
24 Days of R: Day 3
This is the post where we begin to talk about Michael Caine. There's no strong reason for this. It's not as though I have a great fascination with him. Don't get me wrong, I think he's a fine actor. Michael Caine happened to cross my mind a couple weeks ago when I was listening to an interview with Steven Coogan. He did his fantastic impression of Caine and Caine's voice (or Coogan's facsimile of Caine's voice) was lodged in my head for a few days. It struck me that he's done quite a lot of work over a very long period of time. He's done good work and he's done crap (Jaws IV, anyone?) That breadth and depth makes him a ripe candidate for statistical research.
There are several things that I'd like to know: 1. Just how much work has he done? 2. Who has he worked with? What does his social network look like? 3. Speaking of social network, is he more ubiquitous than Kevin Bacon? 4. How has he fared critically? How has he fared commercially? 5. When did he get awards? When does anyone? Does Hollywood have a different standard for actors and actresses based on how old they are?
These are all verey important questions. To get started, I went to imdb, the premier source for information about film and television. So, here's the thing about imdb. They don't have an API. Fair enough, they've got quite a lot of assets to protect and they don't want someone to replicate their site. I'm going to extract information, but will emphasize that this information is being used for entertainment purposes only. All my code is public and shareable and not to be used for commercial gain. If anyone attempts any derivative work based on this code, they are doing so without my knowledge or sanction.
With that out of the way, let's start by figuring out in just how many movies Michael Caine has appeared. We'll need XML to fetch the information. Note that I've constructed the URL manually. Turns out there are a number of references to a Michael Caine on imdb.
library(XML) URL = "http://www.imdb.com/name/nm0000323/?ref_=fn_al_nm_1#actor" content.raw = htmlTreeParse(URL, useInternalNodes = TRUE)
This next bit took quite a lot of manual effort. I'm not terribly proficient at walking through the nodes of an HTML file and this one is large and complex. There are a number of manual bits that required me to have a look at the webpage and the associated HTML.
myXpath = "//div[@id = 'filmography']"
works = getNodeSet(content.raw, path = myXpath)
works = xmlChildren(works[[1]])
works = works[[4]]
years = xpathSApply(works, path = "//span[@class='year_column']", xmlValue)
years = gsub("[[:alpha:]]", "", years)
years = gsub("[[:space:]]", "", years)
years = gsub("-", "", years)
years = as.numeric(years)
## Warning: NAs introduced by coercion
years = years[!is.na(years)]
This somehow gives me 362 years vs. imdb's list of 160 credits. Not sure what's happening to create that. The lesson? Munging HTML is very, very hard.
library(ggplot2) summary = table(years) dfCaine = data.frame(year = names(summary), films = summary) plt = ggplot(dfCaine, aes(year, films.Freq)) + geom_bar(stat = "identity") plt
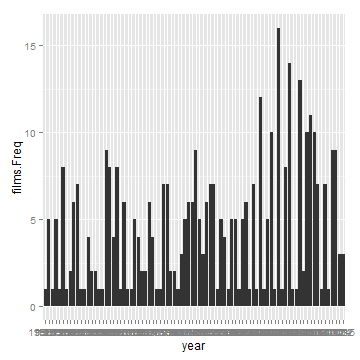
I can tell that the data isn't kosher because 2005 isnt' right at all. Tomorrow I'll be spending more time trying to learn how to use XML to sort out this data. I'm also going to look into other film APIs. As always, suggestions welcome.
sessionInfo() ## R version 3.0.2 (2013-09-25) ## Platform: x86_64-w64-mingw32/x64 (64-bit) ## ## locale: ## [1] LC_COLLATE=English_United States.1252 ## [2] LC_CTYPE=English_United States.1252 ## [3] LC_MONETARY=English_United States.1252 ## [4] LC_NUMERIC=C ## [5] LC_TIME=English_United States.1252 ## ## attached base packages: ## [1] stats graphics grDevices utils datasets methods base ## ## other attached packages: ## [1] knitr_1.4.1 RWordPress_0.2-3 ggplot2_0.9.3.1 XML_3.98-1.1 ## ## loaded via a namespace (and not attached): ## [1] colorspace_1.2-3 dichromat_2.0-0 digest_0.6.3 ## [4] evaluate_0.4.7 formatR_0.9 grid_3.0.2 ## [7] gtable_0.1.2 labeling_0.2 MASS_7.3-29 ## [10] munsell_0.4.2 plyr_1.8 proto_0.3-10 ## [13] RColorBrewer_1.0-5 RCurl_1.95-4.1 reshape2_1.2.2 ## [16] scales_0.2.3 stringr_0.6.2 tools_3.0.2 ## [19] XMLRPC_0.3-0
