
Archetypal Analysis
[This article was first published on Engaging Market Research, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Thinking Strategically about Customer HeterogeneityWant to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Ironically, market segmentation, whose motto is “one size does not fit all,” seems to rely almost exclusively on one definition of what constitutes a segment. Borrowing its definition from cluster analysis, segments are groupings of objects such that similar objects are gathered together and separated from dissimilar gatherings of other similar objects. “Birds of a feather flock together” and stay away from birds of a different feather.
If there were a single feature responsible for the groupings, then we could describe each group by the name of this single feature. But this is a difficult task when there are lots of respondents measured on lots of variables. In fact, just assessing the similarity among respondents becomes difficult when each respondent is described by a long profile of measurements (especially when there is a mixture of quantitative and qualitative variables). In such cases, we describe segments using the average of all the object features that we used to measure similarity.
Yet the goal of “one size does not fit all” is not to look for clusters. It is to look for heterogeneity among customers, and then exploit those differences by finding opportunities for product and service differentiation. Clustering is one way to structure a large multivariate data set. However, it is not the only way. Early adopters, as they evolve into new segments, are often not uniform or homogeneous in their needs or responses to questionnaire items. Price sensitive customers may never form a compact group but remain a continuum of more or less attraction toward lower costs.
Cluster analysis focuses on groupings within the cloud of individual respondents. Archetypal analysis, on the other hand, searches the periphery for concentrations of more extreme individuals. Cluster analysis describes its segments using the “average” member as the prototype. Archetypal analysis uses extreme exemplars to describe the frontiers.
Archetypal analysis was introduced in 1993 by Cutler and Breiman. Their first example in this technical report was a question of how many sizes are needed to fit all.
“For instance, a data set … consists of 6 head dimensions for 200 Swiss soldiers. The purpose of the data was to help design face masks for the Swiss Army. A natural question is whether there are a few ‘pure types’ or ‘archetypes’ of heads such that the 200 heads in the data base are mixtures of the archetypal heads.”This is a segmentation, but not in the traditional sense of a segment described as the average of all its members. Everyone must have a mask that covers their face. So the mask must be big enough to cover every one’s face. But one can still wear a mask that is somewhat larger than their face. Consequently, the pure types must be located at the periphery.
Hair stylists also have a lot to say about the shapes of faces. Faces are oblong, round, oval, square, and so on. Should we describe each of these types by its prototype (average) or by its caricature (archetype)? Of course, the answer is “it depends.”
If the goal is classification accuracy and the clusters are compact (e.g., a mixture of multivariate normal distributions), then the average is likely to be a good segment descriptor. However, the average performs less well as the clusters become elongated, and it does not serve us well if our goal is a set of contrastive categories to assist in decision making.
Let’s return to our hair stylist trying to help a client decide how to cut her hair. Here are the face shapes.

These are clear segments needing different hair styles and also different makeup (both are multi-billion dollar a year markets). The round face does not look like the rectangular face, but not because we have a compact cluster of round faces that is well-separated from the rectangular faces. The differences are due to ratios of length and width at different locations along the face. We could easily imagine the round face “morphing” into the rectangular because both faces represent pure types on the periphery of the distribution of facial shapes. Actual faces are mixtures of these ideal types.
We should note again that pure types or archetypes are a form of contrastive categorization. We define our categories in terms of idealized types in order to magnify the contrast with competing options. The marketer seeking to find and exploit customer heterogeneity is not a scientist searching for the most accurate taxonomy. The customer trying to make sense out of a confusing array of varying products and brands is looking for distinctions that will help them make a purchase. Product differentiation and customer heterogeneity are co-creations, and both marketers and customers are willing to fudge a little in the service of action.
Consequently, customers tend to see products and their users as a bit more extreme than they actually are. And marketers see market segments as more distinct and well-separated than the numbers show. This is the nature of human perceptions. Categorization gravitates toward black and white, premium and economy, self and full service, big and small businesses, and a seemingly unending list of dualisms. Of course, there can be more than two categories as in packages with basic, value, and luxury options. But the same tendency for the competing categories to push away from each other can be found so that the segments appear more extreme than they actually are.
We have several programs for running K-means and latent class analysis. Any of these will identify well-formed and separated clusters using the average to describe the clusters. R offers the package archetype when we believe that the clusters are best defined by contrastive categories.
Usage Segmentation Comparing K-means and Archetypes
Let’s look at an example. We will use a frequency of usage scale to measure how often a respondent uses each of 10 features. The usage scale has 7 categories ranging from 1=never, 3=once a month, 5=once a week, and 7=once a day or more often.
The 10 features can be divided into two groups tapping two distinct types of usage. There are five features tapping the first usage type, which we will call A1, A2, A3, A4, and A5. The other five features are called B1, B2, B3, B4, and B5 because they measure the second usage type. Percentages for 200 respondents on each of the 7-point usage scale values are shown below.
1 | 2 | 3 | 4 | 5 | 6 | 7 | |
A1 | 61.5% | 6.0% | 5.5% | 6.0% | 2.5% | 5.5% | 13.0% |
A2 | 55.5% | 7.0% | 4.0% | 6.5% | 4.0% | 3.5% | 19.5% |
A3 | 53.0% | 7.0% | 4.5% | 6.0% | 6.0% | 9.5% | 14.0% |
A4 | 43.0% | 6.0% | 4.5% | 6.5% | 7.5% | 3.5% | 29.0% |
A5 | 38.5% | 11.5% | 7.0% | 4.5% | 5.0% | 18.5% | 15.0% |
B1 | 38.5% | 10.5% | 20.0% | 15.5% | 11.5% | 4.0% | 0.0% |
B2 | 23.5% | 21.0% | 22.0% | 15.0% | 16.5% | 2.0% | 0.0% |
B3 | 27.0% | 26.5% | 10.5% | 16.5% | 13.5% | 6.0% | 0.0% |
B4 | 18.0% | 24.0% | 25.5% | 16.5% | 10.5% | 5.5% | 0.0% |
B5 | 10.0% | 22.0% | 28.0% | 21.0% | 11.5% | 7.5% | 0.0% |
It is clear that the usage pattern for the A features is different than the usage pattern for the B features. A good percentage of the respondents never use any of the A features. But there is a sizable minority that use the five A features once a day or more often. The B features, on the other hand, tend to show a more symmetric usage pattern, although none of the respondents uses any of the B features every day.
We will look at the results of the archetypal analysis first. The goal of archetypal analysis is to identify extreme patterns in the data so that all the observations can be reproduced as mixtures of those extremes. It is easiest to think about what the previous sentence means by thinking of physical measurements. Find the shortest person on basketball team. Find the tallest person on the basketball team. Everyone on the team falls between these two extremes. The taller players are more like the tallest player. The shorter players are more like the shortest player. Any particular player’s height could be represented as a mixture of the tallest and shortest players. Thus, one might guess that a 50-50 player had a height about half way between the tallest and shortest. We could add a dimension for weight and talk about the extreme points in a two-dimensional height-weight space. Hopefully, you get the point.
Manuel J. A. Eugster, who co-authored and maintains the archetypes package in R, has a paper on Archetypal Athletes that will walk you carefully through both the calculations and examples from basketball and soccer. This is a website well worth visiting. Look for his Journal of Statistical Software article and take the time to review the slides from his talks. Eugster has created a comprehensive and easy to use package with extensive documentation – http://www.statistik.lmu.de/~eugster/.
So what do we get when we analyze our feature usage data? Like a K-means clustering, one needs to specify the number of archetypes to fit, that is, you must rerun the analysis for differing numbers of archetypes and compare the results. Fortunately, the package includes a stepArchetypes function that allows one to run multiple number of archetypes solution as one time and produce a screeplot.

The residual sum-of-squares (RSS) indicates how well the original data can be reproduced as mixtures of the archetypes. That is, the screeplot helps us see how many archetypes are necessary to reproduce our data. Here we have an elbow at three archetypes. So this is where we start. In addition, we will run a K-means clustering with three segments and compare the results.
K1 | K2 | K3 | AA1 | AA2 | AA3 | ||
49 | 52 | 99 | 42 | 50 | 108 | ||
25% | 26% | 50% | 21% | 25% | 54% | ||
A1 | 5.9 | 1.6 | 1.3 | 5.5 | 3.3 | 1.0 | |
A2 | 5.1 | 3.4 | 1.5 | 6.1 | 3.6 | 1.0 | |
A3 | 5.1 | 3.5 | 1.5 | 6.3 | 3.4 | 1.0 | |
A4 | 6.3 | 5.2 | 1.3 | 6.8 | 5.0 | 1.0 | |
A5 | 6.0 | 3.8 | 2.0 | 6.5 | 4.6 | 1.0 | |
B1 | 3.4 | 2.6 | 2.3 | 1.5 | 5.7 | 1.0 | |
B2 | 3.8 | 2.7 | 2.5 | 2.2 | 5.5 | 1.2 | |
B3 | 3.7 | 2.7 | 2.5 | 2.0 | 5.8 | 1.1 | |
B4 | 3.6 | 2.9 | 2.7 | 2.0 | 5.6 | 1.4 | |
B5 | 3.8 | 3.2 | 3.0 | 1.9 | 6.0 | 1.9 |
The means for the three K-means clusters are given in the first three columns. Pick any feature, say B2, and compare the means for the three clusters: K1 > K2 >K3. Regardless of the feature, Cluster 1 has higher usage than Cluster 2, which in turn, has higher usage than Cluster 3. We can see this clearly by plotting the 200 observations using the first two dimensions from an unrotated principal component.

The arrows show the projection of the features onto the principal component space. The first principal component represents intensity, and the second principal component separates usage of the A features (numbered 1-5) from usage of the B features (numbered 6-10). The three clusters form “bands” that seem to be more perpendicular to the A features than to the B features. And we can see this in the cluster means with the greatest differences in the first five A features. The rank ordering is the same in the second five B features, but the means are not as different from each other.
Now let’s return to the table of means to look at the usage profiles for our three archetypes. The first archetype (AA1) defines feature A users, the second archetype (AA2) shows the highest levels of feature B usage along with moderate feature A usage, and the third archetype (AA3) portrays seldom or non-users. Our second archetype is interesting, and their usage pattern would make sense if the B features were more advanced, so that beginning users only used the A features and more experienced users concentrated on the B features but also used the more basic A features less often. Let’s take a look at the scatterplot.
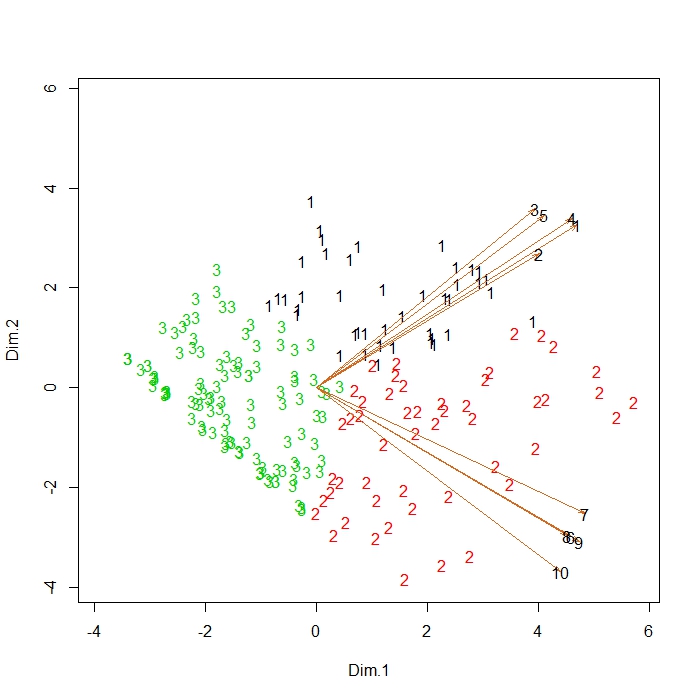
Here, as before with K-means, we find the same observations and the same arrows representing the 10 feature usages, but now the numbers indicated which of the three archetypes is the closest to each observation. Although we are not required to force respondents into mutually exclusive segments, there are times when this helps with our interpretation. This is an important point. Archetypal analysis yields graded segment membership. Every respondent is a mixture of different archetypes.
The shape of the cloud of individuals in these scatterplots can be called a “fan-spread” because feature usage becomes more differentiated as usage level increases (as one moves from left to right along the first dimension). That is, light users are more homogeneous, while more intense users show greater diversity in their feature usage. One might guess that a 4-archetype solution might divide the 2’s in the above scatterplot into feature-B-only users and all-feature users. And you would be right as shown below.

Let’s finish this discussion by showing the relationship between the archetype and K-mean profiles. Archetypes are located on the edges of the cloud of individual observations. K-means are profiled using averages of segment members so they are pulled toward the center of their clusters. Thus, in the following plot the K-means segments can be found in the interior of the cloud. Moreover, the three K-means segments lie along a line dominated by the first principal component, usage intensity. In contrast, archetypal analysis is able to reveal the underlying fan-spread pattern. Each respondent is triangulated as a mixture of three archetypes representing no usage, feature A usage, and feature B usage.

The reader must be warned that I have deliberately created a data set where archetypal analysis ought to do better than K-means. In my defense, the data set reflects what I see all the time when analyzing usage data. It is a realistic example reflecting how respondents use features in the real world. K-means, which works well with compact and clearly separated clusters, fails to uncover the underlying structure when the data follow a fan-spread pattern.
How prevalent is the fan-spread in marketing data? You see it in importance ratings with higher raters showing more differentiation in their ratings. You see it in attitude ratings with greater differentiation in the attitudes of individual with more intensely held beliefs. We could go on with additional examples, but we do not want to limit the usefulness of archetypal analysis to the fan-spread model.
Archetypal analysis is an appropriate model for customer heterogeneity whenever the underlying structure is best defined by the extremes. Thus, all contrastive categorization would benefit from archetypal analysis. Contrastive categorization is what we use in decision making: Apple vs. PC, Democrat vs. Republican, low cost vs. premium, big bank vs. local bank, SUV vs. minivan, etc.
We exaggerate differences among products and their users in order to aid us in our marketplace decisions. In fact, the desire to use contrastive categories is so strong in marketing research that even when we use K-means to identify clusters and averages to profile those clusters, our segment names will be embellished to reflect a prototypical member that is more extreme than their segment means indicate. Consequently, a segment of users with moderate price sensitivity will be labeled as price sensitive. Soon we will forget that this segment displays only moderate levels of price sensitivity. The segment label is reified, and the segment members caricatured.
Finally, archetypal analysis is worth pursuing whenever you believe that the market is evolving and new segments are forming. Early adopters may not show up in a K-means because they are few and at the periphery of the respondent cloud. However, even small concentrations of users at the edge will reduce the residual sum-of-squares in an archetypal analysis. We have no guarantee that new segments in the process of forming will be discovered, but at least now, we have a technology that provides the ability to explore that frontier.
Appendix Showing the R Code to Reproduce This Analysis
#generates 200 observations with the following#category level percentages and correlation matrixlibrary(orddata)
prob <- list(
c(60,5,5,5,5,5,15)/100,
c(55,5,5,5,5,5,20)/100,
c(55,5,5,5,5,10,15)/100,
c(45,5,5,5,5,5,30)/100,
c(40,15,5,5,5,15,15)/100,
c(30,20,15,15,15,5)/100,
c(25,20,20,15,15,5)/100,
c(20,25,20,15,15,5)/100,
c(15,25,25,15,15,5)/100,
c(10,25,30,15,15,5)/100
)
prob
#uses matrix multiplication of factor loadings to create#a correlation matrix with a given patternloadings<-matrix(c(
.4,.6, 0,
.4,.6, 0,
.4,.6, 0,
.4,.6, 0,
.4,.6, 0,
.4,.0,.6,
.4,.0,.6,
.4,.0,.6,
.4,.0,.6,
.4,.0,.6),
10, 3, byrow=TRUE)
loadings
cor_matrix<-loadings %*% t(loadings)
diag(cor_matrix)<-1
cor_matrix
ord<-rmvord(n = 200, probs = prob, Cor = cor_matrix)
apply(ord,2,table)
# these are the commands needed to run the archetypal analysislibrary(archetypes)
aa<-stepArchetypes(ord, k=1:10, nrep=5)
screeplot(aa)
rss(aa)
aa_3<-bestModel(aa[[3]])
round(t(parameters(aa_3)),3)
aa_3_profile<-coef(aa_3)
aa_3_cluster<-max.col(aa_3_profile)
table(aa_3_cluster)
#code for K-meanskcl_3<-kmeans(ord, 3, nstart=25, iter.max=100)
table(kcl_3$cluster)
t(kcl_3$centers)
#profiles for K-means and archetypes added to original data# as supplementary points in order to map the results in a# two-dimensional principal component spaceaa_profile<-parameters(aa_3)
kcl_profile<-kcl_3$centers
ord2<-rbind(ord,aa_profile,kcl_profile)
row.names(ord2)<-NULL
#ease package to use with supplementary pointslibrary(FactoMineR)
pca<-PCA(ord2, ind.sup=201:206, graph=FALSE)
#plots K-meansplot(pca$ind$coord[,1:2], type="n", xlim=c(-3.9,5.8), ylim=c(-3.9,5.8))
text(pca$ind$coord[,1:2], col=kcl_3_labels, labels=kcl_3_labels)
arrows(0, 0, 7*pca$var$coord[,1], 7*pca$var$coord[,2], col = "chocolate", angle = 15, length = 0.1)
text(7*axes$loadings[,1], 7*axes$loadings[,2], labels=1:10)
#plots archetypesplot(pca$ind$coord[,1:2], type="n", xlim=c(-3.9,5.8), ylim=c(-3.9,5.8))
text(pca$ind$coord[,1:2], col=aa_3_cluster, labels=aa_3_cluster)
arrows(0, 0, 7*pca$var$coord[,1], 7*pca$var$coord[,2], col = "chocolate", angle = 15, length = 0.1)
text(7*axes$loadings[,1], 7*axes$loadings[,2], labels=1:10)
#plots K-means centroids and archetype profilesplot(pca$ind$coord[,1:2], pch=".", cex=4, xlim=c(-3.9,5.8), ylim=c(-3.9,5.8))
text(pca$ind.sup$coord[,1:2], labels=c("A1","A2","A3","K1","K2","K3"), col=c(rep("blue",3),rep("red",3)),cex=1.5)
To leave a comment for the author, please follow the link and comment on their blog: Engaging Market Research.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.