
Analyse des tweets du débat d’entre-deux-tours
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Emmanuel Macron et Marine Le Pen se sont affrontés lors du débat de l’entre-deux-tours mercredi dernier. Ce débat télévisé suivi par près de 16 millions de téléspectateurs a été l’occasion pour moi de tester le package « TwitteR » qui permet de récupérer les tweets.
Je me suis concentré sur les tweets publiés pendant le débat de 21h à 23h30 et mentionnant l’un ou l’autre des comptes officiels twitter des candidats (@EmmanuelMacron pour Emmanuel Macron et @MLP_officiel).
1. Petit tutoriel pour récupérer les tweets avec TwitteR
Le package TwitteR de R permet de récupérer les tweets et de les mettre sous forme de table de données (data frame). Cette forme est particulièrement utile pour réaliser des analyses de ces données comme par exemple les analyses de sentiments à partir des tweets.
Il est très facile de récupérer des tweets en utilisant l’API de Twitter. Je présente ici les étapes que j’ai suivies.
1 – Pour ceux qui n’en possèdent pas, il faut dans un premier temps créer un compte twitter ici.
2 – La deuxième étape consiste à s’enregistrer sur la partie développeurs « Twitter Apps » avec l’identifiant et le mot de passe du compte nouvellement créé.
3 – Une fois enregistré sur la partie Apps, il faut créer une « application » et remplir les champs suivants : name, description, website et callback URL. Le nom, la description et le site internet n’ont pas réellement d’importance. Si vous n’avez pas de site internet, vous pouvez juste entrer le nom de ce blog : http://dataworld.blog Pour le CallBack URL, écrivez sans les guillemets http://127.0.0.1:1410. Acceptez l’accord de licence puis cliquez sur créer l’application.
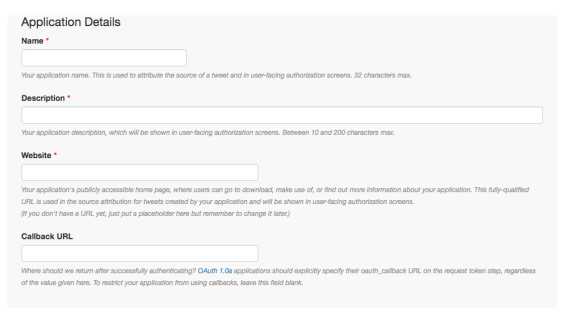
4 – En vous connectant sur la partie Apps vous pourrez accéder à votre nouvelle « application ». Dans l’onglet « Keys and Access Tokens », vous aurez accès à votre Consumer Key, Consumer Secret et également un peu plus bas sur la même page l’Access Token et l’Access Token Secret.
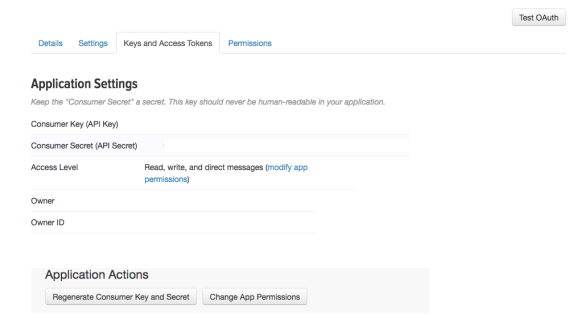
5 – Dans RStudio, lancez les quelques lignes suivantes :
# Installer et lancer le package TwitteR
install.packages("twitteR")
library(twitteR)
# Connexion avec setup twitter
consumer_key <- "votre_consumer_key"
consumer_secret <- "votre_consumer_secret"
access_token <- "votre_access_token"
access_secret <- "votre_access_secret"
setup_twitter_oauth(consumer_key,
consumer_secret,
access_token,
access_secret)
6 – Récupérer 50 tweets mentionnant le compte officiel d’Emmanuel Macron et les mettre sous forme de data frame :
list_macron <- searchTwitter("@EmmanuelMacron", n = 50)
df_macron <- twListToDF(list_macron)
Les 50 derniers tweets mentionnant Emmanuel Macron sont récupérés. En plus du tweet sous forme de texte, de nombreuses informations sont extraites, comme par exemple : la date de création du tweet, l’identifiant du tweet, le nombre de retweet, la source (iphone ou android) parfois la latitude et longitude, tweet favori etc…
Il est à noter que le nombre de tweet maximum qu’il est possible d’extraire avec une connexion est de n = 3000. De même, il y a une limite au nombre de connections à l’API de Twitter. De ce fait, cela a limité le nombre de tweets que j’ai pu récupérer durant la soirée de débat.
Pour pallier cette limite, j’ai appris après coup qu’il existe le package StreamR qui permet de laisser la connexion ouverte et donc de récupérer tous les tweets pendant toute la durée d’ouverture de la connexion
2. Le nombre de tweets par minute pour chaque candidat
Comme expliqué précédemment, la limite imposée de 3000 tweet par connexion ne m’a pas permis d’extraire en continu la totalité des tweets publiés pendant la soirée électorale. Il y a donc certaines plages horaires où aucun tweet n’a été récupéré (voir les deux graphiques suivants). Durant la soirée de débat 85197 tweets ont été récupéré mentionnant Marine Le Pen et 81546 mentionnant Emmanuel Macron. On constate des tendances similaires pour les deux candidats : le nombre de tweet par minute est au maximum en fin d’émission avec près de 1500 tweets par minute récupéré.
Pour afficher le nombre de tweet par minute, j’ai utilisé le code suivant pour les tweets d’Emmanuel Macron (le code est identique pour ceux mentionnant Marine Le Pen).
# Mettre la date de création du tweet sous forme POSIXct
df_macron$date <- format(df_macron$created, format="%Y-%m-%d")
df_macron$date <- as.POSIXct(df_macron$date)
# Histogramme du nombre de tweet par minute
# En changeant binwidth, il est possible de modifier la largeur de l’intervalle, ici 1 minute.
library(ggplot2)
minutes <- 60
ggplot(data=df_macron, aes(x=date)) +
geom_histogram(aes(fill=..count..),binwidth= 1*minutes) +
scale_x_datetime("Heure") +
scale_y_continuous("Nombre de tweets")


3. Les mots les plus fréquemment utilisés dans les tweets
En exploitant les plus de 80 000 tweets publiés pour chaque candidat, il est possible de construire des nuages de mots (wordcloud) en utilisant le package wordcloud.
Le code utilisé est le suivant :
# Mettre sous forme exploitable les tweets
df_macron$text <- gsub(","," ",df_macron$text) # Enlever les virgules
df_macron$text <- gsub("'"," ",df_macron$text) # Enlever les apostrophes
df_macron$text = gsub("(RT|via)((?:\\b\\W*@\\w+)+)", "", df_macron$text) # Enlever les mentions de retweet
df_macron$text = gsub("@\\w+", "", df_macron$text) # Enlever les @pseudo
df_macron$text <- gsub("http[^[:space:]]*", "", df_macron$text) # Enlever les liens
df_macron$text <- gsub("[^[:alpha:][:space:]]*", "", df_macron$text) # Enlever les nombres et la ponctuation
df_macron$text <- gsub("[ ]{2,}", " ", df_macron$text) # Enlever les espaces multiples
df_macron$text <- gsub("^\\s+|\\s+$", "", df_macron$text) # Enlever les espaces non-nécessaires
# Mettre le texte sous forme minuscule
tryToLower <- function(x){
y = NA
try_error = tryCatch(tolower(x), error = function(e) e)
if (!inherits(try_error, 'error'))
y = tolower(x)
return(y)
}
text_macron <- sapply(df_macron$text, tryToLower)
# Enlever les “mots vides” (exemple : le, la, du, etc…) + les noms des candidats
library(tm)
text_macron <- removeWords(text_macron,
c(stopwords("french"), stopwords("english"),
"est", “marine“, “le pen“, “emmanuel“, “debat“))
# Mettre les mots sous formes de tableau de données et enlever tous les mots qui n’apparaissent pas au moins dans 1% des tweets (sparsity = 0.99)
corpus_macron <- Corpus(VectorSource(text_macron))
dtm_macron <- DocumentTermMatrix(corpus_macron)
dtms_macron <- removeSparseTerms(dtm_macron, 0.99)
sparseData_macron <- as.data.frame(as.matrix(dtms_macron))
colnames(dtms_macron) <- make.names(colnames(dtms_macron))
# Construction du nuage de mots (wordcloud)
library(wordcloud)
wordcloud(colnames(sparseData_macron), colSums(sparseData_macron),
scale=c(2, 0.5), random.color=FALSE,
colors = c("#6BAED6", "#4292C6", "#2171B5", "#08519C", "#08306B"),
rot.per = 0.3) # pourcentage de mots écrits à la verticale



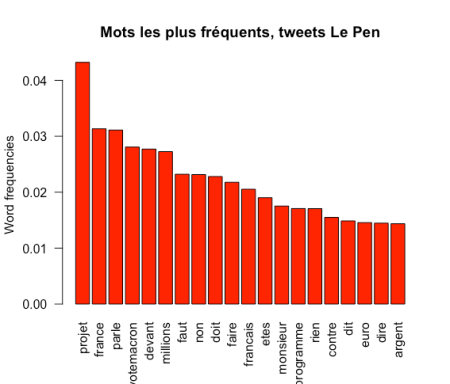
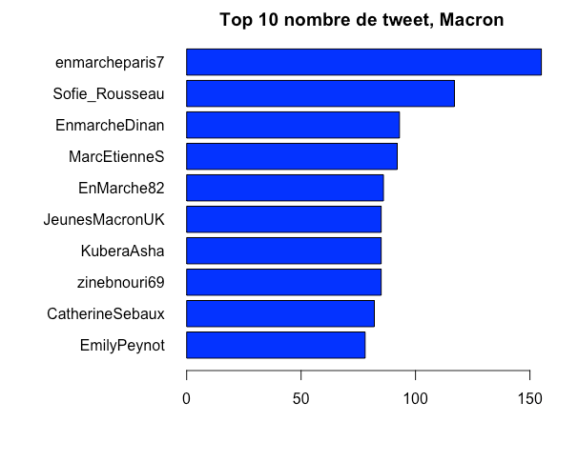
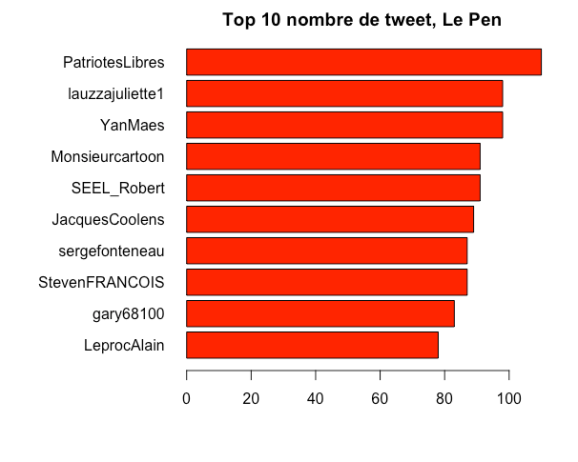
4. Les plus gros twittos de la soirée
Sans grande surprise, le compte « patriote libre » a le plus twitté avec plus de 100 tweets (ou retweets) durant le débat côté Marine Le Pen et « En marche Paris 7 » a quant à lui envoyé plus de 150 tweets.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.