
Calculate Fantasy Players’ Risk Levels using R
[This article was first published on Fantasy Football Analytics in R, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
In prior posts, I have demonstrated how to download, calculate, and compare fantasy football projections from ESPN, CBS, and NFL.com. In this post, I will demonstrate how to calculate fantasy football players’ risk levels. Just like when determining the optimal financial portfolio, risk is important to consider when determining the optimal fantasy football team. Each player has a projected value (our best guess as to his projected points). We can think of the player’s mean or central tendency of various projections as his “value.” Nevertheless, the player’s mean projected points across various sources (e.g., ESPN, Yahoo) does not tell the whole story.Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
The R Script
The R Script for the “Understanding Risk” section is at:
The R Script for the “Calculating Risk” section is at:
Understanding Risk
Consider 3 players: Player A, Player B, and Player C. Each of the 3 players has the same number of projected points (150 points). The various sources of projections differ, however, in how consistent their projections are for the players. We will define consistency formally in terms of the dispersion of the projections for a given player in standard deviation units. The standard deviation tells us about the uncertainty of a player’s projections around his central tendency, with larger values representing more uncertainty. Sources were fairly consistent in projecting Player A, with a standard deviation of 5. Sources were less consistent in projecting Player B, with a standard deviation of 15. Sources were even more uncertain about Player C, with a standard deviation of 30.This example is depicted below:
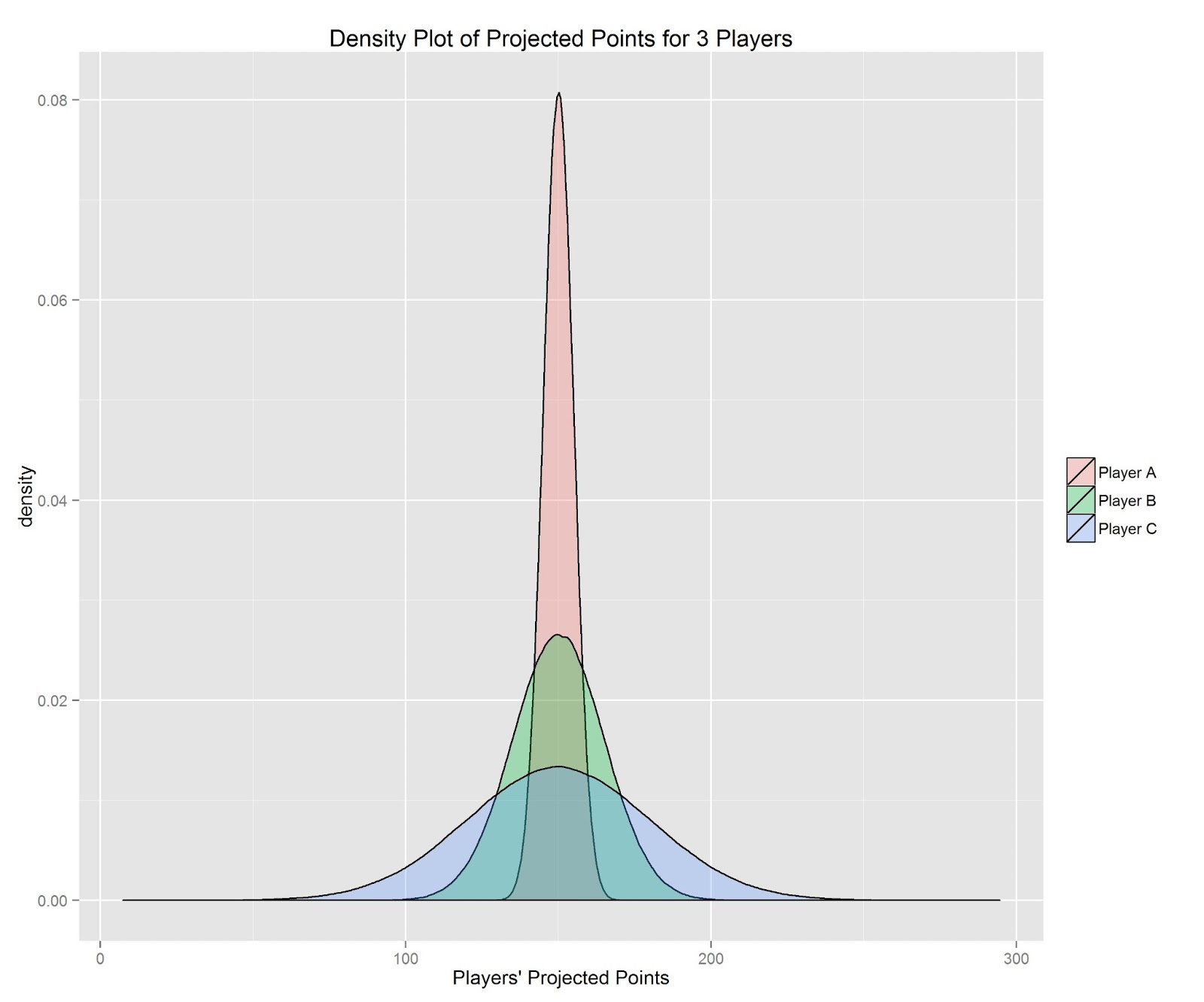
Each player has the same number of projected points, but each differs in the uncertainty around that estimate. We can consider the density plot (or the 95% confidence interval) as the range of plausible values for a player. So which player is best? The answer depends on whether you intend to draft the player as a starter or a bench player. If your intent is to draft a starter, your goal is to maximize value while minimizing risk. In other words, Player A would be the best (i.e., safest) starter. He may not score as many points as Players B or C, but you can be fairly confident that he will produce near his projected estimate. On the other hand, if you’ve already filled your starting lineup with players that maximize their value while minimizing their risk, the bench players serve a different role—the role of sleeper. Bench players do not score points, so it does no good to get a player with a low value and a low risk as a bench player. With bench players, it makes sense to take on more risk in the hopes that they will outperform your starters. Thus, if drafting a bench player, Player C would be best (i.e., gives you the highest potential ceiling).
Calculating Risk
We can calculate two forms of risk: 1) variation in projections and 2) variation in rankings. In the example above, we calculated variations in projections by calculating the standard deviation of sources of player projections. We can also calculation variation in rankings by calculating the standard deviation of sources of player rankings.To calculate the variation in projections, we calculate the standard deviation of the players’ projections from ESPN, CBS, and NFL.com:
for (i in 1:dim(projections)[1]){
projections$sdPts[i] <- sd(projections[i,c("projectedPts_espn","projectedPts_cbs","projectedPts_nfl")], na.rm=TRUE)
}To calculate the variation in rankings, we calculate the standard deviation of the players' rankings from experts and from "wisdom of the crowd." We can get the consensus rankings from various so-called experts from FantasyPros.com, which averages rankings across various sources:
experts <- readHTMLTable("http://www.fantasypros.com/nfl/rankings/consensus-cheatsheets.php", stringsAsFactors = FALSE)$data
experts$sdPick_experts <- as.numeric(experts[,"Std Dev"])For an example of calculating variations in rankings from wisdom of the crowd, see here. We can get crowd estimates of rankings by using public mock draft information from FantasyFootballCalculator.com:
drafts <- readHTMLTable("http://fantasyfootballcalculator.com/adp.php?teams=10", stringsAsFactors = FALSE)$`NULL`
drafts$sdPick_crowd <- as.numeric(drafts$Std.Dev)Then, we can average together the variation in rankings from the experts and the crowd. After calculating the combined variations in rankings, we can standardize the variation in projections and the combined variations in rankings with a z-score. Standardizing both risk indices puts them on the same metric (mean = 0, standard deviation = 1), so that they can be averaged into a combined risk index. The risk indices were then rescaled to have a mean of 5 and a standard deviation of 2.
The 6 players with the highest risk on our combined risk index are the following (risk in parentheses):
Jake Locker (10.6)
Russell Wilson (12.4)
Kevin Smith (10.9)
John Skelton (9.9)
Matt Flynn (16.0)
Joe McKnight (10.3)
Note that these are not the highest risk players for next year because the projections came from last year (the projections for next year are not currently available). I will update my risk calculations when they become available.
Here is a density plot of the risk indices of all players:

In Conclusion
In conclusion, it is important to consider risk in addition to projected points scored. Risk is not intrinsically good or bad. In general, we should take less risk when drafting starters, but more risk when drafting bench players. In a future post, I will demonstrate how to use players' values and risk levels to optimize your fantasy lineup.To leave a comment for the author, please follow the link and comment on their blog: Fantasy Football Analytics in R.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.