

Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
OK, I’m sorry for the clickbait title. But I really do think a lot of the insights in this guide are trivial and very easy to understand yet surprisingly unknown to many people.1
In this guide we will discuss how to lose weight or solve (almost) any other kind of problem2, and we’ll use statistics and R along the way.
Have you ever tried to
- lose weight, or
- gain muscles through exercise, or
- struggled with saving money and cutting spending, or
- wanted to reduce your (or your company’s or the world’s) carbon footprint, or
- wanted to reduce poverty or housing prices in your country as a politician, …
…and you got frustrated at some point because you did not seem to make any progress? I, for instance wanted to lose weight for many years and tried out a couple of methods I found online. But I wasn’t making any sustainable progress – until I implemented the systematic method described in this article, which is when I lost 20 kilos (40 pounds) and kept that level until today. Below are the 6 steps I followed to achieve this.
I will mainly stick to the weight loss example throughout the article, but will also sometimes discuss other examples at quite some length (e.g. political problems or industrial production), hoping that some of those examples will be meaningful to some of you.
1. Define a S.M.A.R.T. goal
I know this sounds like coming out of some business consultant’s bullshit presentation slides, but this for once is an acronym you may want to keep in mind. Because: It is really surprising how many projects fail due to a lack of a clear goal. (As an example, you can think of your government’s response to the Covid pandemic 2020-2022.) And the “S.M.A.R.T.” framework is helpful to remember when formulating a goal. “S.m.a.r.t.” stands for “specific, measurable, achievable, realistic, timely”. So instead of setting yourself goals such as:
- “My goal is to look shredded” (not measurable nor timely),
- “From now on I’ll go to the gym more often” (not specific),
- “I want to lose 10 kg until that party next week” (not realistic),
something like the following would be better:
- “My goal is to lose 5 kg (according to my weekly average bodyweight measured in the morning) within the next 100 days.”
Formulating your goal like this ensures that you’ll be able to measure your progress, evaluate if you’re on track or not, keep yourself motivated, and finally be able to celebrate having reached the goal (or not) when the time’s up and you’re looking at the data. Unspecific and untimely goals tend to be forgotten over time like those New Year’s resolutions where people set out to “eat healthier” or “work out more often” and nothing is left of it by February.
Note that what’s realistic depends of course on your current condition, your level of self-discipline in implementing new methods, etc. Also, it’s important to note that no internet tutorial can tell you what a good goal is in the first place. You need to find out for yourself *what* you want to achieve and *why*. The “why” is your higher-level motivation to do all this. Do you want to lose weight in order to look more attractive to potential partners, or to live healthier, or to be able to play soccer with your kids without losing your breath? Imagine you had a huge oil painting in your room depicting your future self, and every morning you look at that painting. What’s on the painting? In my case, it’s me walking through a green field carrying my kids on my arms and shoulders. Very cheesy, I know, but a myth like this can be a powerful motivator. The guy on the painting certainly can’t carry an additional 20 kg (40 pounds) of body fat, can he? Once you have your “why”, it will be straightforward for you to deduce your “what”. Make sure to formulate it in a “smart” way.
Another important aspect: In the example of losing weight, finding a reasonable formulation for a “smart” goal has been rather straightforward. The same is true when dealing with other topics with established and unambiguous measurements; e.g., if you want to cut spending and save money, or if you want to increase your bench press personal best. It gets a bit more complicated when you want to achieve something that is more difficult to measure (e.g., reduce depression, be more productive at work, appeal more to potential romantic partners, improve your overall health, etc.). In those cases, there’s a bit more work to be done in the operationalization (i.e. making your goal measurable and specific). A simple example, if your goal were to reduce depression: Every day I’m entering a number on a scale of 1-10 into a spreadsheet denoting how well I feel (mentally) on that day. Past year’s average value was 6.8. Although being a crude measurement, it gives me a benchmark and an easy way to formulate a goal such as: I want to stay above 7 on average next year. This lets me track my progress and see whether any methods I try out have a significant effect over time or not. Note of course that so far we only formulated a goal. How we want to achieve this goal needs yet to be defined.
Can you have multiple goals at the same time?
In the real world, most people/companies/countries are pursuing multiple goals at the same time. For example: many people want to lose weight and also build muscle mass. That’s possible, but, as you certainly know, the former implies a decrease in your body weight while the latter causes you to gain weight. So you cannot judge your progress simply by standing on a scale (as the goal we formulated above implies). You will have to formulate your goals in a different way than we did above, possibly including measurements that are a bit more difficult to take, such as “percentage body fat” or “lean muscle mass”. This issue can be found very often when there is more than one goal people want to achieve. Think about, e.g.:
- Companies having goals to a) produce high-quality products with as few defects as possible, which b) cost as little as possible to produce;
- Politicians promising to make a) housing more affordable, but also b) saving the environment and reducing urban sprawl, and also c) promoting population growth.
While not impossible, you can easily see how these goals are in conflict and there are probably trade-offs such that maximizing one goal will require compromising on another goal.
So the first thing you have to do is make sure that formulating your goals in a “s.m.a.r.t.” way does not logically imply that it’s impossible to reach all of them at the same time. This would be the case, i.e., if your first goal was “X kg weight loss” and your second goal was “Y kg weight gain” (in many cases it’s not *that* obvious). In this case, you would have to go for, e.g., “reduce body fat percentage” and “increase lean muscle mass” instead, which, as noted above, would be more complicated to measure, increasing the obstacles for you to design a feasible plan and stick to it.
Even if not logically impossible; when you have multiple goals, you have to think about whether there are interactions or cross-dependencies between the goals. If that is the case, it will complicate analyzing their top influences and carrying out interventions to improve them (i.e. the next three steps in this guide). Because it is often easy to find an intervention which will improve goal A but which at the same time deteriorates goal B. Examples:
- Changing your product’s material from metal to plastic will greatly reduce manufacturing costs (goal B), but will likely compromise product quality (goal A).
- Fasting for 14 days will certainly lead to weight loss (goal A) but will make it impossible to gain muscle mass (goal B).
Instead you would want to implement a strategy which lowers costs but is at least neutral regarding product quality, which is naturally harder to find. The same goes for weight loss and muscle gain. It is thus sometimes necessary to prioritize one goal over another, instead of just pretending you can achieve everything at once.
For the sake of simplicity, let’s assume you have prioritized goal “weight loss” and we’re thus trying to achieve a 5 kg (10 lbs) reduction within 100 days. Let’s move on to the really interesting part.
2. Determine the top influences on your problem
I cannot overstate how important this part is.
Let’s say you call the chief finance officer (CFO) of a large company, whose main goal is to cut spending, and you’re asking him at 3 am during the night what his top 3 items of expenditure are: You’d expect he’d instantly be able to cite those including the amount in dollars year-to-date up to the second decimal place. Right?
Similarly, if you’re a politician and your goal is to reduce poverty or microplastics in the ocean, you’d certainly know the top 3 demographic groups most affected by poverty in your country (Single mothers? Pensioners? People without formal education? … ), as well as the top sources of microplastics waste (PET bottles? Car tire wear particles? Polyester clothes being washed? Plastic-based drag nets? Marine coatings?). Because, clearly, depending on whether it’s the single mothers or rather the pensioners, a government program you design to reduce poverty will look very different. The same goes for if you want to really make an impact in reducing the amount of microplastics that enter the ocean, which evidently presupposes knowing where most of the current waste originates from.
And likewise, someone who wants to lose weight needs to know the top 3 influences on their weight loss (or the lack of it) – for instance, the top sources of calorie intake by food type. Is it sugary drinks? Alcohol? Late-night snacks? Heavy breakfasts?
I am giving these lengthy examples here because in my experience, the CFO and the politician as well as you and I who want to lose weight will give wrong answers to these questions. We all have a gut feeling, or we remember something that we read somewhere about what the most important drivers are, and this will often be partly correct, but only partly. Most people, when shown a very simple statistic based on a quick but meaningful collection of data, will be surprised at the result. They will say something such as: “Whoa, I knew that we spend a lot on A, but is it *that* much?”, or: “What? I correctly anticipated A being our biggest problem, but I’m really surprised to see B ranking second!”
This is something I struggle to understand because if I am committed to a certain goal, I should at the very least know the top 3 (or 4 or 5) most important influences on why we’re currently not achieving the goal, right? But many people often in fact don’t. And this is why the CFO currently has a big project to cut spending regarding the 6th most important item of expenditure, and four years later the board will ask him why overall spending has nevertheless increased. And the politician is designing a new social security program which 3.7% of all people affected by poverty will benefit from, but the overall picture will remain mostly unchanged. And the European Union is putting a ban on plastic bags in stores when a much bigger source of microplastics in the water seems to be synthetic clothes, which are seeing ever increasing production numbers.
And I myself have made the same mistake in the past: I was reading about intermittent fasting, and I tried it out skipping breakfasts, and while it certainly might have many benefits, I didn’t achieve much progress with my weight loss – because calorie intake during breakfast was far from being my biggest issue! (See below) So how do we know what the biggest issues are? The first thing you might want to do is drawing a cause-and-effect chart. This type of chart shows your “theoretical model” of what plausibly are significant influences on your goal. Here is an example of a cause-and-effect chart, also known as a so-called directed acyclical graph (DAG):


Fig. 1: Very simplified cause-and-effect chart (directed acyclical graph, DAG)
Why bother drawing this? Well, if you want to solve a problem, you need to know what can *generally* cause this problem. This guides you as to which data to collect – which will show you what specifically causes the problem *in your case*. Drawing a theoretical graph is common in science where researchers want to uncover causal effects and seek to rule out alternative explanations (see the tutorial here). In industrial manufacturing and quality management, cause-and-effect charts are also known as Ishikawa or fishbone diagrams, where you reflect on which processes, materials, etc., might cause a certain defect found in a product.
In our example here (our goal is to lose weight), drawing this kind of graph wouldn’t have been absolutely necessary. Because although I’m not a health expert, the factors influencing weight loss are generally fairly well-known:
- I think I need to look at nutrition, both the absolute calorie intake as well as the composition regarding carbs, fat, and protein.
- The next most important factor is physical activity. There are various ways I could measure this (e.g., counting daily steps, an exercise protocol, etc.). Note the interaction with nutrition (you go for a run, you’re more likely to eat more afterwards).
- Amount and quality of sleep can also affect weight gain vs. loss, although probably less strongly.
- Many other factors can play a role, among them genetic predisposition. Since I cannot change my genes, there’s no point in collecting data. (This is an important general point! If you want change over time in Y (e.g., your weight), you need to focus on determinants (X) that you can also possibly change).
Again, if you’re trying to lose weight, you can probably skip this drawing exercise. In other scenarios, it might absolutely make sense taking a few minutes to contemplate what the potential influences on your problem might be because it is not that obvious. You might even need to consult experts or look up some literature on the issue. Examples:
- Your goal is to strengthen your immune system and reduce the yearly number of episodes of you having a cold. You need to determine what the biggest factors are which might potentially cause your immune system to be seemingly deficient, such that you can later figure out what you can do about it.
- Your goal is to improve the performance of an IT system which currently takes too long to load. You first need to determine what the biggest factors might be: inefficient code, insufficient physical memory, internet connection issues, etc.
In these cases, you definitely need an expert’s advice or a literature research in order to guide you what the potential sources of your problem might be (if don’t have any expertise yourself). In other cases, this is not strictly necessary and you can simply postulate potential influencing factors that are plausible according to common sense. Example:
- You’re a basketball coach and your team is on a losing streak, your goal is to win 50% of matches by the end of the season. Without being a prolific expert, you could think of factors such as shooting accuracy (from the field, from the free-throw line, etc.), passing accuracy, number of rebounds, overall fitness… For all these factors you would then collect data and compare the outcome to some reference (e.g., the league’s average values) to see where your team is lacking behind the most.
In short, a cause-and-effect diagram informs you what data you need to collect in order to determine the top influences on your problem. How do you know what to draw on your cause-and-effect chart?
- Literature research,
- experts’ advice,
- or simply what’s plausible according to common sense.
Let’s move on to the data collection and analysis. If your goal is to lose weight, here is a very simple way of doing that: For one week, I wrote down everything I ate (and drank, if it contained calories) into a spreadsheet, including rough guesses for calories and breakdown by carbs/fat/protein. I just entered whatever I ate into an online search and found the (approximate) nutritional values. My list looked like this:


Fig. 2: Example of data collection
I know this looks like a very annoying thing to do and it indeed is – but you’re only doing this for one week. (Of course, the longer you collect data the better, but one week is usually a good start.) And this *will* bring you very valuable insights, so don’t skip this. You can use a spreadsheet in Excel, or use an app on your phone, or enter the data directly into an R data.frame, or write it on a sheet of paper – as is most convenient for you.
Really, you need to do this and you won’t regret it. Three things to pay attention to:
- You need to track what you believe will be the most important influences on your goal. (How do you know what are the most important influences? –> See cause-and-effect chart above). In my list here, for reasons of simplicity, I didn’t include physical activity, sleep, or other factors that influence my weight. Arguably, nutrition is the most important factor which is why this analysis was still very revealing for me, but you might want to include other factors as well (e.g., via a step counter or an exercise protocol).
- The data collection needs to be as unbiased as possible. This means: Pick a normal week (not when you’re, e.g., on holidays), act normal and try not to let the fact that you need to write it down influence what you’re eating and drinking. This only makes sense if you’re collecting valid data.
- The values in here need not be 100% accurate. Often, I took a reasonable guess; e.g., when I was eating at work and I had some pasta, I figured “this is probably 200 grams of pasta” and I looked up the nutritional values for that. Measurement errors are ok, as long as you’re not spectacularly over- or underestimating certain types of food, and as long as there is no systematic bias.
After you’ve collected the data, let’s analyze it in a very simple way. We don’t need any advanced statistical models or algorithms here – we will simply draw a bar chart. If you don’t have any programming or data analytics skills whatsoever, you could still do this analysis simply by hand on a sheet of paper or an Excel spreadsheet by, e.g., summarizing calories for each “category”, dividing the results by the number of days, and then drawing some columns. Since this is a blog on R, here is some R code to achieve this. Assuming you have an xlsx file with columns named the way I have named them in the screenshot above, the following will work once you adapt the path to where your spreadsheet is saved:
library(tidyverse)
d <- readxl::read_excel("C:/My/Path/myfile.xlsx"))
n_days <- n_distinct(d$Date)
#Overall calorie intake per day
sum(d$`kcal (ca.)`) / n_days
#Calorie intake by food category (daily average)
d %>% group_by(Category) %>%
summarise(cal = sum(`kcal (ca.)`, na.rm=T) / n_days) %>%
mutate(Category = factor(Category, levels = Category[order(cal)])) %>%
ggplot(aes(x=Category,y = cal, label=round(cal,0))) +
theme_minimal() + geom_col(fill="lightblue") +
geom_label() + coord_flip() +
ggtitle("Daily average calory intake (kcal) by food category",
subtitle = "Data collected between 07 and 13 September 2023") +
xlab("") + ylab("")
If this is the first time you use the “tidyverse” in your R installation, you have to install it via install.packages(“tidyverse”) before running the code above. Here is the output once the code runs succesful:

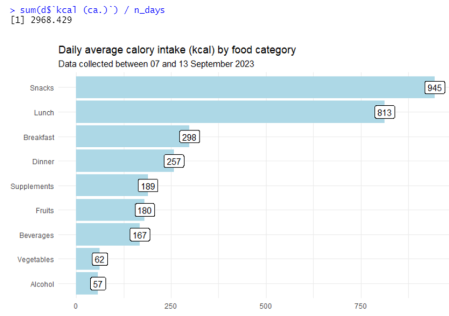
Fig. 3: Output from Code: My top sources of calorie intake
This kind of chart is also called a “Pareto analysis”, according to the Pareto principle which says that usually, 20% of the items on your list cause 80% of the problems. Find out what those 20% are which cause most of the issues and prioritize working on them, instead of wasting time on the other 80% which barely gets you any closer to your goal.
Looking at the graph above, you can easily see how my typical day looks like: I have little for breakfast (or skip it completely), eat a lot for lunch, eat little for dinner (or skip it completely), and then when the kids are put to bed, my wife and I take out the chocolate, potato chips, etc.
You might ask: Do you really need this type of data collection and analysis? You probably knew that “snacks” are a bigger issue than, say, breakfast? Of course I knew that late-night snacks are the one most important issue for me. Nevertheless, I was surprised to see just how large that bar is! Combined with the other information on this chart, it was really an eye-opener although I thought I knew my eating habits quite well. This once again underlines what W. Edwards Deming was saying 40 years ago:
“Without data, you’re just another person with an opinion.”
And that opinion will often be not too far away from the truth (in which case the analysis will still provide valuable insights), but sometimes it will also be far away from it.
Looking at the graph, it is easy to see why you need to design an intervention that is specifically tailored to your habits. You will find a lot of advice online or from coaches that say very reasonable things such as “cut the sugary drinks” or “cut the alcohol” or “try intermittent fasting, skipping breakfast”, but for me all these methods would not address the top influences of my problem. I would be working on the 20% of the problem, not the 80%.
There are more things we can analyze with the data. For instance, we could dive deeper into the “lunch” category, grouping the data by the “what” column to see what sorts of food are mostly responsible for my high calorie intake at lunch. I’m skipping this because big lunches are acceptable for me since I’m usually having (almost) nothing for breakfast. Let’s instead show a breakdown of the total calorie intake by carbs, fat, and protein:
d %>% select(c(Date, `Carbs (g)`, `Fat (g)`, `Protein (g)`)) %>%
pivot_longer(cols = c(`Carbs (g)`, `Fat (g)`, `Protein (g)`)) %>%
group_by(name) %>%
summarise(grams = sum(value, na.rm=T) / n_days) %>%
mutate(Category = factor(name, levels = name[order(grams)])) %>%
ggplot(aes(x=Category,y = grams, label=round(grams,0))) +
theme_minimal() + geom_col(fill="lightblue") +
geom_label() + coord_flip() +
ggtitle("Daily average intake of carbs, fat, and protein (in grams)",
subtitle = "Data collected between 07 and 13 September 2023") +
xlab("") + ylab("")
This gives us the following output:


Fig. 4: Breakdown of my calorie intake by nutritional components
Having this analysis lets you compare the values to reference values and determine whether you have any deficiencies. Without being an expert, I’d say my values look alright and there’s no need to derive any specific action. Also, as you will probably know, there are all sorts of recommendations from doctors or fitness coaches, especially regarding protein intake, ranging from “don’t pay attention unless you’re malnourished” to “eat at least 200 g of protein per day”. I won’t dive deeper into this topic (and I don’t have any expertise to do so), just one small remark: Most convenience food (such as the pasta form the canteen and of course snacks such as potato chips) is usually high in carbs and fat but low in protein, causing you to remain hungry although you’ve eaten tons of calories already. Thus, the analysis above can tell you whether lack of protein intake might be an issue for you.
A different example: My father wanted to save energy, so he got rid of his old (functioning!) dishwasher and bought a new, more energy-efficient one (which was defective shortly after the installation, whereas the old one had run smoothly for more than 20 years, but that’s another story). And he was suggesting we’d do the same, since we also had a very old dishwasher. I was wondering if or when there would be any return on this investment, so I did a couple of measurements with an electric meter in my home. It turned out the dishwasher was only the 7th most important source of energy usage for us. If I had bought a new dishwasher, this would have been quite an investment for a rather small improvement in energy consumption, and I would be working on the 20% of the problem rather than the 80% (the latter here in Germany usually being heating and warm water). I didn’t ask my father if his energy bill decreased noticeably, but I don’t think it did.
What if the top influences on my problem are more difficult to determine?
So far we have looked at examples where it was trivial to analyze the data: Count calories, dollars, power consumption in kWh, etc., and group the results by type of food, expenditure, electrical consumers, etc.
Let’s finish this section with one example where the analysis of the top issues is a bit more complicated. Let’s say you’re a politician and you want to solve the housing crisis. As you will know, housing prices have skyrocketed in many countries over the past few years. Your goal is to make housing more affordable, which is why you want to identify the top drivers of the increase in prices. You devise a causal diagram with possible causes of the current rise in prices, which lists e.g.:
- Decreased supply, i.e. fewer new homes being built compared with previous years;
- Increased demand due to population growth/ immigration being stronger than in previous years;
- Increased demand due to higher per-capita living space over time;
- Lower interest rates encouraging investments into real estate as opposed to e.g. savings deposits or state bonds, and also making loans more affordable;
- Rising costs of raw materials and/or labor driving prices for new homes;
- Government regulations requiring home owners to make renovations or updates, e.g. for environmental reasons;
- etc.
These factors are certainly difficult to disentangle. However, there are statistical ways to do that, which allow you to decompose an increase in prices into a part that is due to factor A and a part that is due to factor B, etc. In the end you can get a graph like in Figure 3, showing the strongest drivers of your issue.
Without getting too deep into the details, here is an outline of how you could tackle this issue:
- Collect time-series data on a sub-national level for your most important indicators. Example: For all 50 US states, or better yet for all counties or census tracts, you collect data on house prices, population numbers, construction activities, etc., for at least two points in time.
- Run a statistical model to estimate the causal effect of interest. Remember not to throw all variables into the model but only the ones that are confounders according to your theoretical model (see the guide here).
To do this, there are a number of possible methods, most notably:
- Difference-in-difference: A simple yet efficient way to estimate an effect once you have organized your data in a meaningful way. Example: Housing prices are compared 2023 vs. 2013 between two groups of counties: a high-population growth and a low-growth group, which are otherwise similar (e.g. similar per-capita GDP, possibly using a matching algorithm). You then compare the growth rates in housing prices (“difference-in-difference”); i.e. if prices in group A grew by 70% whereas they only grew by 35% in group B, you conclude that population growth is responsible for half of the price increase (provided your selection of the data was meaningful and unbiased).
- Panel regression: You can use methods such as a fixed-effects panel regression to isolate the effect of an effect such as population growth on housing prices. The important requirement is that both X (population growth) and Y (housing prices) are changing over time. A fixed-effects regression then does something called the “within-transformation”, i.e. it disregards differences in the average housing price across the observation period between, say, New York City and Maricopa County, AZ.
Instead, it looks at whether “within” the time series of New York City, periods with stronger population growth are associated with periods of stronger housing price increases.
Panel regression is such an important tool, please remind me to write a tutorial on this topic if there isn’t one in a few months and you’re still reading this (and you’re still interested).
Both approaches do the very important thing of removing all unobserved heterogeneity between counties; i.e. all reasons for why some cities are generally more expensive than others, and instead focus on the correlation of growth rates within each city and average the results over all cities.
Moreover, you can rule out period effects with both approaches (i.e., all counties/cities being subject to the same change in federal legislation in a specific year, etc.).
Getting the right data and knowing how to analyze it can be a bit more challenging in this example, but in the end you will in most cases be able to have an “impact analysis” like we made for the weight loss example. And this will be your most important chart to look at before moving forward and actually solving the housing crisis.
Bottom line of this section: Before you start solving a problem, you need to know what is causing it. Typically, although people think they know the top influences of their problem, a quick but systematic data collection will often surprise them. If you don’t do this, you risk working on the wrong issues and, as a result, you might not make any progress.
3. Design an intervention which tackles the top influences
A goal without a method is nonsense, says W. Edward Deming.
So let’s look at Figure 3 again and come up with a plan to solve our problem. Painfully obvious, I need to cut the snacks.
Of course, there is no rule that says you have to address the top influences of your problem. Especially if influence #7 on your chart is
- the “low-hanging fruit”, i.e. easy to reduce and already sufficient to achieve your goal, or
- important to address for other reasons (e.g. overall health impact).
In my case, it would make little sense to try to lose weight by cutting out, say, sugary drinks. As you can see from Figure 3 in the previous section, a decrease by 30% or so in the category “drinks” would not make any significant impact. I would have to abstain from drinks such as regular coke, energy drinks, juice, or coffee with milk completely in order to see some (small) results. This would be difficult for me since I sometimes have an energy drink or a coke as motivation on a long day of work. Erasing these completely from my menu would be a strong psychological challenge, meaning the likelihood of me sticking to such a plan indefinitely would be low. And even if I did, the effect would be small. Again, of course, if you drink 2 liters of regular coke per day, these considerations will be different for you.
Therefore, a good intervention in general is something that:
- addresses my biggest source of the problem,
- is measurable and specific (not “from now on I vow to eat less”),
- is easy to stick to and requires as little change in my habits as necessary.
As you will probably know, the last point is often the crucial one explaining why people fail to lose weight. So let’s try the following method:
“Limit the daily intake of calories from ‘snacks’ to (roughly) 600 kcal on 90% of days by pre-selecting servings.”
This is still a lot! And you might object that it would be better if I ate “real, whole food 95% of the time” – sure, but how often are sudden and radical changes successful in the long term? With the method described above, I’m not required to completely change my lifestyle abruptly. I can continue with my current habits except for a small corrective action which is not too hard to implement. If I find this program easy to follow, then I can become more ambitious in the future and limit the amount of snacks to an even lower level. However, if I formulate a too ambitious plan from the start, I’m more likely to lack the discipline to stick to it. So I would say the method as formulated above makes sense for me.
I don’t even have to continue writing down calorie numbers into spreadsheets, because you can usually judge how many kcal you’re about to eat if you open a, say, bag of potato chips and the bag says 550 kcal per 100 gram, and it contains 200 grams, then I know I can eat roughly half the bag to stay within my limit. I will thus pour half the bag into a bowl and put the rest back on the shelf in the basement. After I ate everything I allowed myself to eat, I will eat a cucumber and drink a diet coke and look at my (imaginary) oil painting and think of the number the scale will show tomorrow morning if I stay strong now, and apply all other distractions and motivational tricks to keep me from fetching the other half of the bag. On some days I’ll fail (or deliberately not care) and that’s ok because if I stay well within the limit on 90% of days, this will reduce the bar shown in Figure 3 by around 300 kcal. And this will put me on track to losing weight.
Here are some other examples of interventions that might make sense in your case:
- Limit the amount of sugary drinks to 0.5 liters per day on 90% of days.
- Eat at least 1 g of protein per kg of your body weight (i.e. if your weight is 80 kg, eat at least 80 g of protein) on 80% of days.
- Do intermittent fasting (skipping breakfast or dinner) on at least 4 days a week.
- Walk at least 10,000 steps per day on at least 5 days a week.
I hope that by now you anticipate what I’m about to write: Whether or not these methods make sense in your case, and which exact numbers to put in, depends on how your chart of your top influences looks like.
Here are some more examples from other subject areas. I am writing down these lengthy examples hoping that people with different backgrounds will be able to relate to one or the other:
- Your goal is to save money and cut spending. Your data collection and analysis reveals that your top items of expenditures are (1) housing, (2) groceries, and (3) transportation (car, train tickets etc.). Everything else is ranking far behind. This means that while you can surely consider a cheaper mobile phone plan; if you really want to noticeably lower your expenses, you have to tackle one of these. Since you don’t want to move and you have to commute to work, you design a plan to lower your grocery bills. Another Pareto analysis reveals the top influences in the “groceries” category, and from there you identify items you want to cut/limit in the future (e.g., convenience food, cigarettes, branded body care products, etc.).
- You have an assembly line where your company produces, say, dishwashers. You get parts delivered from 200 different suppliers and your colleagues assemble them to dishwashers. At the end of the line, there is a test bench for the finished product where various functions are tested (does the machine switch on; does water flow through the machine without leaking, etc.).
At this end-of-line test, you find a certain percentage of machines to be faulty due to bad supplied parts; e.g., a hose leaking, a pump with insufficient power, a defective electronic component etc. (I have clearly no idea how a dishwasher works).
These faulty machines cause very high costs because you have to disassemble and rework the machine or scrap it. It would be much better if you had found out that the pump was defective right after you received it from the supplier, not after you assembled the whole product.
However, you only have one guy in the receiving department making incoming goods inspections on a 5% sample of deliveries. If you wanted to check every single delivered good, you would have to hire 20 guys. The 5% sample guards you against systematic problems (e.g., if a whole palette of hoses are all the wrong size, you would find this out with the 5% spot check and you could send back the whole palette. However, singular failures – one defect pump here, two broken pipes there – will likely not be detected by your inspections which, by definition, will on average find only 5% of non-systematically defect parts. You also don’t have a very smart IT system; your factory functions on spreadsheets and CAD drawings.
So what can you do in this situation to lower the defect rate of assembled products? You first make a Pareto analysis, because likely the 20/80 rule will hold and 20% of suppliers/parts cause 80% of your problems. Identifying the top issues, you define actions: e.g., audits or talks with the suppliers that cause the most problems, or an increased check rate (e.g. 20% instead of 5% or even 100% for the biggest problems) vis-à-vis a much lower rate (1% or even 0%) for those parts/suppliers that don’t cause any problems in the goods receiving area. This measure alone, without any additional costs, would result in you being able to prevent at least 4x more defects before assembly.
Maybe you’re saying “duh, we have been doing this in a much more sophisticated way for 30 years”, then good for you, but in my experience, many (especially smaller) companies are not doing this systematic sort of analysis.
Summary: whatever method to lose weight (or save money, gain muscles, etc.) you are implementing, it needs to a) be individually tailored to your biggest drivers of the problem (which you identified in the previous section), b) measurable and specific (see next section), and c) practicable enough so that you are likely to stick to it.
Interim conclusion: Many people struggle with losing weight because they implement some diet or program that isn’t actually addressing their individual top problems, or isn’t specific and measurable (causing them to lose sight of their goal), or it’s that 23:1 stone age warrior diet which they abandon after a week because it is not at all compatible with their everyday lifestyle.
4. Start your method and measure your progress
Quick reminder: When you previously set your goal in section 1, you already implicitly defined a key performance indicator (KPI). Formulating a specific and measurable goal implies that you can judge your success by looking at some number(s). Ideally, there is one overarching KPI that tells you: I have reached the goal, or I’m on my way and have already achieved 50% of my goal, or I’m still at 0%, etc. We already discussed in the beginning that sometimes this is difficult because you have multiple goals which are partly in conflict which each other. For the sake of simplicity, let’s continue to move on with the “5 kg weight loss in 100 days” goal. Here, our KPI is simply “bodyweight in kg”, which we could refine to something such as “weekly average kg on the scale in the morning”.
Examples of other KPI’s which are simple to define and measure:
- Percentage faulty machines at end-of-line tests (you want it to decrease to X%).
- Monthly household spending in € (you want it to go below X€).
- Power consumption in kWh per month (you want it to decrease below X).
- Mean absolute error of your machine-learning prediction model (you want it to reduce to half compared with the previous model).
- Number of lbs/kg on the bench press (you want to be able to press X kg for 3×8 reps).
In other cases, as discussed above, it might be a bit more complicated (e.g. you want to improve your overall health, or your physical attractiveness), but you still have to translate your goal into a measurable KPI.
Now that we also have a method for how we want to achieve the goal, we start the plan and also the data collection. Here comes the important part: You need to collect data both on your KPI (the outcome, i.e. my weight) as well as on how well you stick to the plan. Remember that in our example, the plan was to stay below 600 kcal from snacks on 90% of days.
A very simple data collection could look like this:


Fig. 5: Simple way of collecting data on method and outcome
This way of collecting data is very crude, but it has the advantage that it is easy and motivating at the same time (it is rewarding after a day of self-discipline to enter a “YES” into the spreadsheet, and to see the numbers slowly go down).
If you have a more complicated method, you might want to collect more and other types of data, e.g. in the form of an exercise protocol. In our case the simple binary collection of YES and NO’s is not only easy to execute but also allows simple but powerful ways of analyzing the data statistically, which we will do in the following section.
5. Intermediate review: are you on track to success?
Let’s say 30 days after the start of your plan you make the first review to see whether you’re on track or not. Assuming you have collected data as in Figure 5, and saved it as an xlsx-file, you can run the following in R (after adjusting the path to your saved file and installing the tidyverse package, if necessary).
library(tidyverse)
d <- readxl::read_excel("C:/Users/Z/Desktop/MyDataCollection.xlsx")
names(d) <- c("Day", "Stuck_to_plan", "Weight")
target <- 83.5
ggplot(d, aes(x = Day, y = Weight)) +
geom_segment(aes(x=Day, xend = Day, y = 90, yend = 80, color = Stuck_to_plan, alpha=0.3), size=8.1,
show.legend = F)+
scale_color_manual(values = c("#ffad99", "#ccffcc")) +
geom_line() +
theme_minimal() + ylim(c(80,90)) +
geom_abline(slope = 0, intercept = target, color="darkblue") +
geom_label(aes(x=max(d$Day), y = target), label = "Target", color="darkblue") +
ggtitle("Daily weight in kg (vs. target)",
subtitle = "Days marked in green = diet plan fulfilled, red = not fulfilled")
If you run this code on your data, there might be a few things you need to tweak: First, on two occasions I limited the y axis to 80 and 90 kilos (replace the 80’s and 90’s with values that fit for your desired range). You can also see that I set a “target” value at 83.5 which you can change according to your target value. Finally, there is the “size = 8.1” argument in the geom_segment() call, you might need to play around with this value in order to get a smooth background. [If you know of a better way to do this, please let me know in the comments!]
If you collect the data and run the code, there are three different possible scenarios that you might encounter:
Scenario 1: You’re not sticking to the plan


Fig. 6: Review of first 30 days (scenario 1)
The graph shows my daily weight over time as the black solid line, and I can also see how far away I am from my target. In the background, I have colored days where I stuck to the plan in green and I marked red those days where I couldn’t control my snack appetite. In this (hypothetical) scenario 1, we can clearly see that there are way too many “red” days and, unsurprisingly, we did not really make much progress in our first 30 days.
If you encounter this situation you have to reflect why you are not able to stick to the plan. Is it too ambitious? Does it collide with your other day-to-day routines? You need to change something now, otherwise you can’t be surprised that your goal won’t be reached after the full 100 days. You need to change the plan or change the way you enforce it.
Scenario 2: You stick to the plan – but it does not work


Fig. 7: Review of the first 30 days (scenario 2)
Look at all this green! You have shown great self-discipline in these 30 days. Alas, it has had no effect on your weight so far. Looking at the black line, there is no clear downward trend over time.
By the way, you can verify this with statistical tests. One method would be to run a regression and look at the slope coefficient the following way:
lm(Weight ~ Day, d) %>% summary


Fig. 8: Result of regression analysis of weight over time (scenario 2)
What we are doing with this analysis is to look at whether “Weight” changes significantly as the days progress. The model tests a linear relationship: The higher the date, the lower the weight? As you can see from the p-value on the bottom right, the model is overall not statistically significant, there is no evidence that we lose (or gain) weight over time beyond the random fluctuations that you always have when measuring your weight daily. To understand what statistical significance means, there is a tutorial here.
We will get back to the regression in a moment. Let’s first look at a second approach of testing statistically whether you have lost weight or not. You might object to the regression above that weight loss is perhaps not linear and that the effect of you sticking to the diet only kicks in after some time. So let’s make a different test: Is our weight during the last week statistically any different compared with our weight during the first week? Here is simple code to run this test:
d %>% mutate(Phase = c(rep("FirstWeek", 7), rep(NA, nrow(d) - 14), rep("LastWeek",7))) %>%
t.test(Weight ~ Phase, .)


Fig. 9: Result of t-test (scenario 2)
A t-test is a very simple, yet powerful test. We compare the mean values of two groups – here: weight measurements in week 1 vs. weight measurements in the last week, and run a formal significance test. The output tells us that there was a tiny reduction from 88.4 kg in week 1 to 88.1 kg in week 4, but this reduction is not statistically significant (p-value greater than 0.05). So the lower value could well be due to random fluctuations and might not reflect a real trend. Statistically significant or not, losing 0.36 kg in 4 weeks is clearly not enough to get to our goal.
What is the difference between the regression and the t-test again? In the regression, we test a strictly linear relationship: Per day, how many kg do we lose on average. Our t-test is cruder as it reduces the information to two groups, and also discards a lot of measurements (weeks 2 and 3), but it might reveal an effect which only “kicks in” after a certain period of time. Note that the same can be achieved by adding the dummy variables we created in the code above (“Phase”) to the regression model.
So what do we do now? We see that although we are sticking to the plan, it does not work as intended. Now we need to find out why: Am I (unconsciously) compensating the snack limit by, e.g., having more for dinner? Or is my data collection biased; e.g. am I systematically underestimating my calorie intake? It can be frustrating to see a result as in this scenario 2, and it might require us to collect more data to see why our plan is failing; e.g., by creating in a food diary once again over a certain amount of time. Bottom line: if it’s not working, we need to change the plan. Go back to step 3.
Let’s hope however that we get a result like the one shown in scenario 3.
Scenario 3: We are sticking to the plan and it works

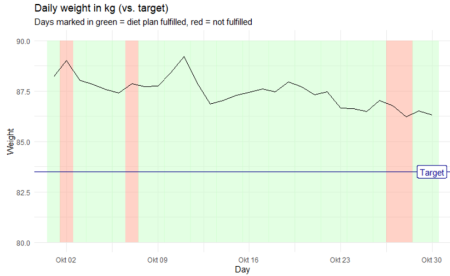
Fig. 10: Review of the first 30 days (scenario 3)
This is the scenario we’re hoping to see. The chart shows as that we are both a) sticking to the plan, and b) making visible progress. In only 4 out of 30 days did we not stick to our diet method (red bars on graph background), which is acceptable. And we can also clearly see a downward trend in our weight curve. Let’s verify this with the two tests introduced above:
lm(Weight ~ Day, d) %>% summary


Fig. 11: Result of regression analysis of weight over time (scenario 3)
The regression tells us that per day, we lost 62 grams on average, which is statistically significant. This translates to a weekly weight loss of roughly 0.43 kg. Which means that over the course of 90 days (or 12-13 weeks), our forecast would be that we’ll lose ca. 5.5 kg, i.e. we’d be reaching our goal if we continued like this. (If you’re wondering, the “intercept” is the model’s prediction what your weight was in kg in the year 0 AD, i.e. not really meaningful).
For comparison, let’s do a t-test again comparing our weight in week 1 vs. week 4:
d %>% mutate(Phase = c(rep("FirstWeek", 7), rep(NA, nrow(d) - 14), rep("LastWeek",7))) %>%
t.test(Weight ~ Phase, .)


Fig. 11: Result of t-test (scenario 3)
We started at 88 kg. By week 4, our weekly average was down to 86.5. This difference is statistically significant (p < .001), thus confirming that we’re not looking at random fluctuations on the scale.
We can thus confirm that we’re on the right path, and we keep doing what we’re doing for the rest of the study period.
6. Final review and celebration
When the 90 days are over, we conduct a final review and statistical test whether we have reached our goal or not.
Assuming you have continued to collect data in a spreadsheet like this:
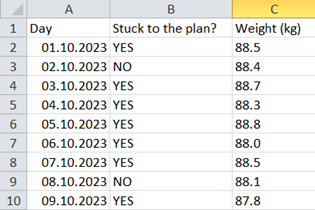
Fig. 12: Simple way of collecting data on method and outcome (duplicate from Fig. 5)
If you haven’t collected any real data, you can replicate the following graphs with this simulated data:
set.seed(2023)
d <- data.frame("Day" = seq.Date(from = as.Date("2023-10-01"), to = as.Date("2023-12-29"), by = "day"),
"Stuck to the plan?" = c("YES", "NO", sample(c(rep("YES",9), "NO"), 88, T)),
"Weight (kg)" = 88.5 + 0:89*(-0.07) + rnorm(90,0,.5))
For our review, we start with the same graph as in the intermediate review in the previous section:
d <- readxl::read_excel("C:/Users/Z/Desktop/MyDataCollection.xlsx")
target <- 83.5
names(d) <- c("Day", "Stuck_to_plan", "Weight")
ggplot(d, aes(x = Day, y = Weight)) +
geom_segment(aes(x=Day, xend = Day, y = 90, yend = 80, color = Stuck_to_plan, alpha=0.3), size=8.1,
show.legend = F)+
scale_color_manual(values = c("#ffad99", "#ccffcc")) +
geom_line() +
theme_minimal() + ylim(c(80,90)) +
geom_abline(slope = 0, intercept = target, color="darkblue") +
geom_label(aes(x=max(d$Day), y = target), label = "Target", color="darkblue") +
ggtitle("Daily weight in kg (vs. target)",
subtitle = "Days marked in green = diet plan fulfilled, red = not fulfilled")
Again, you need to adapt the path and filename of your spreadsheet in the first line of the code chunk above. If you do not have real data, skip the first line to produce the following graph with the simulated data from the previous code chunk.


Fig. 13: Final review – Line chart of daily weight vs. target
This is the desired outcome. If you have followed the steps so far, and the intermediate review (step 5) was also successful, you’re likely to get a result like in Figure 13. The chart nicely shows our continuous progress, and that we’ve reached our target value throughout the last couple of days. This is the type of graph I could look at for hours. What better gratification could there be for having implemented a functioning plan, and seeing the results? Note: I’m producing these sorts of graphs for myself to look at and never shared them with anybody because I don’t think it’s anyone’s business; but if you like sharing stuff on social media, an accomplishment like this would of course be something that might inspire others and might be worth sharing.
Thinking back to step 1 of this guide, we now see why it was important to formulate our goal in a specific, measurable, and timely way. We can now clearly answer the question whether we have reached our goal: Yes! (hopefully in your case as well). If not, we can at least say what percentage of our goal we reached. And we can, as we did in step 5, find out why we failed and use this information to develop a better method and change course.
You can use the code from section 5 and run the regression and t-tests again; although it should be quite obvious here from the chart that our weight loss is statistically significant.
So instead let’s make a final summary graph and including the information of statistical significance there:
weight_loss_goal <- 5
test <- d %>% mutate(Phase = c(rep("FirstWeek", 7), rep(NA, nrow(d) - 14), rep("LastWeek",7))) %>%
t.test(Weight ~ Phase, .)
test_data <- data.frame("Week" = c("First week", "Last week"),
"Weekly_average_weight" = unname(test$estimate))
significance_text <- ifelse(test$p.value < 0.05 & test$p.value >= 0.01, "significant at p < 0.05",
ifelse(test$p.value < 0.01 & test$p.value >= 0.001, "significant at p < 0.01",
ifelse(test$p.value < 0.001, "significant at p < 0.001", "not statistically significant")))
goal_achievement <- (test$estimate[[1]] - test$estimate[[2]]) / weight_loss_goal * 100
ggplot(test_data, aes(x=Week, y = Weekly_average_weight, label = sprintf(Weekly_average_weight, fmt="%.1f"))) +
geom_col(fill="Steelblue2", alpha=.7) + geom_label() +
theme_minimal() + xlab("") + ylab("") +
geom_label(aes(x=1.5,y = min(Weekly_average_weight)/2),
label = paste0("Goal achievement:\n", round(goal_achievement,0), "%"),
color=ifelse(goal_achievement>=100, "seagreen3", "red"), size=6) +
ggtitle(paste0("Weight loss over the course of ", nrow(d), " days"),
subtitle=paste0("Weekly average body weight. Goal: ", weight_loss_goal, " kg reduction. \nActual weight loss is statistically ", significance_text))
In this code chunk, the first line specifies how much weight loss you wanted to achieve. This information is then used to calculate what % of your goal you have achieved, from using the weekly average of week 1 vs. the last week as the reference. We’re also extracting the statistical significance value from the t-test in order to display the information in the graph.
This is the output from the code chunk above (it works with the simulated data as well):


Fig. 14: Final review: Comparison of first vs. last week’s average
As you can see, we have not only added the goal achievement as a percentage to the graph (it will show in red if it’s below 100%). But we have also included the information that our weight loss is statistically significant (which is not very surprising given these numbers). As you can see from the code, if the p-value were larger than 0.05, the subtitle would say the difference is “not significant”.
With these results, we can now deservedly celebrate. And finally get back to eating as many snacks as we want on a daily basis. Just kidding, of course. Instead we’re going back to step 1: What’s our next goal? Why aren’t we currently reaching that goal? What’s our method to reach the goal? Perhaps we want to lose even more weight, or we’re happy with the current state and want to anchor it? Good luck on your journey of continuous improvement!
Summary / tldr
Step 1: Set a measurable, timely goal – not like those new year’s resolutions such as “go to the gym more often” which you will forget by March and you never review whether you have actually reached the goal or not.
Step 2: Determine the top influences on why you’re currently not achieving the goal – you often have a gut feeling what causes you’re problem, but a quick and systematic data analysis will likely surprise you.
Step 3: Design a method to combat the top influence of your problem – something that is easy for you to implement, and which tackles the 80% of your problem, not the 20%.
Step 4: Implement the method and collect data – both on how well you’re sticking to the plan as well as on the outcome.
Step 5: Intermediate review: Are you on track? Are you sticking to the plan? Adjust if necessary.
Step 6: Profit
If anyone is still with me at this point: Thank you for reading and I hope that some of you will find this helpful in order to solve their problems, whether personal, work-related, or political. Let me know if you have any questions, anything to add, or criticism. Thanks!
1I’m not claiming to have invented something brand new here. Most of the ideas in this guide have already been formulated in a similar way in decades-old frameworks such as “8D” (8 disciplines of problem solving). It’s just a mixture of “systematic thinking” aided by very simple statistics. However, the way I have structured these ideas here, together with the examples and statistical analyses, has helped me to better understand the problems and their solutions I was facing in the past, so I hope that for some of you this presentation is more helpful than the existing literature and guides as well.
2Admittedly, this guide won’t solve connecting general relativity to quantum mechanics, nor finding the meaning of life, nor stopping hereditary hair loss. But any kind of problem that you can plausibly solve with your own actions can be tackled with the method described here.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.