

Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
I am always struggled to model the changes in gasoline prices as a categorical variable, especially in a small amount of time-series data. The answer to improving the performance of modeling such a dataset can be to combine more than one model. This method of combining and aggregating the predictions of multiple models is called meta-learning, which is based on the algorithm that combines weaker models to form a stronger one, which is known as an ensemble.
One of the first ensemble algorithms we’re going to use is bagging(bootstrap aggregating). The bagging produces many training datasets by bootstrapping the original training data. These datasets are used to form a bunch of models, which has a single algorithm usually preferred random forest; because they are unstable learners, which means small changes in the input cause significantly different predictions results.
The other ensemble algorithm we will use is, boosting. Unlike bagging, this method improves the performance of the model by adding better models to it, which means it forms the complementary learning algorithms. Besides that, the boosting gives learning algorithms more weight based on their past performance, which means a model that performs better has greater influence over the ensembles.
After the explanations of the algorithms we will use, we can build our dataset for the models. The dataset consists of the gasoline prices as Turkish Lira, Brent spot prices in US dollars, USD-TRY exchange rate between 2019 and 2022.
We will do some wrangling to adjust the dataset for our purpose. We create a three-level factor for the changes in gasoline prices, which are going to be our target variable. Also, we will add timestamps to construct regular time series data. In order to do that, we can use tsibble package.
library(tidyverse)
library(tsibble)
library(readxl)
df <- read_excel("gasoline.xlsx")
#Building the dataset
df_tidy <-
df %>%
mutate(
gasoline = case_when(
gasoline - lag(gasoline) < 0 ~ "down",
gasoline - lag(gasoline) > 0 ~ "up",
TRUE ~ "steady"
) %>% as.factor(),
xe_lag = lag(xe),
brent_lag = lag(brent),
date=as.Date(date)
) %>%
as_tsibble() %>%
fill_gaps() %>% #makes regular time series by filling the time gaps
#fills in NAs with previous values
fill(-date,.direction = "down") %>%
na.omit() %>%
as.data.frame()
Before the modeling, we will look at the ratio of the factor levels in the target variable, which leads us to know the NIR level for specifying significant accuracy results. We will build that with treemap function.
#Treemap of factors
library(treemap)
df_tidy %>%
count(gasoline) %>%
mutate(label=paste(gasoline,scales::percent(n/sum(n)),sep = "\n")) %>%
treemap(
index="label",
vSize="n",
type="index",
title="",
palette="Accent",
border.col=c("black"),
border.lwds=1,
color.labels="white",
face.labels=1,
inflate.labels=F
)


We can understand from the above diagram; any model we create must have a more accuracy rate than %65.7 to be significant. The Kappa statistic is an effective accuracy measurement in terms of this no information rate(%65.7) we’ve just mentioned.


- We will use unweighted kappa as the measurement value. Because there is no correlation among the factors levels of the target variable(varying degrees of agreement).

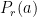

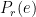


Now, we can build our models and compare the kappa results for different seed values on a plotly plot.
library(adabag)#Boosting
library(ipred)#Bagging
library(caret)#Bagging control object
library(vcd)#Kappa
library(plotly)#interactive plot
#Bagging
ctrl <- trainControl(method = "cv", number = 10)
kappa_bagg <-
lapply(
1:20,
function(x){
set.seed(x)
train(gasoline ~ .,
data = df_tidy,
method = "treebag",
trControl = ctrl)$results[["Kappa"]]}
) %>%
unlist()
#Boosting
kappa_boost <-
lapply(
1:20,
function(x){
set.seed(x)
boosting.cv(gasoline ~ ., data = df_tidy) %>%
.$confusion %>%
Kappa() %>%
.$Unweighted %>%
.[[1]]}
) %>%
unlist()
#Kappa simulation on a plotly chart
kappa_plot <-
data.frame(
seed=rep(1:20, 2),
kappa= c(kappa_bagg, kappa_boost),
ensembles=c(rep("Bagging", 20), rep("Boosting", 20))
) %>%
ggplot(aes(x=seed, y=kappa, color=ensembles))+
geom_point(size=3)+
geom_line(size=1)+
theme_minimal()+
theme(panel.background = element_rect(fill = "midnightblue", color = NA),
panel.grid.minor.y = element_blank(),
panel.grid.minor.x = element_blank())
ggplotly(kappa_plot) %>%
layout(legend=list(orientation="v", y=0.5))


As can be seen above, boosting algorithm seems to be slightly better than boosting but generally, both algorithms also have very high accuracy results.
References
- Lantz, Brett (2015) Evaluating Model Performance. Machine Learning with R. 323-326
- Lantz, Brett (2015) Improving Model Performance. Machine Learning with R. 362-369
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.