
Latent Gaussian Models and INLA
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
If you read my post about Fast Bayesian Inference with INLA you might wonder which models are included within the class of latent Gaussian models (LGM), and can therefore be fitted with INLA. Next I will give a general definition about LGM and later I will describe three completely different examples that belong to this class. The first example will be a mixed effects model, the second will be useful in a time series context while the third will incorporate spatial dependence. All these examples, among others, can be found on the examples and tutorials page in the INLA website.
Latent Gaussian Models
Generally speaking, the class of LGM can be represented by a hierarchical structure containing three stages. The first stage is formed by the conditionally independent likelihood function
,
where ^T}")
^T}")
^T}")
}")

The second stage is formed by the latent Gaussian field, where we attribute a Gaussian distribution with mean }")
}")


.
Finally, the third stage is formed by the prior distribution assigned to the hyperparameters,
.
That is the general definition and if you can fit your model into this hierarchical structure you can say it is a LGM. Sometimes it is not easy to identify that a particular model can be written in the above hierarchical form. In some cases, you can even rewrite your model so that it can then fit into this class. Some examples can better illustrate the importance and generality of LGM.
Mixed-effects model
The description of the EPIL example can be found on the OpenBUGS example manual. It is an example of repeated measures of Poisson counts. The mixed model is given by
- First stage: We have
individuals, each with 4 successive seizure counts. We assume the counts follow a conditionally independent Poisson likelihood function.
,\ i=1,...,59;\ j = 1, ..., 4")
- Second stage: We account for linear effects on some covariates
for each individual, as well as random effects on the individual level,
, and on the observation level,
.
So, in this case
. A Gaussian prior was assigned for each element of the latent field, so that
is Gaussian distributed.
- Third stage:
, where
![\displaystyle \begin{array}{rcl} \eta_{ij} & = & \log(\lambda_{ij}) = k_i^T\beta + a_i + b_{ij} \\ a_i & \sim & N(0, \tau_a^{-1}),\ b_{ij} \sim N(0, \tau_b^{-1}) \\ \beta & = & [\beta_0, \beta_1, \beta_2, \beta_3, \beta_4]^T,\ \beta_i \sim N(0, \tau_{\beta}^{-1}),\ \tau_{\beta}\text{ known} \\ \end{array}](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+%5Ceta_%7Bij%7D+%26+%3D+%26+%5Clog%28%5Clambda_%7Bij%7D%29+%3D+k_i%5ET%5Cbeta+%2B+a_i+%2B+b_%7Bij%7D+%5C%5C+a_i+%26+%5Csim+%26+N%280%2C+%5Ctau_a%5E%7B-1%7D%29%2C%5C+b_%7Bij%7D+%5Csim+N%280%2C+%5Ctau_b%5E%7B-1%7D%29+%5C%5C+%5Cbeta+%26+%3D+%26+%5B%5Cbeta_0%2C+%5Cbeta_1%2C+%5Cbeta_2%2C+%5Cbeta_3%2C+%5Cbeta_4%5D%5ET%2C%5C+%5Cbeta_i+%5Csim+N%280%2C+%5Ctau_%7B%5Cbeta%7D%5E%7B-1%7D%29%2C%5C+%5Ctau_%7B%5Cbeta%7D%5Ctext%7B+known%7D+%5C%5C+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0 "\displaystyle \begin{array}{rcl} \eta_{ij} & = & \log(\lambda_{ij}) = k_i^T\beta + a_i + b_{ij} \\ a_i & \sim & N(0, \tau_a^{-1}),\ b_{ij} \sim N(0, \tau_b^{-1}) \\ \beta & = & [\beta_0, \beta_1, \beta_2, \beta_3, \beta_4]^T,\ \beta_i \sim N(0, \tau_{\beta}^{-1}),\ \tau_{\beta}\text{ known} \\ \end{array}")
,\ \tau_b \sim \text{gamma}(d_1, d_2)")
Here you can find the data and INLA code to fit this model.
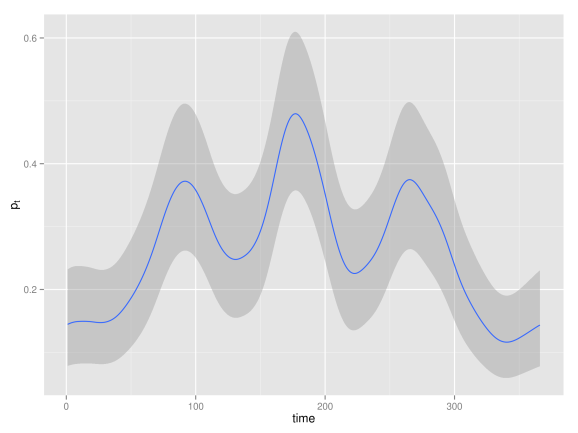
Smoothing time series of binomial data
The number of occurrences of rainfall over 1 mm in the Tokyo area for each calendar year during two years (1983-84) are registered. It is of interest to estimate the underlying probability 




- First stage: A conditionally independent binomial likelihood function
with logit link function
- Second stage: We assume that
, where
follows a circular random walk 2 (RW2) model with precision
. The RW2 model is defined by
The fact that we use a circular model here means that in this case,
is a neighbor of
, since it makes sense to assume that the last day of the year has a similar effect when compared with the first day. So, in this case
and again
- Third stage:
, where
,\ t = 1, ..., 366")
}{1 + \exp(\eta_t)}")
.")
")
Here you can find the data and INLA code to fit this model, and below is the posterior mean of 
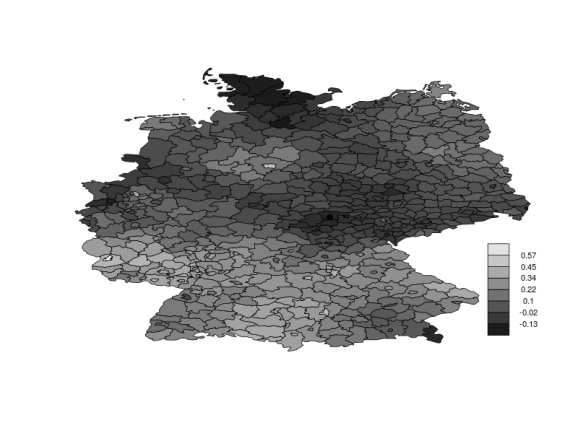
Disease mapping in Germany
Larynx cancer mortality counts are observed in the 544 district of Germany from 1986 to 1990. Together with the counts, for each district, the level of smoking consumption c is registered. The model is given by
- First stage: We assume the data to be conditionally independent Poisson random variables with mean
, where
is fixed and accounts for demographic variation, and
is the log-relative risk.
- Second stage: The linear predictor
, an smooth function of the smoking consumption covariate
, an spatial model over different district locations
, and an unstructured random effect
to account for overdispersion. So that
and the detailed description of each of the above model components can be found here. But again (surprise surprise)
- Third stage:
),\ i = 1, ..., 544")
 + f(c_i) + u_i")
Here you can find the data and INLA code to fit this model, and below is the posterior mean of the spatial effect in each of the 544 districts in Germany.
Further reading:
– Examples and tutorials page in the INLA website.
– Slides of a Bayesian computation with INLA short-course I gave in the AS2013 conference in Ribno, Slovenia.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.