
Example 9.21: The birthday "problem" re-examined
[This article was first published on SAS and R, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
The so-called birthday paradox or birthday problem is simply the counter-intutitive discovery that the probability of (at least) two people in a group sharing a birthday goes up surprisingly fast as the group size increases. If the group is only 23 people, there is a 50% chance that two of them share a birthday, and with 40 people it’s about 90%. There is an excellent wikipedia page discussing this.
However, this analytically derived probability is based on the assumption that births are equally likely on any day of the year. (It also ignores the occasional February 29th, and any social factors that lead people born at the same time of year to seek like spouses, and so forth.) But this assumption does not appear to be true, as laid out anecdotally and in press.
As noted in the latter link, any disparity in the probability of birth between days will improve the chances of a match. But how much? An analytic solution seems quite complex, even if we approximate the true daily distribution with a constant birth probability per month. Simulation will be simpler. While we’re at it, we’ll include leap days as well, since February 29th approaches.
SAS
Our approach here is based on the observation that the probability of at least one match among N people is equal to the sum of the probabilities of exactly one match in 2,…,N people. In addition, rather than simulating groups of 2, estimating the probability of a match, and repeating for groups of 3,…,N, we’ll keep adding people to a group until we have a match, finding the probability of a match in all group sizes at once.
Here we use arrays (section 1.11.5) to keep track of the number of days in a month and of the people in our group. To reduce computation, we’ll check for matches as we add people to the group, and only generate their birthdays if there is not yet a match. We also demonstrate the useful hyphen tool for referring to ranges of variables (1.11.4).
data bd1;
array daysmo [12] _temporary_ (31 28.25 31 30 31 30 31 31 30 31 30 31);
array dob [367] dob1 - dob367; * these variables will hold the birthdays
* the hyphen includes all the variables in the
* sequence
do group = 1 to 10000000; * simulate this many groups;
match = 0; * initialize whether there's a match in this
group, yet;
do i = 1 to 367; * loop through up to 367 subjects... the maximum
possible, obviously;
month = rantbl(0, 31*.0026123, 28*.0026785, 31*.0026838, 30*.0026426,
31*.0026702, 30*.0027424, 31*.0028655, 31*.0028954, 30*.0029407,
31*.0027705, 30*.0026842);
* choose a month of birth, by probabilities reported
in the Science News link, which are daily by month;
day = ceil((4 * daysmo[month] * uniform(0))/4);
* choose a day within the month,
note the trick used to get Leap Days;
dob[i] = mdy(month, day, 1960);
* convert month and day into a day in the year--
1960 is a convenient leap year;
do j = 1 to (i-1) until (match gt 0);
* compare each old person to the new one;
if dob[j] = dob[i] then match = i;
* if there was a match, we needed i people in the
group to make it;
end;
if match gt 0 then leave;
* no need to generate the other 367-i people;
end;
output;
end;
run;
We note here that while we allow up to 367 birthdays before a match, the probability of more than 150 is so infinitesimal that we could save the space and speed up processing time by ignoring it. Now that the groups have been simulated, we just need to summarize and present them. We tabulate how many cases of groups of size N were recorded, generate the simple analytic answer, and merge them.
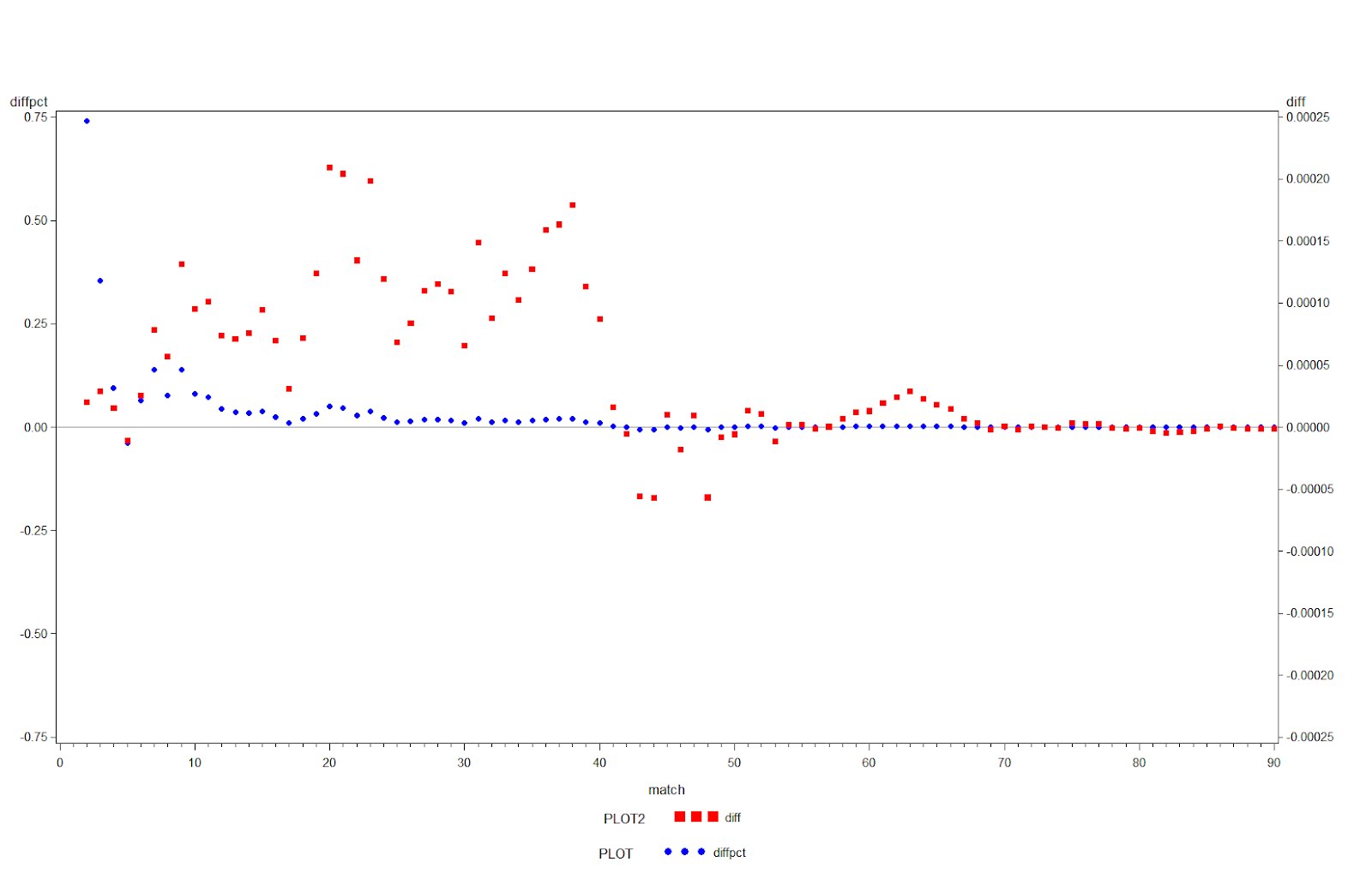
proc freq data = bd1; tables match / out=bd2 outcum; * the bd2 data set has the results; run; data simpreal; set bd2; prob = 1 - ((fact(match) * comb (365,match)) / 365**match); realprob = cum_freq/10000000; diff = realprob-prob; diffpct = 100 * (diff)/prob; run;
It’s easiest to interpret the results by way of a plot. We’ll plot the absolute and the relative difference on the same image with two different axes. The axis and symbol statements will make it slightly prettier, and allow us to make 0 appear at the same point on both axes.
axis1 order = (-.75 to .75 by .25) minor = none; axis2 order = (-.00025 to .00025 by .00005) minor = none; symbol1 v = dot h = .75 c = blue; symbol2 font=marker v = U h = .5 c = red; proc gplot data= simpreal (obs = 89); plot diffpct * match / vref = 0 vaxis=axis1 legend; plot2 diff *match/ vaxis = axis2 legend; run; quit;
The results, shown below, are very clear– leap day and the disequilibrium in birth month probability does increase the probability of at least one match in any group of a given size, relative to the uniform distribution across days assumed in the analytic solution. But the difference is miniscule in both the absolute and relative scale.
R
Here we mimic the approach used above, but use the apply() function family in place of some of the looping.
dayprobs = c(.0026123,.0026785,.0026838,.0026426,.0026702,.0027424,.0028655,
.0028954,.0029407,.0027705,.0026842,.0026864)
daysmo = c(31,28,31,30,31,30,31,31,30,31,30,31)
daysmo2 = c(31,28.25,31,30,31,30,31,31,30,31,30,31)
# need both: the former is how the probs are reported,
# while the latter allows leap days
moprob = daysmo * dayprobs
With the monthly probabilities established, we can sample a birth month for everyone, and then choose a birth day within month. We use the same trick as above to allow birth days of February 29th. Here we show code for 10,000 groups; with the simple cloud R this code was developed on, more caused a crash.
We’ve stopped referencing our book exhaustively, and doing so here would be tedious. Instead, we’ll just comment that the tools we use here can be found in sections 1.4.5, 1.4.15, 1.4.16, 1.5.2, 1.8.3, 1.8.4, 1.9.1, 1.11.1, 5.2.1, 5.6.1, B.5.2, and probably others.
mob = sample(1:12,10000 * 367,rep=TRUE,prob=moprob) dob = sapply(mob,function(x) ceiling(sample((4*daysmo2[x]),1)/4) ) # The ceiling() function isn't vectorized, so we make the equivalent # using sapply(). mobdob = paste(mob,dob) # concatenate the month and day to make a single variable to compare # between people. The ISOdate() function would approximate the SAS mdy() # function but would be much longer, and we don't need it. # convert the vector into a matrix with the maximum # group size as the number of columns # as noted above, this could safely be truncated, with great savings mdmat = matrix(mobdob, ncol=367, nrow=10000)
To find duplicate birthdays in each row of the matrix, we’ll write a function to compare the number of unique values with the length of the vector, then call it repeatedly in a for() loop until there is a difference. Then, to save (a lot) of computations, we’ll break out of the loop and report the number needed to make the match. Finally, we’ll call this vector-based function using apply() to perform it on each row of the birthday matrix.
matchn = function(x) {
for (i in 1:367){
if (length(unique(x[1:i])) != i) break
}
return(i)
}
groups = apply(mdmat, 1, matchn)
bdprobs = cumsum(table(groups)/10000)
# find the N with each group number, divide by number of groups
# and get the cumulative sum
rgroups = as.numeric(names(bdprobs))
# extract the group sizes from the table
probs = 1 - ((factorial(rgroups) * choose(365,rgroups)) / 365**rgroups)
# calculate the analytic answer, for any group size
# for which there was an observed simulated value
diffs = bdprobs - probs
diffpcts = diffs/probs
To plot the differences and percent differences in probabilities, we modify (slightly) the functions for a multiple-axis scatterplot we show in our book in section 5.6.1. You can find the code for this and all the book examples on the book web site.
addsecondy <- function(x, y, origy, yname="Y2") {
prevlimits <- range(origy)
axislimits <- range(y)
axis(side=4, at=prevlimits[1] + diff(prevlimits)*c(0:5)/5,
labels=round(axislimits[1] + diff(axislimits)*c(0:5)/5, 3))
mtext(yname, side=4)
newy <- (y-axislimits[1])/(diff(axislimits)/diff(prevlimits)) +
prevlimits[1]
points(x, newy, pch=2)
abline(h=(-axislimits[1])/(diff(axislimits)/diff(prevlimits)) +
prevlimits[1])
}
plottwoy <- function(x, y1, y2, xname="X", y1name="Y1", y2name="Y2")
{
plot(x, y1, ylab=y1name, xlab=xname)
abline(h=0)
addsecondy(x, y2, y1, yname=y2name)
}
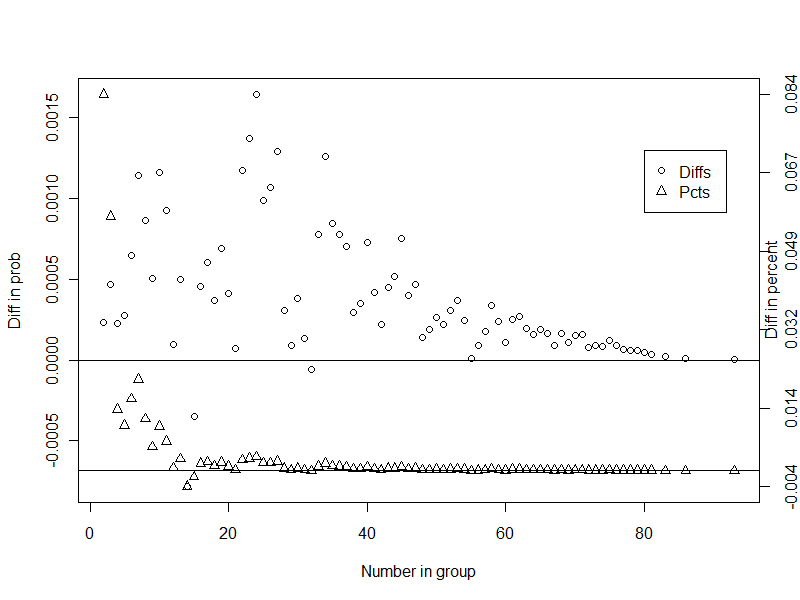
plottwoy(rgroups, diffs, diffpcts, xname="Number in group",
y1name="Diff in prob", y2name="Diff in percent")
legend(80, .0013, pch=1:2, legend=c("Diffs", "Pcts"))
The resulting plot, (which is based on 100,000 groups, tolerable compute time on a laptop) is shown at the top. Aligning the 0 on each axis was more of a hassle than seemed worth it for today. However, the message is equally clear-- a clearly larger probability with the observed birth distribution, but not a meaningful difference.
To leave a comment for the author, please follow the link and comment on their blog: SAS and R.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.