

Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
I stumbled upon Gaussian Processes when looking into how the MIPRO prompt optimisation algorithm works and felt compelled to learn more about it. It’s a very nifty application of Bayesian modelling to analyse functions where data points are hard to get.
This post is based on a great lesson by Carpentries, which is part of a longer series on probabilistic programming in R. Very worth checking out if you want to know more.
< section id="wth-are-gaussian-processes" class="level1">WTH are Gaussian Processes?
Imagine your data



We don’t know





What’s the point of this? Well it allows us to use our Bayesian toolbox (hello again Stan) to refine our estimate of
The Kernel 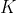



If we implement the kernel and draw from
set.seed(42)
library(tidyverse)
sq_exp_cov <- function(x, lambda, alpha) {
n <- length(x)
K <- matrix(0, n, n)
for (i in 1:n) {
for (j in 1:n) {
diff <- sqrt(sum((x[i] - x[j])^2))
K[i, j] <- alpha^2 * exp(-diff^2 / (2 * lambda^2))
}
}
K
}
x <- 0:100
GP <- function(alpha, lambda, n_samples = 10) {
K <- sq_exp_cov(x, lambda, alpha)
mat <- MASS::mvrnorm(
n_samples,
mu = rep(0, length(x)), # Set the average level of the process to 0
Sigma = K
)
t(mat) |>
data.frame() |>
mutate(alpha = alpha, lambda = lambda, x = x) |>
pivot_longer(c(-x, -alpha, -lambda), names_to = "sample", values_to = "y")
}
grd <- expand.grid(alpha = c(0.5, 1, 2), lambda = c(1, 10, 100))
samples <- map2(grd$alpha, grd$lambda, GP) |> bind_rows()
labeller <- function(variable, value) {
if (variable == "alpha") {
sprintf("α = %s", value)
} else {
sprintf("λ = %s", value)
}
}
ggplot(samples) +
aes(x = x, y = y, group = sample, colour = sample) +
facet_wrap(~ alpha * ~lambda, labeller = labeller) +
geom_line(show.legend = FALSE) +
labs(title = "Samples of f(x) from GP") +
theme_minimal()


Varying
Gaussian Process Regression – using data to refine 
Imagine we’ve observed some (noisy) data from a mystery function.
df6 <- data.frame( x = c(-2.76, 2.46, -1.52, -4.34, 4.54, 1), y = c(-0.81, -0.85, 0.76, -0.41, -1.48, 0.2) )
We intend to predict the values of
x_pred <- seq(-5, 5, by = 0.25) # you'll get a smoother approximation for smaller increments, but at increase computation cost
Then we model it all in Stan. Personally I find Stan models easier to read in the order model, data, parameters.
data {
// Observed data
int n_data;
array[n_data] real x_data;
array[n_data] real y_data;
// Observation error
real<lower=0> sigma;
// x values for which we aim to predict y
int n_pred;
array[n_pred] real x_pred;
// Hyperparameters for the kernel
real alpha;
real lambda;
}
transformed data {
// We join the x observations and desired x prediction points
int n = n_data + n_pred;
array[n] real x;
x[1 : n_data] = x_data;
x[(n_data + 1): n] = x_pred;
// We calculate the Kernel values for all x
matrix[n, n] K;
K = gp_exp_quad_cov(x, alpha, lambda);
// Add nugget on diagonal for numerical stability
for (i in 1 : n) {
K[i, i] = K[i, i] + 1e-6;
}
}
parameters {
// This is what we want to estimate
vector[n] f;
}
model {
// Likelihood is tested against the observations
y_data ~ normal(f[1 : n_data], sigma);
// f is sampled from GP
// The domain of the GP prior is all x
// We assume the mean is always 0
f ~ multi_normal(rep_vector(0, n), K);
}
The model section gives the high-level view of what we’re doing here: simulating those equations from earlier. The main thing to understand is that the domain of GP is both the

Here’s the R code to run that model. I prefer to use CmdStanR – see here for more on that and some general tips.
This is cmdstanr version 0.8.1
- CmdStanR documentation and vignettes: mc-stan.org/cmdstanr
- CmdStan path: /Users/cbowdon/micromamba/envs/rland/bin/cmdstan
- CmdStan version: 2.36.0
variable mean median sd mad q5 q95 rhat ess_bulk ess_tail
lp__ -25.89 -25.62 4.71 4.58 -34.20 -18.74 1.00 1538 2577
f[1] -0.80 -0.79 0.10 0.10 -0.96 -0.63 1.00 3861 3304
f[2] -0.84 -0.84 0.10 0.09 -1.01 -0.68 1.00 4951 3194
f[3] 0.75 0.75 0.10 0.10 0.59 0.90 1.00 4998 3239
f[4] -0.41 -0.41 0.10 0.10 -0.57 -0.24 1.00 5386 3131
f[5] -1.47 -1.47 0.10 0.10 -1.63 -1.30 1.00 5378 2822
f[6] 0.20 0.19 0.10 0.10 0.03 0.36 1.00 5048 3493
f[7] -0.12 -0.13 0.57 0.57 -1.05 0.83 1.00 2267 2691
f[8] -0.20 -0.20 0.38 0.37 -0.82 0.42 1.00 2129 2680
f[9] -0.32 -0.32 0.17 0.17 -0.61 -0.03 1.00 2572 2588
# showing 10 of 48 rows (change via 'max_rows' argument or 'cmdstanr_max_rows' option)
The R-hat and ESS summaries tell you if the model has converged. This one has, but I had to double the maximum treedepth. Let’s now plot the draws of
x_vals <- c(df6$x, x_pred)
draws <- samples$draws(format = "draws_matrix") |>
as_tibble() |>
# Every row is a draw, which we number
mutate(draw = 1:n()) |>
# Since each column is an observation f(x) for x indices, we pivot
pivot_longer(starts_with("f"), names_to = "x", values_to = "y") |>
# And map the x index back to an x value
mutate(
idx = as.numeric(str_extract(x, "[0-9]+")),
x = x_vals[idx],
y = as.numeric(y)
)
ggplot() +
geom_line(data = draws, mapping = aes(x = x, y = y, group = draw), alpha = 0.01) +
geom_point(data = df6, mapping = aes(x = x, y = y), colour = "red") +
geom_text(data = mutate(df6, n = rank(x)), mapping = aes(x = x, y = y, label = n), nudge_x = 0, nudge_y = 1.1) +
geom_segment(data = df6, mapping = aes(x = x, y = y, yend = y + 1), linetype = "dashed") +
theme_minimal()

The observations are shown as red points, and I’ve numbered them for ease of reference. You can see the predictions of

The effect of noise
In that model
Optimising with Cholesky decomposition
We can speed up the simulation with a trick call Cholesky decomposition. We decompose


data {
// Observed data
int n_data;
array[n_data] real x_data;
array[n_data] real y_data;
// Observation error
real<lower=0> sigma;
// x values for which we aim to predict y
int n_pred;
array[n_pred] real x_pred;
// Hyperparameters for the kernel
real alpha;
real lambda;
}
transformed data {
// We join the x observations and desired x prediction points
int n = n_data + n_pred;
array[n] real x;
x[1 : n_data] = x_data;
x[(n_data + 1): n] = x_pred;
// We calculate the Kernel values for all x
matrix[n, n] K;
K = gp_exp_quad_cov(x, alpha, lambda);
// Add nugget on diagonal for numerical stability
for (i in 1 : n) {
K[i, i] = K[i, i] + 1e-6;
}
}
parameters {
// This is what we want to estimate
vector[n] f;
}
model {
// Likelihood is tested against the observations
y_data ~ normal(f[1 : n_data], sigma);
// f is sampled from GP
// The domain of the GP prior is all x
// We assume the mean is always 0
f ~ multi_normal(rep_vector(0, n), K);
}
model <- cmdstan_model(stan_file = "gp-cholesky.stan", exe = "gp-cholesky.stan.bin")
samples <- model$sample(
list(
n_data = nrow(df6),
x_data = as.array(df6$x),
y_data = as.array(df6$y),
sigma = 0.1,
n_pred = length(x_pred),
x_pred = x_pred,
alpha = 1,
lambda = 1
),
parallel_chains = 4,
show_messages = FALSE # disabled to avoid polluting the blog post, should be TRUE
)
samples
variable mean median sd mad q5 q95 rhat ess_bulk ess_tail lp__ -25.77 -25.48 4.77 4.69 -34.13 -18.42 1.00 1469 2478 eta[1] -0.80 -0.80 0.10 0.10 -0.96 -0.64 1.00 5898 3414 eta[2] -0.84 -0.84 0.10 0.10 -1.00 -0.68 1.00 6116 2987 eta[3] 1.26 1.26 0.12 0.12 1.06 1.46 1.00 5400 3419 eta[4] -0.02 -0.02 0.11 0.11 -0.20 0.16 1.00 5701 2939 eta[5] -1.38 -1.38 0.10 0.10 -1.54 -1.22 1.00 8086 2528 eta[6] 0.40 0.40 0.11 0.11 0.22 0.58 1.00 5329 3242 eta[7] 0.01 0.00 0.98 0.95 -1.62 1.62 1.00 7582 2950 eta[8] 0.00 0.01 1.00 1.00 -1.65 1.65 1.00 6981 3104 eta[9] 0.00 0.01 0.99 1.00 -1.68 1.62 1.00 7338 2935 # showing 10 of 95 rows (change via 'max_rows' argument or 'cmdstanr_max_rows' option)
If we run that version convergence is much faster.
< section id="ok-but-why" class="level1">OK but why?
What’s the benefit of this approach? It’s pretty trivial to fit a polynomial or a spline to our data to get some idea of the shape of the function. The polynomial is no good for extrapolation, but neither is the Gaussian Process approach.
x <- df6$x
y <- df6$y
polyfit <- lm(y ~ poly(x, degree=4))
p_y <- predict(polyfit, data.frame(x=-5:5))
ggplot() +
aes(x=x, y=y) +
geom_point(data=df6, colour="red") +
geom_line(data=data.frame(x=-5:5, y=p_y), stat="smooth") +
theme_minimal()
`geom_smooth()` using method = 'loess' and formula = 'y ~ x'

I can think of three benefits to using a Gaussian Process:
- You can visualize the uncertainty around certain regions of the function.
- You can use the samples to answer questions like “what’s the probability that
- You can provide an informative prior, if you have some understanding of what the function should look like already.


These are all the typical benefits to a Bayesian approach. Number two is used in MIPRO prompt optimisation, to determine which region to evaluate next. (Though to be clear my level of understanding with MIPRO is “skimmed the paper, think I can use it” rather than anything impressive.)
< section id="wrapping-up" class="level1">Wrapping up
So we’ve seen:
- what Gaussian Processes are
- how to they are parameterised by a kernel, and the hyperparameters affect the process
- how to sample functions from a GP
- how to model a GP and estimate its posterior with Stan (a GP regression)
- how to optimise the computation with a Cholesky decomposition
- why this is more interesting/useful than a simple polynomial fit
Where next? The next thing to figure out is Bayesian Optimisation itself, which adds an acquisition function into the mix. That is a cost function that will decide what regions to explore to discover the maximum of the function. But that will have to wait for another day.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.