
Exploratory Data Analysis: Conceptual Foundations of Empirical Cumulative Distribution Functions
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Introduction
Continuing my recent series on exploratory data analysis (EDA), this post focuses on the conceptual foundations of empirical cumulative distribution functions (CDFs); in a separate post, I will show how to plot them in R. (Previous posts in this series include descriptive statistics, box plots, kernel density estimation, and violin plots.)
To give you a sense of what an empirical CDF looks like, here is an example created from 100 randomly generated numbers from the standard normal distribution. The ecdf() function in R was used to generate this plot; the entire code is provided at the end of this post, but read my next post for more detail on how to generate plots of empirical CDFs in R.

Read to rest of this post to learn what an empirical CDF is and how to produce the above plot!
What is an Empirical Cumulative Distribution Function?
An empirical cumulative distribution function (CDF) is a non-parametric estimator of the underlying CDF of a random variable. It assigns a probability of 
The empirical CDF is usually denoted by ")
")
 = \hat{P}_n(X \leq x) = n^{-1}\sum_{i=1}^{n} I(x_i \leq x)")
")
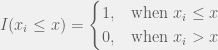

- count the number of data less than or equal to
- divide the number found in Step #1 by the total number of data in the sample
Why is the Empirical Cumulative Distribution Useful in Exploratory Data Analysis?
The empirical CDF is useful because
- it approximates the true CDF well if the sample size (the number of data) is large, and knowing the distribution is helpful for statistical inference
- a plot of the empirical CDF can be visually compared to known CDFs of frequently used distributions to check if the data came from one of those common distributions
- it can visually display “how fast” the CDF increases to 1; plotting key quantiles like the quartiles can be useful to “get a feel” for the data
Some Mathematical Statistics of the Empirical Distribution Function
Some appealing properties of the empirical CDF can be obtained from mathematical statistics.
1) For a fixed ")
")
![E[I(X_i \leq x)] = P(X_i \leq x) = F(x)](http://s0.wp.com/latex.php?latex=E%5BI%28X_i+%5Cleq+x%29%5D+%3D+P%28X_i+%5Cleq+x%29+%3D+F%28x%29+&bg=f0f0f0&fg=555555&s=0 "E[I(X_i \leq x)] = P(X_i \leq x) = F(x)")
which means that
![V[I(X_i \leq x)] = F(x)[1 - F(x)]](http://s0.wp.com/latex.php?latex=V%5BI%28X_i+%5Cleq+x%29%5D+%3D+F%28x%29%5B1+-+F%28x%29%5D+&bg=f0f0f0&fg=555555&s=0 "V[I(X_i \leq x)] = F(x)[1 - F(x)]")
2) By summation of all of these Bernoulli random variables,
![E[\hat{F}_n(x)] = F(x)](http://s0.wp.com/latex.php?latex=E%5B%5Chat%7BF%7D_n%28x%29%5D+%3D+F%28x%29&bg=f0f0f0&fg=555555&s=0 "E[\hat{F}_n(x)] = F(x)")
Also note that
![V[\hat{F}_n(x)] = n^{-1}F(x)[1 - F(x)]](http://s0.wp.com/latex.php?latex=V%5B%5Chat%7BF%7D_n%28x%29%5D+%3D+n%5E%7B-1%7DF%28x%29%5B1+-+F%28x%29%5D&bg=f0f0f0&fg=555555&s=0 "V[\hat{F}_n(x)] = n^{-1}F(x)[1 - F(x)]")
Thus, for a fixed ")
")
3) By the Glivenko-Cantelli theorem,
Here is the code for generating the plot of the empirical CDF of the random standard normal numbers; the plot is given again after the code. For the sake of brevity, I will describe in detail how to generate this and other plots of empirical CDFs in a separate post; in fact, I will show 2 different ways of doing so in R!
##### Empirical Distribution Function
##### By Eric Cai - The Chemical Statistician
# set the seed for consistent replication of random numbers
set.seed(1)
# generate 100 random numbers from the standard normal distribution
normal.numbers = rnorm(100)
# empirical normal CDF of the 100 normal random numbers
normal.ecdf = ecdf(normal.numbers)
# plot normal.ecdf (notice that the only argument needed is normal.ecdf)
# use png() and dev.off() to print this plot to your chosen folder
png('INSERT YOUR DIRECTORY PATH HERE/ecdf standard normal.png')
plot(normal.ecdf, xlab = 'Quantiles of Random Standard Normal Numbers', ylab = '', main = 'Empirical Cumluative Distribution\nStandard Normal Quantiles')
# add label to y-axis with mtext()
# side = 2 denotes the left veritical axis
# line = 2.5 sets the position of the label
mtext(text = expression(hat(F)[n](x)), side = 2, line = 2.5)
dev.off()
Filed under: Applied Statistics, Descriptive Statistics, R programming Tagged: cdf, consistency, convergence, cumulative distribution function, data, data analysis, empirical cdf, empirical cumulative distribution function, estimator, expected value, exploratory data analysis, normal distribution, plot, plots, plotting, standard normal distribution, statistics, unbiased estimator, uniform convergence, variance

R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.