

Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.


Implementing parallel execution in your code can be both a blessing and a curse. On the one hand, you’re leveraging more power your CPU has to offer and increasing execution speed, but on the other, you’re sacrificing the simplicity of single-threaded programs.
Luckily, parallel processing in R is extremely developer-friendly. You don’t have to change much on your end, and R works its magic behind the scenes. Today you’ll learn the basics of parallel execution in R with the R doParallel package. By the end, you’ll know how to parallelize loop operations in R and will know exactly how much faster multi-threaded R computations are.
Looking to speed up your data processing pipelines? Take a look at our detailed R Data Processing Frameworks comparison.
Table of contents:
- What is Parallelism and Why Should You Care?
- R doParallel – Everything You Need to Know
- Summing up R doParallel
What is Parallelism and Why Should You Care?
If you’re new to R and programming in general, it can be tough to fully wrap your head around parallelism. Let’s make things easier with an analogy.
Imagine you’re a restaurant owner and the only employee there. Guests are coming in and it’s only your responsibility to show them to the table, take their order, prepare the food, and serve it. The problem is – there’s only so much you can do. The majority of the guests will be waiting a long time since you’re busy fulfilling earlier orders.
On the other hand, if you employ two chefs and three waiters, you’ll drastically reduce the wait time. This will also allow you to serve more customers at once and prepare more meals simultaneously.
The first approach (when you do everything by yourself) is what we refer to as single-threaded execution in computer science, while the second one is known as multi-threaded execution. The ultimate goal is to find the best approach for your specific use case. If you’re only serving 10 customers per day, maybe it makes sense to do everything yourself. But if you have a striving business, you don’t want to leave your customers waiting.
You should also note that just because the second approach has 6 workers in total (two chefs, three waiters, and you), it doesn’t mean you’ll be exactly six times faster than when doing everything by yourself. Managing workers has some overhead time, just like managing CPU cores does.
But in general, the concept of parallelism is a game changer. Here’s a couple of reasons why you must learn it as an R developer:
- Speed-up computation: If you’re old enough to remember the days of single-core CPUs, you know that upgrading to a multi-core one made all the difference. Simply put, more cores equals more speed, that is if your R scripts take advantage of parallel processing (they don’t by default).
- Efficient use of resources: Modern CPUs have multiple cores, and your R scripts only utilize one by default. Now, do you think that one core doing all the work while the rest sit idle is the best way to utilize compute resources? Likely no, you’re far better off by distributing tasks across more cores.
- Working on larger problems: When you can distribute the load of processing data, you can handle larger datasets and more complex analyses that were previously out of reach. This is especially the case if you’re working in data science since modern datasets are typically huge in size.
Up next, let’s go over R’s implementation of parallel execution – with the doParallel package.
R doParallel – Everything You Need to Know
What is R doParallel?
The R doParallel package enables parallel computing using the foreach package, so you’ll have to install both (explained in the following section). In a nutshell, it allows you to run foreach loops in parallel by combining the foreach() function with the %dopar% operator. Anything that’s inside the loop’s body will be executed in parallel.
This rest of the section will connect the concept of parallelism with a practical example by leveraging foreach and doParallel R packages.
Let’s begin with the installation.
How to Install R doParallel
You can install both packages by running the install.packages() command from the R console. If you don’t want to install them one by one, pass in package names as a vector:
install.packages(c("foreach", "doParallel"))
That’s it – you’re good to go!
Basic Usage Example
This section will walk you through a basic usage example of R doParallel. The goal here is to wrap your head around the logic and steps required to parallelize a loop in R.
We’ll start by importing the packages and using the detectCores() function from the doParallel package. As the name suggests, it will return the number of cores your CPU has, and in our case, store it into a n_cores variable:
library(foreach) library(doParallel) # How many cores does your CPU have n_cores <- detectCores() n_cores
My M2 Pro Macbook Pro has 12 CPU cores:


Image 1 – Number of CPU cores
The next step is to create a cluster for parallel computation. The makeCluster(n_cores - 1) will initialize one for you with one less core than you have available. The reason for that is simple – you want to leave at least one core for other system tasks.
Then, the registerDoParallel() functions sets up the cluster for use with the foreach package, enabling you to use parallel execution in your code:
# Register cluster cluster <- makeCluster(n_cores - 1) registerDoParallel(cluster)
And that’s all you have to setup-wise. You now have everything needed to run R code in parallel.
To demonstrate, we’ll parallelize a loop that will run 1000 times (n_iterations), square the number on each iteration, and store it in a list.
To run the loop in parallel, you need to use the foreach() function, followed by %dopar%. Everything after curly brackets (inside the loop) will be executed in parallel.
After running this code, it’s also a good idea to stop your cluster.
Here’s the entire snippet:
# How many times will the loop run
n_iterations <- 1000
# To save the results
results <- list()
# Use foreach and %dopar% to run the loop in parallel
results <- foreach(i = 1:n_iterations) %dopar% {
# Store the results
results[i] <- i^2
}
# Don't fotget to stop the cluster
stopCluster(cl = cluster)
The output of this code snippet is irrelevant, but here it is if you’re interested:

Image 2 – Computation results
And that’s how you can run a loop in parallel in R. The question is – will parallelization make your code run faster? That’s what we’ll answer next.
Does R doParallel Make Your Code Execution Faster?
There’s a good reason why most code you’ll ever see is single-threaded – it’s simple to write, has no overhead in start time, and usually results in fewer errors.
Setting up R loops to run in parallel involves some overhead time in setting up a cluster and managing the runtime (which happens behind the scenes). Depending on what you do, your single-threaded code will sometimes be faster compared to its parallelized version, all due to the mentioned overhead.
That’s why we’ll set up a test in this section, and see how much time it takes to run the same piece of code on different numbers of cores, different numbers of times.
The test() function does the following:
- Creates and registers a new cluster with
n_coresCPU cores, and stops it after the computation. - Uses
foreachto perform iterationn_iternumber of times. - Keeps track of time needed in total, and time needed to do the actual computation.
- Returns a
data.framedisplaying the number of cores used, iterations made total running time, and total computation time.
Here’s what this function looks like in the code:
test <- function(n_cores, n_iter) {
# Keep track of the start time
time_start <- Sys.time()
# Create and register cluster
cluster <- makeCluster(n_cores)
registerDoParallel(cluster)
# Only for measuring computation time
time_start_processing <- Sys.time()
# Do the processing
results <- foreach(i = 1:n_iter) %dopar% {
i^2
}
# Only for measuring computation time
time_finish_processing <- Sys.time()
# Stop the cluster
stopCluster(cl = cluster)
# Keep track of the end time
time_end <- Sys.time()
# Return the report
return(data.frame(
cores = n_cores,
iterations = n_iter,
total_time = difftime(time_end, time_start, units = "secs"),
compute_time = difftime(time_finish_processing, time_start_processing, units = "secs")
))
}
And now for the test itself. We’ll test a combination of using 1, 6, and 11 cores for running the test() function 1K, 10K, 100K, and 1M times. After each iteration, the results will appended to res_df:
res_df <- data.frame()
# Arbitrary number of cores
for (n_cores in c(1, 6, 11)) {
# Arbitrary number of iterations
for (n_iter in c(1000, 10000, 100000, 1000000)) {
# Total runtime
current <- test(n_cores, n_iter)
# Append to results
res_df <- rbind(res_df, current)
}
}
res_df
Here are the results:

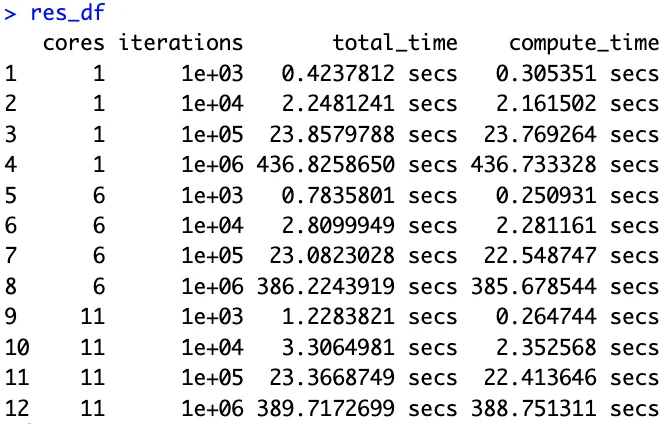
Image 3 – Runtime comparisons
Looking at the table data can only get you so far. Let’s visualize our runtimes to get a better grasp of compute and overhead times.
There’s a significant overhead for utilizing and managing multiple CPU cores when there are not so many computations to go through. As you can see, using only 1 CPU core took the longest in compute time, but managing 11 of them takes a lot of overhead:

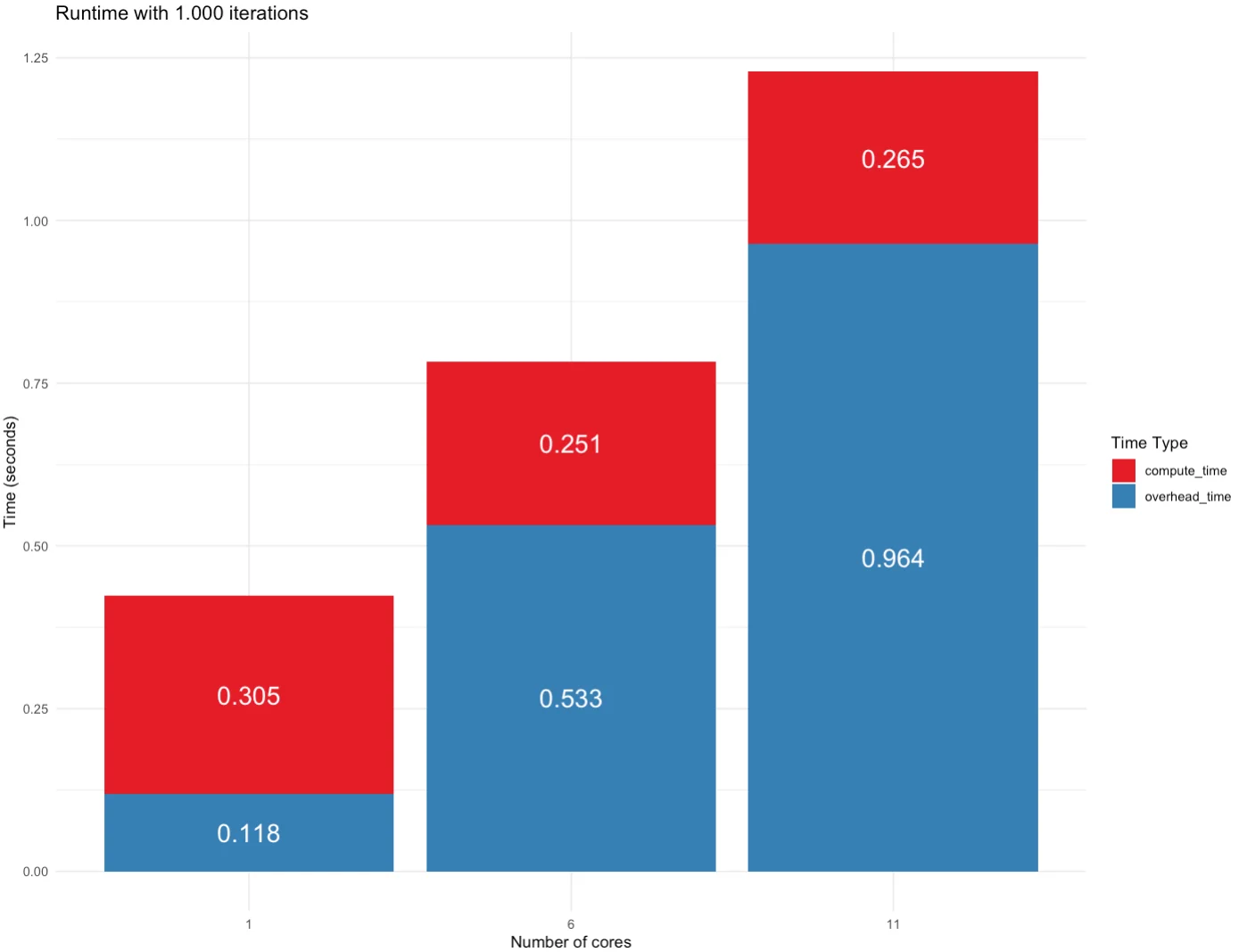
Image 4 – Runtime for 1K iterations
If we take this to 10K iterations, things look interesting. There’s no point in leveraging parallelization at this amount of data, as it increases both compute and overhead time:
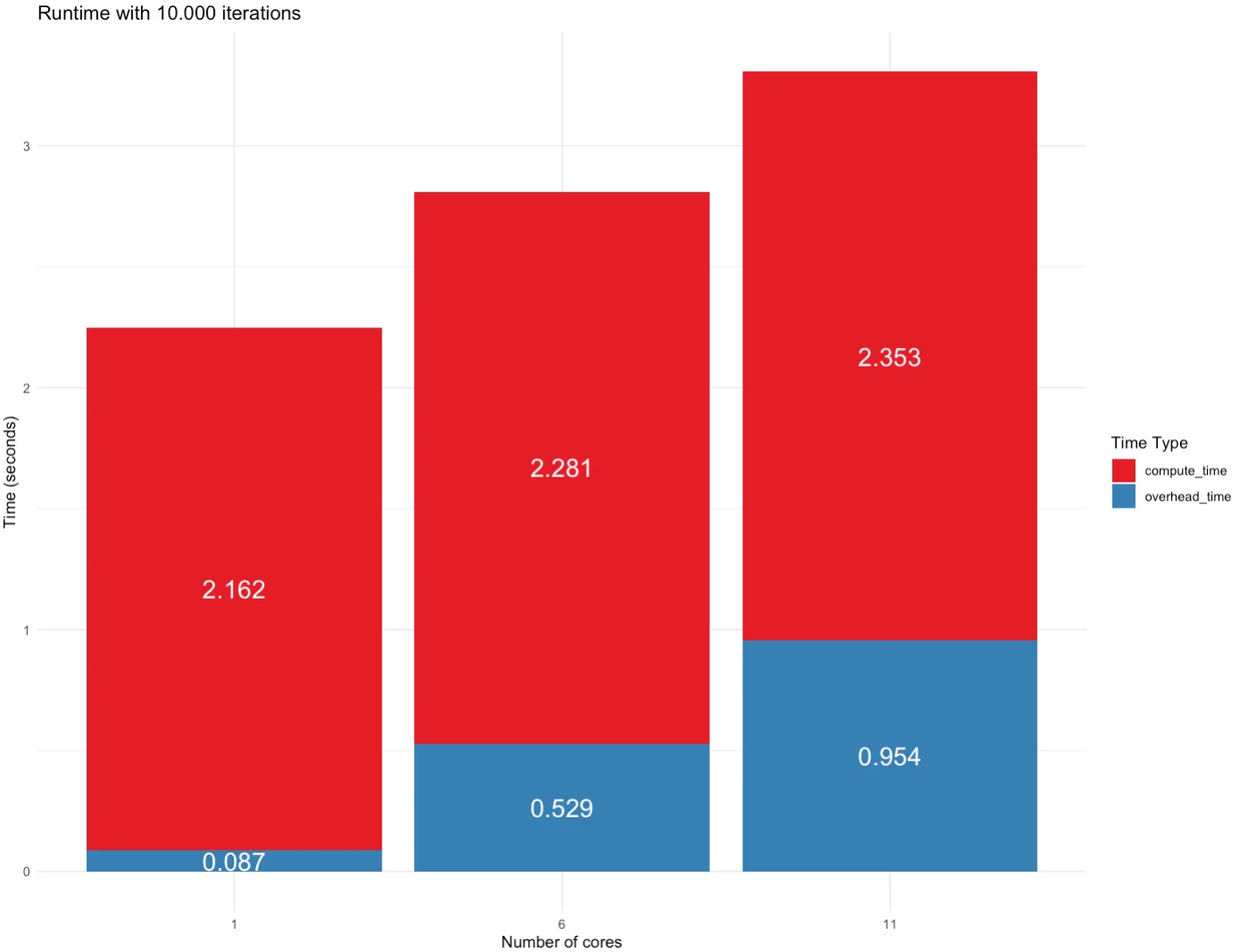
Image 5 – Runtime for 10K iterations
Taking things one step further, to 100K iterations, we have an overall win when using 6 CPU cores. The 11-core simulation had the fastest runtime, but the overhead of managing so many cores took its toll on the total time:
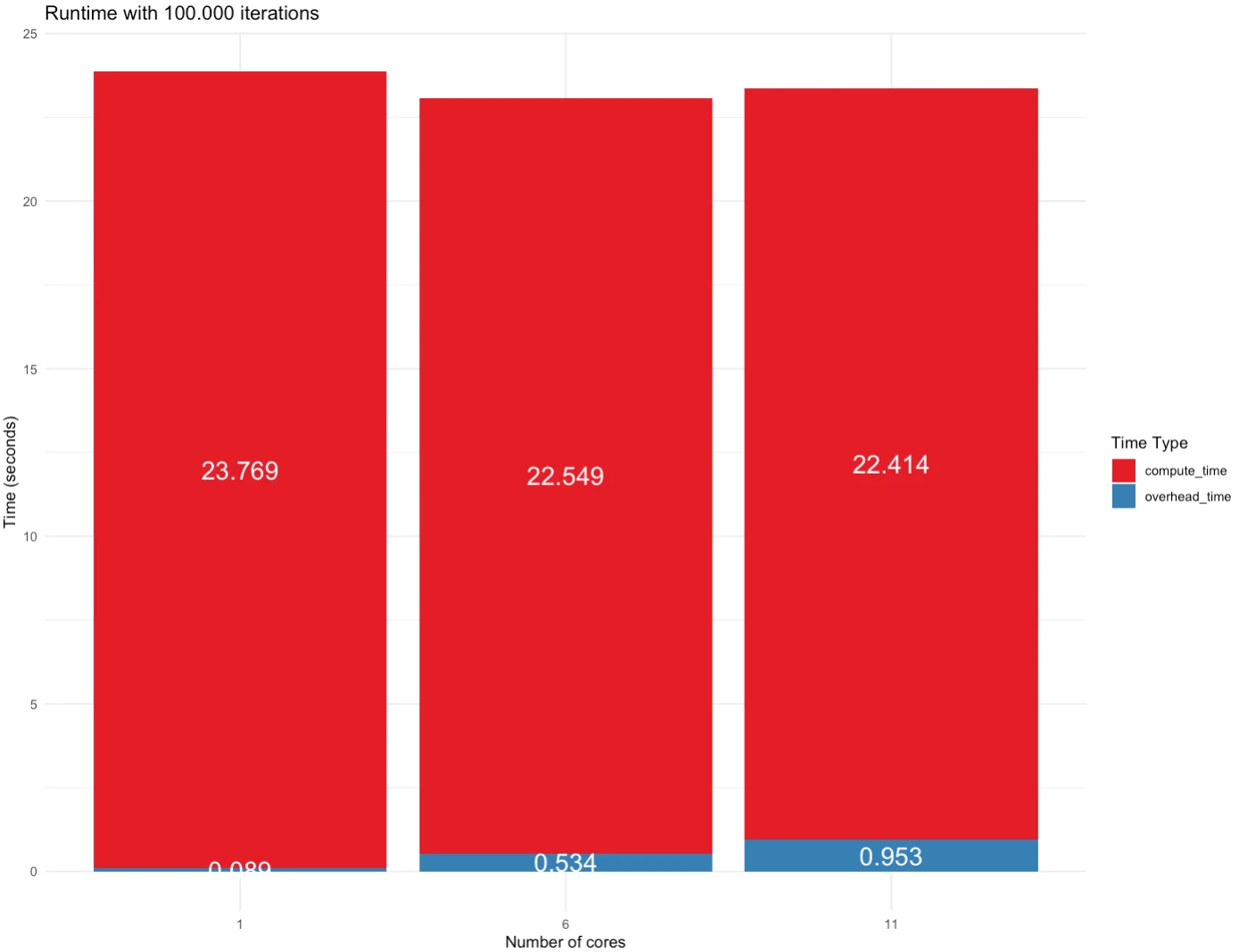
Image 6 – Runtime for 100K iterations
And finally, let’s take a look at 1M iterations. This is the point where the overhead time becomes insignificant. Both 6-core and 11-core implementations come close, and both are faster than a single-core implementation:
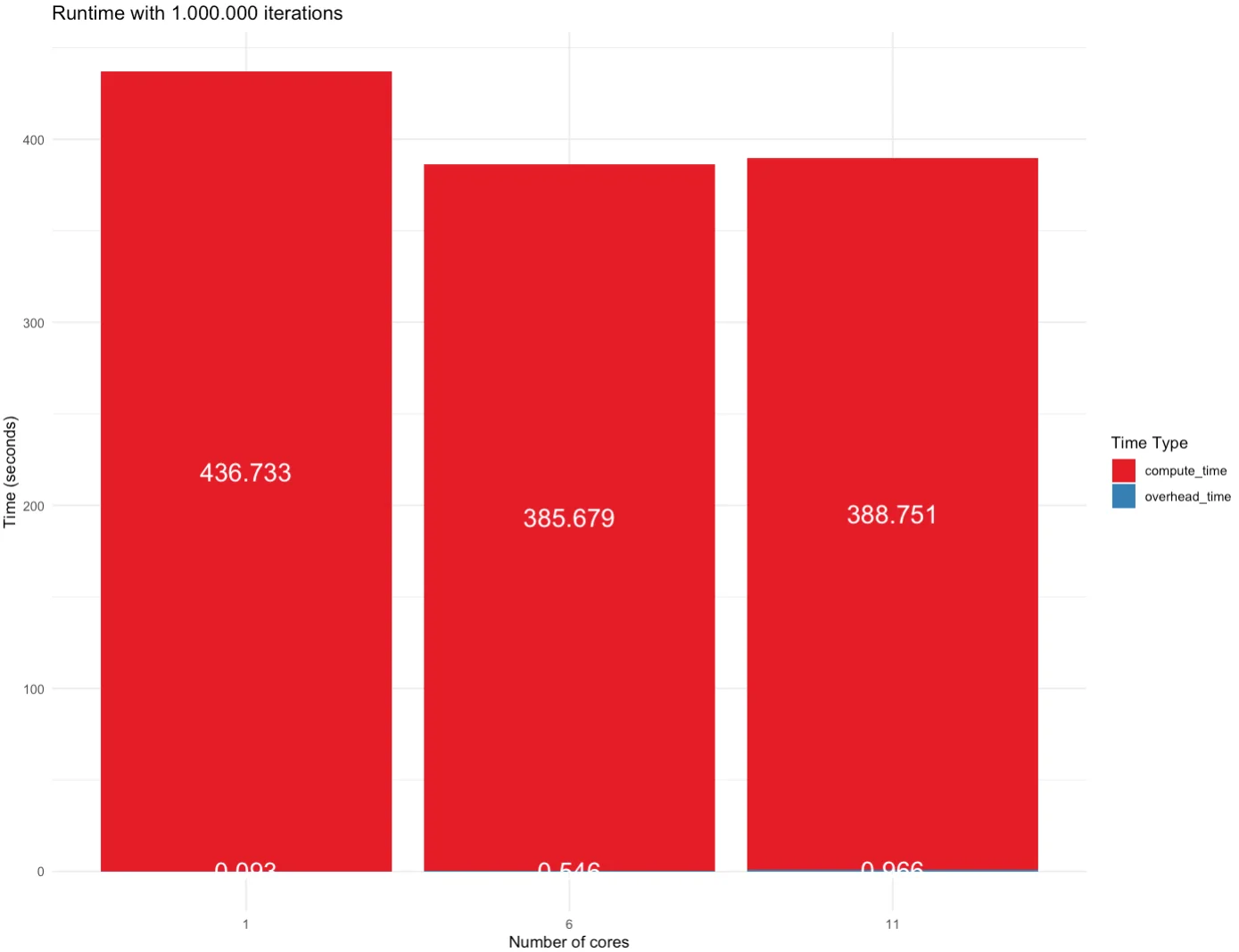
Image 7 – Runtime for 1M iterations
To summarize the results – parallelization makes the compute time faster when there’s a significant amount of data to process. When that’s not the case, you’re better off sticking to a single-threaded execution. The code is simpler, and there’s no overhead to pay in terms of time required to manage multiple CPU cores.
Summing up R doParallel
R does a great job of hiding these complexities behind the foreach() function and %dopar% command. But just because you can parallelize some operation it doesn’t mean you should. This point was made perfectly clear in the previous section. Code that runs in parallel is often more complex behind the scenes, and a lot more things can go wrong.
You’ve learned the basics of R doParallel today. You now know how to run an iterative process in parallel, provided the underlying data structure stays the same. Make sure to stay tuned to Appsilon Blog, as we definitely plan to cover parallelization in the realm of data frames and processing large datasets.
Did you know R supports Object-Oriented Programming? Take a look at the first of many articles in our new series.
The post appeared first on appsilon.com/blog/.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.