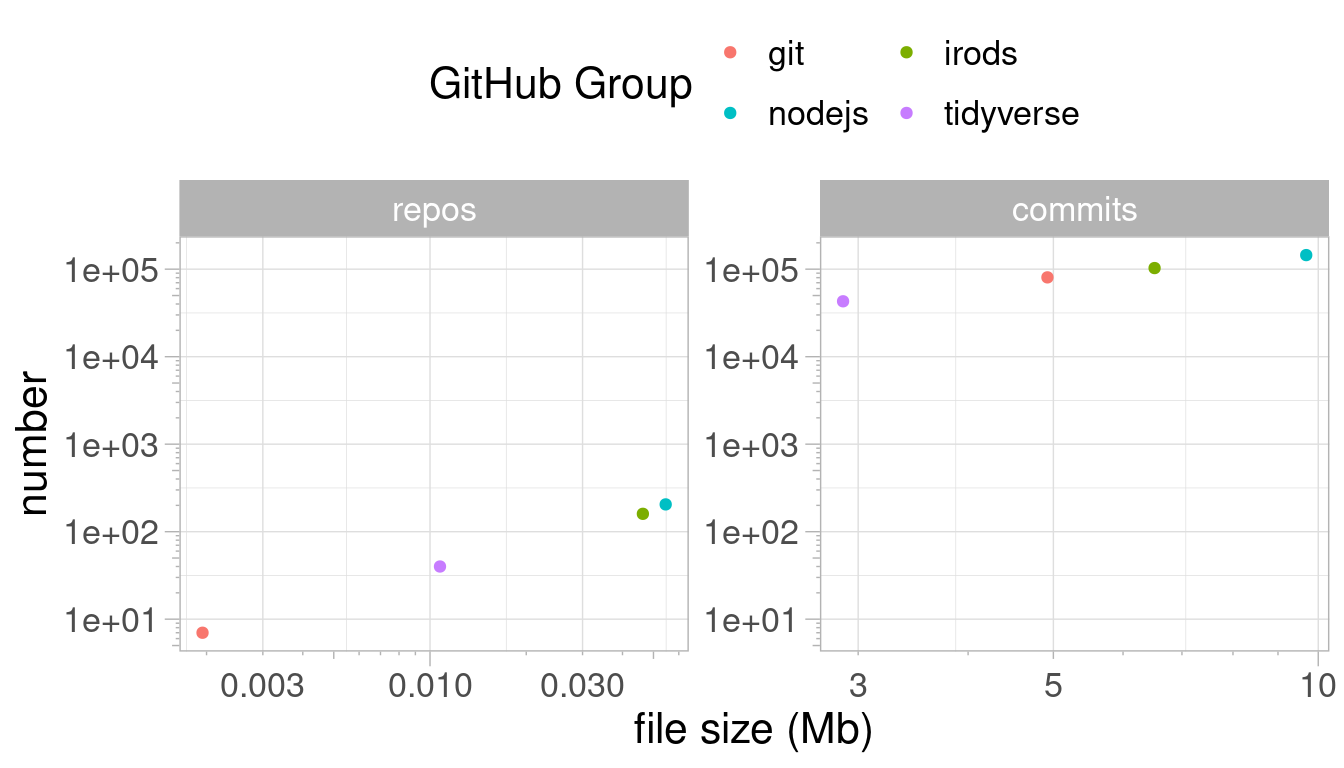
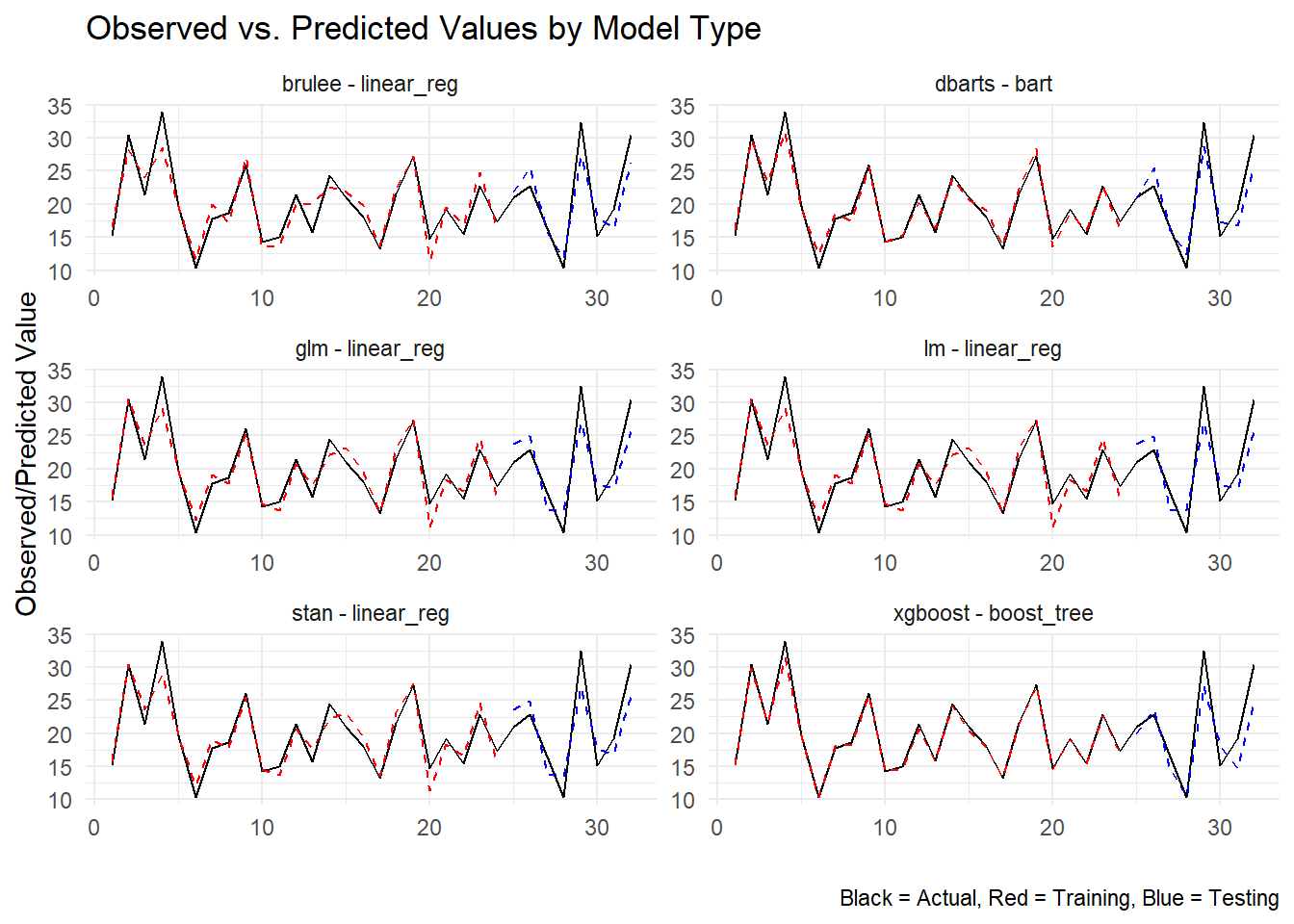
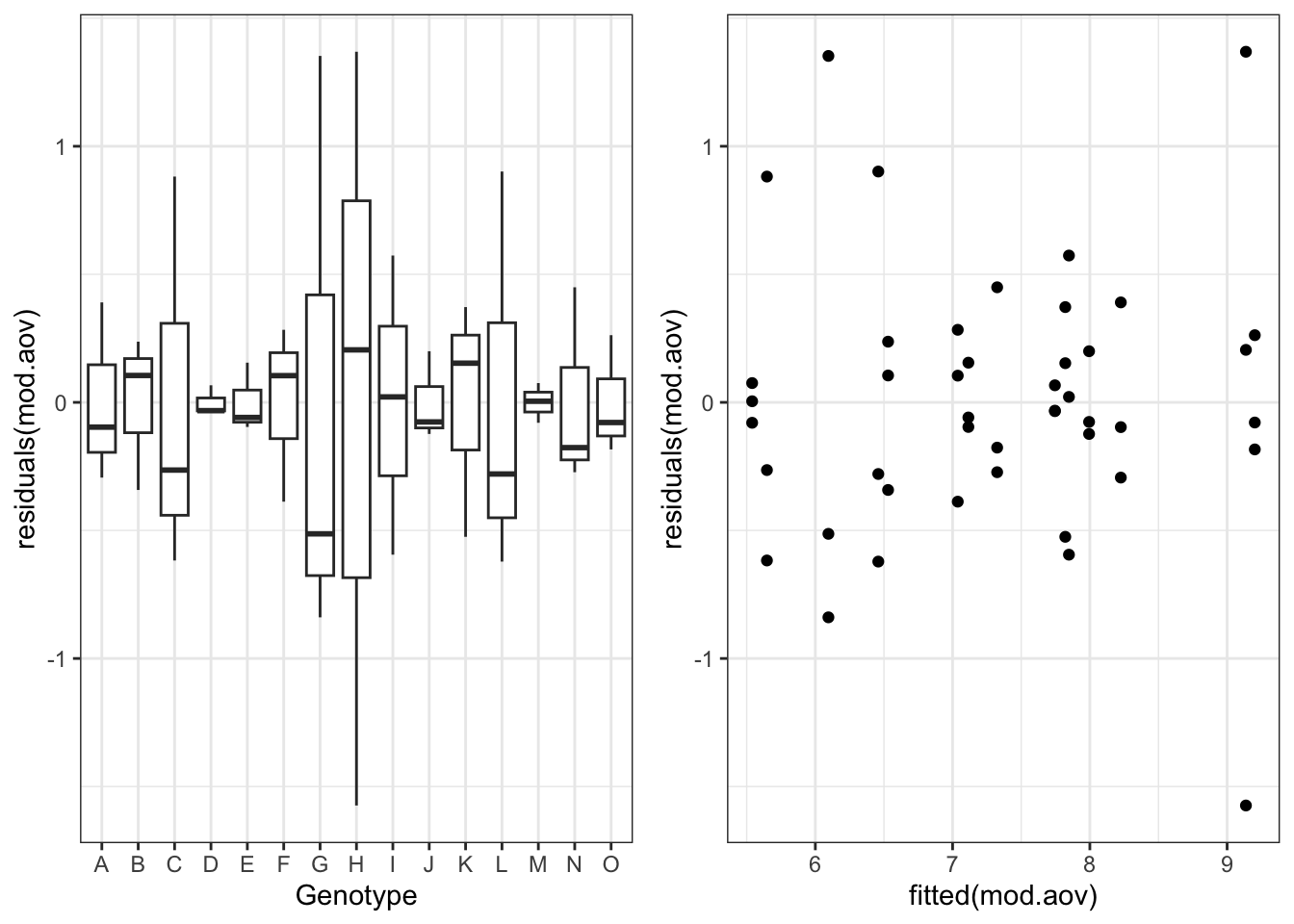
rOpenSci Champions Pilot Year: Projects Wrap-Up
Our first cohort of the rOpenSci Champions Program has now completed the second phase of the program by developing their project and carrying out outreach activities. In this article, we share each Champion’s project, their achievements and thei... [Read more...]