
Are you leaking h2o? Call plumber!
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.

Create a predictive model with the h2o package.
H2o is a fantastic open source machine learning platform with many different algorithms. There is Graphical user interface, a Python interface and an R interface. Suppose you want to create a predictive model, and you are lazy then just run automl.
Lets say, we have both train and test data sets, and the first column is the target and the columns 2 until 50 are input features. Then we can use the following code in R
out = h2o.automl( x = 2:50, y = 1, training_frame = TrainData, validation_frame = TestData, max_runtime_secs = 1800 )
According the help documentation: The current version of automl trains and cross-validates a Random Forest, an Extremely-Randomized Forest, a random grid of Gradient Boosting Machines (GBMs), a random grid of Deep Neural Nets, and then trains a Stacked Ensemble using all of the models.
After a time period that you can set, automl will terminate and has literally tried hundreds of models. You can get the top models, ranked by a certain performance metric. If you go for the champion just use:
championModel = out@leaderchampionModel
Now the championModel object can be used to score / predict new data with the simple call:
predict(championModel, newdata)
The champion model now lives on my laptop, it’s hard if not impossible to use this model in production. Someone or some process that wants a model score should not depend on you and your laptop!
Instead, the model should be available on a server where model prediction requests can be handled 24/7. This is where plumber comes in handy. First save the champion model to disk so that we can use it later.
h2o.saveModel(championModel, path = "myChampionmodel")
The plumber package, bring your model in production.
In a very simple and concise way, the plumber package allows users to expose existing R code as an API service available to others on the web or intranet. Now suppose you have a saved h2o model with three input features, how can we create an API from it? You decorate your R scoring code with special comments, as shown in the example code below.
# This is a Plumber API. In RStudio 1.2 or newer you can run the API by
# clicking the 'Run API' button above.
library(plumber)library(h2o)
h2o.init()
mymodel = h2o.loadModel("mySavedModel")
#* @apiTitle My model API engine
#### expose my model #################################
#* Return the prediction given three input features
#* @param input1 description for inp1
#* @param input2 description for inp2
#* @param input3 description for inp3
#* @post /mypredictivemodel
function( input1, input2, input3){
scoredata = as.h2o(
data.frame(input1, input2, input3 )
)
as.data.frame(predict(mymodel, scoredata))
}
To create and start the API service, you have to put the above code in a file and call the following code in R.
rapi <- plumber::plumb("plumber.R") # Where 'plumber.R' is the location of the code file shown above
rapi$run(port=8000)
The output you see looks like:
Starting server to listen on port 8000 Running the swagger UI at http://127.0.0.1:8000/__swagger__/
And if you go to the swagger UI you can test the API in a web interface where you can enter values for the three input parameters.
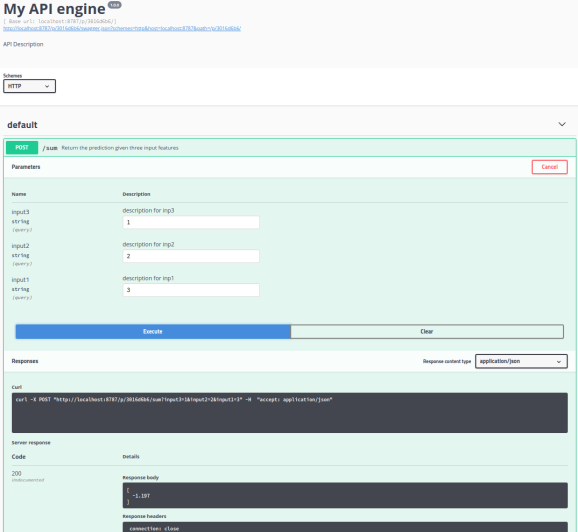
What about Performance?
At first glance I thought there might be quit some overhead, calling the h2o library, loading the h2o predictive model and then using the h2o predict function to calculate a prediction given the input features.
But I think it is workable. I installed R, h2o and plumber on a small n1-standard-2 Linux server on the Google Cloud Platform. One API call via plumber to calculate a prediction with a h2o random forest model with 100 trees took around 0.3 seconds to finish.
There is much more that plumber has to offer, see the full documentation.
Cheers, Longhow.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.