallocation of memory. However, I observed that repeatedly calling push!() was fast (more on that later) but not constant time. Further investigation led me to the C source for appending to arrays in Julia, which suggests that Julia performs an occasional exponential reallocation of the buffer (although I am not sure so please correct if wrong!).
Next, I looked at the efficiency of each languages when dealing with dynamic arrays. IN particular, I was interested in how quickly each language could append values to an existing array.
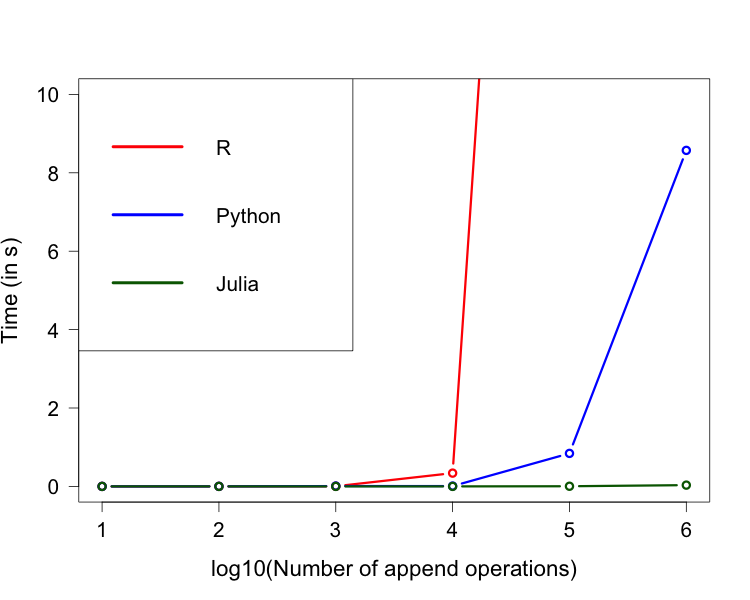
The results clearly show that Julia is far quicker than both Python and R. It should be noted that when defining a function in Julia, the first pass will actually compile and run. Therefore, subsequent calls are generally faster than the first (an important fact to consider during performance benchmarking). Overall, it seems that the statements made by the Julia community are true in this context, namely Julia is a lot faster than Python and R (will add a C++ benchmark eventually 🙂 )

R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.